Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Exploring ksqlDB with Twitter Data
When KSQL was released, my first blog post about it showed how to use KSQL with Twitter data. Two years later, its successor ksqlDB was born, which we announced this month. This time around, I’m going to revisit the same source of data but with ksqlDB 0.6.
A lot has been added since KSQL was first released back in 2017, including:
- Pull query support for directly querying the state store of an aggregate in ksqlDB
- Native integration with Kafka Connect connectors
- Support for nested structures
- Support for flattening an array into rows (EXPLODE)
- Better support for existing Apache Avro™️ schemas
- No more funky \ line continuation characters!
- Test runner
This is to name just a few. What back then was maybe a baby just starting to bum-shuffle around is now a toddler up and running around and finding its feet in the world of data processing and application development.
I’m going to show you how to use ksqlDB to do the following:
- Configure the live ingest of a stream of data from an external source (in this case, Twitter)
- Filter the stream for certain columns
- Create a new stream populated only by messages that match a given predicate
- Build aggregate materialised views, and use pull queries to directly fetch the state from these
Let’s dive in! As always, you’ll find the full test rig for trying this out yourself on GitHub.
Ingesting data into ksqlDB from a connector
ksqlDB can work with data in an existing Apache Kafka® topic, but it can also create and populate topics using connectors. That’s what we’re going to do here with the Twitter connector.
ksql> CREATE SOURCE CONNECTOR SOURCE_TWITTER_01 WITH ( 'connector.class' = 'com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector', 'twitter.oauth.accessToken' = '${file:/data/credentials.properties:TWITTER_ACCESSTOKEN}', 'twitter.oauth.consumerSecret' = '${file:/data/credentials.properties:TWITTER_CONSUMERSECRET}', 'twitter.oauth.consumerKey' = '${file:/data/credentials.properties:TWITTER_CONSUMERKEY}', 'twitter.oauth.accessTokenSecret' = '${file:/data/credentials.properties:TWITTER_ACCESSTOKENSECRET}', 'kafka.status.topic' = 'twitter_01', 'process.deletes' = false, 'filter.keywords