Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Watermarks, Tables, Event Time, and the Dataflow Model
The Google Dataflow team has done a fantastic job in evangelizing their model of handling time for stream processing. Their key observation is that in most cases you can’t globally order data arrival, which means that stream processing must handle out-of-order data.
The Dataflow model of computation has integrated a system for coping with this into the Beam API. This has been widely copied by different stream processing systems.
I think it’s important to differentiate two things:
- The observation that data can come out of order, and that the ability to revise results as new data arrives is important.
- A particular approach to resolving this based on triggers and watermarks.
Item (1) is exactly correct, but I think that while (2) is better than what came before, is still suboptimal and overly complex.
Here is what a typical computation using Watermarks looks like in the Beam API:
The meaning of a watermark is that it forces a final answer and discards any answer after that final answer.
I have three critiques of this API:
- It’s overly complicated.
- It mistakes an operational tuning parameter for business logic.
- It is a special case of a more general treatment of updatable data.
The first critique is fairly straight-forward. All this watermark business is complex, no denying that. There are at least 8 varieties of trigger and several types of watermark. If there was no better solution we’d accept that this was unavoidable complexity, but I think there is a better approach, which I’ll outline.
The second critique is that if we get specific about what we are trading off it is mostly non-functional characteristics and don’t really belong in your code at all but are more like tuning knobs.
The third critique requires outlining the more general thing this is a special case of. By way of doing that, let me introduce the concept of Tables in Kafka Streams API.
Tables and Materialized Views
When people think of streams of events they mostly think about immutable entities. Say that you record a stream of clicks. A click is a pure, immutable event. It will never be updated or changed.
However, much of the data in an organization is not in this form. Most organizations have at their core a set of entities maintained in mutable databases — this might hold their customer account information, their sales, their inventory, etc.
The task at hand for streaming apps isn’t processing only pure events, but combining it with data coming from these data stores. But most streaming processing systems don’t really represent tables of data.
Let’s say that I have a table of customer accounts and I want to compute the number of customers in each geographical region. One approach to doing this would be to just run this count once a day, but can I do it in a streaming fashion?
The answer is yes, there is a stream representation for a table like this. We wrote about it in the first blog on Kafka Streams API. I can take the stream of updates to accounts and use it to keep a running count of the current number of customers in each region. In other words, another representation for the evolution of a table over time is a stream of the updates to the table:
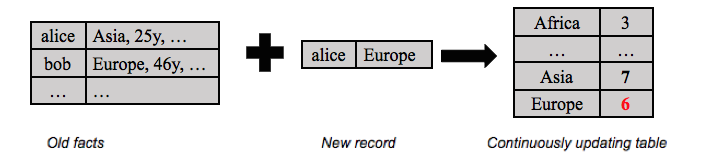
But note that the mechanics of this computation are quite different than computing, say, the count of clicks by each customer. The reason is that the count of clicks is never revised down — clicks arrive but old clicks never go away…so we only ever add to my count of clicks. On the other hand, an update event (e.g., “Alice moved to Europe”) is revising the location information for the customer. This means that to maintain the current count per region I need to subtract one from the count for the old region and add one to the count for the new region.
Clearly being able to compute both on pure streams (like clicks) as well as streams of revisions (like customer location) is important.
Tables and Windowing
Now that we’ve understood the streaming representation of a table we can understand how to generalize the dataflow model for handling windowed computation.
Rather than having a lot of special constructs for windowing, we can just say that a windowed computation is going to be a table. That is, it is a table where the key is the aggregation ID and the window time. This table will get updated as new events arrive.
Instead of thinking of getting a single answer for our windowed computation we need to think of getting a stream of revisions representing “the result so far”. So, if we are keeping a count of the number of customers in a time window, the count we are outputting always represents the “count so far” — future later data could arrive and revise this count. So the stream is a sequence of events that say something like “now the number of customers in Europe is 5”, “now the number of clicks for the customer in Europe is 9”, etc.
This is actually really cool — the same thing that let us do computations on changelogs we sucked out of existing databases also lets us model windowed computation. This is also important because it gives us semantics for processing the output of a windowed computation in a streaming job. If we treated the stream of windowed click counts as pure event streams and tried to sum them, we would get the wrong answer — clearly adding the previous “count so far” to the current “count so far” would make no sense.
Now as the Google folks have pointed out the retention of these windowed results will affect the results. We can only keep emitting updated counts as long as we retain the table of “counts so far”, but if we retain that forever we will need a continually growing amount of storage. This is a lot less of a problem in practice, though. Data can arrive hours, maybe even days late, but it isn’t going to be years late, and retaining old, cold results that mostly aren’t queried is pretty cheap.
Tables, Not Triggers
A practical consideration when emitting a stream of revisions is how frequently to emit them. For example in our example of counting customers in different regions, do you want to emit each individual increment (1, 2, 3, 4, …, 42, …) or only periodically emit the current value (say 1, 5, 9, 42, …). The key observation is that even though this changes your output it has absolutely no effect on the semantics of your program or anything computed off the output stream. The output stream is a stream of revisions in either case since later updates replace all previous updates.
Rather the frequency with which you emit output is trading off two non-functional parameters:
- Output volume: how much output you produce, and
- Update “lag”: how much latency you incur in seeing a current result.
If you wait longer to emit a result you can potentially suppress more duplicative outputs that will be revised later anyway; however, by doing this you incur latency.
The key point is that this trade-off between update lag and output volume is not specific to windows, it is general for any stream of revisions, including changelogs from databases, or materialized views computed by stream processors. Furthermore, it is purely an operational parameter, it doesn’t change the semantics of what your program computes.
I think this is the advantage of Kafka’s model for this: you get a single general concept of tables that cover all of these, and two simple tuning parameters that handle these cases and that can be toggled or configured at run-time based on the update lag and output volume you want. So in Kafka you’d have something like:
And then you can declaratively specify (a) the update lag requirement by specifying a commit interval config and (b) a record cache size config to bound the memory usage. For example, a user might specify that she is willing to tolerate an update lag of up to 100 milliseconds and can provide up to 10 MB of cache size to dedup/reduce the output volume:
props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 100 /* milliseconds */);
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10 * 1024 * 1024L);
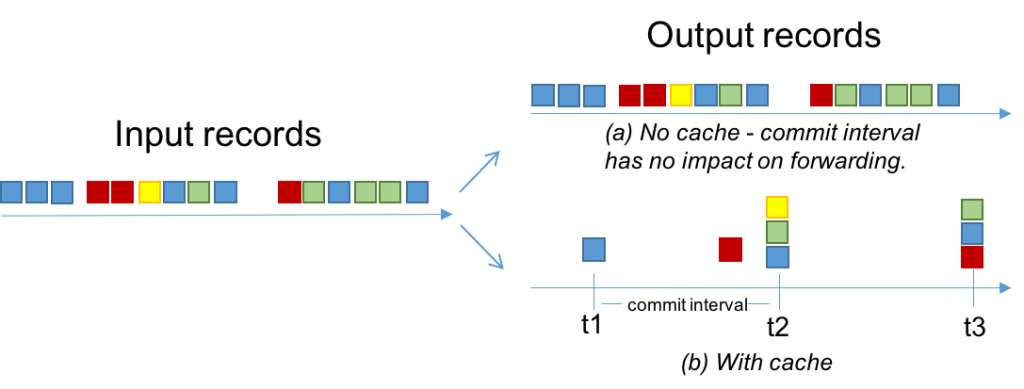
The illustration below shows the effect of these two configurations visually. For simplicity we have records with 4 keys: blue, red, yellow and green. Without loss of generality, let’s assume the cache has space for only 3 keys. When the cache is disabled, we observe that all the input records will be output, i.e., the lag is 0 but the volume of data can also be large. With the cache enabled, the lag is dictated by the commit interval and the output volume is close to halved (here: from 15 to 8 records).
One final thing to note is the “queryStoreName” parameter specified when defining the table. That’s part of Kafka’s model for Interactive Queries (see docs). Querying handles late arriving data quite naturally: at any point in time the user gets the latest result of the data seen so far. Any late arriving data is incorporated into the results returned from a subsequent query. That way you don’t have to define watermarks or triggers explicitly. You will always get the latest result, exactly when you need it. You can simply query the latest results on-demand:
What About Beam?
None of this is meant as a critique of Beam itself. The Beam API is an attempt at creating a universal wrapper over different stream processing engines, and this seems like a useful thing if it could be done since there are quite a lot of stream processing engines out there. If you could just learn some higher level API and ignore the system it ran on that would be quite nice. In the past, I’ve rarely seen these wrappers accomplish their goal of truly abstracting away the underlying system. Even ORMs struggle to really abstract SQL databases, and SQL databases are far more similar in their feature sets and implementation than the current crop of stream processing frameworks.
In practice, rather than really abstracting the underlying system, you end up having to understand the wrapper, how it uses (and misuses) the underlying infrastructure, and debug problems end-to-end through these layers.
That said if the API proves popular perhaps some of the layering issues can be resolved. We’d love to see an implementation for Kafka Streams API, and if Beam ends up becoming popular, we’ll probably implement it ourselves.
Try it out
If you are interested in further information on Apache Kafka, I’d recommend the following references:
- Kafka Streams API documentation in the Confluent Platform
- Register for the free online talk series to learn about all things Apache Kafka, stream processing and how to put these ideas into practice.
And if you want to get started implementing your own Kafka Streams API applications, you may want to:
- Download Confluent Platform, which includes Apache Kafka 0.10.2 with Kafka Streams API
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications
Last but not least, Confluent is hiring. If you liked what you read here and are interested in engineering the next-gen streaming platform, please contact us!
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.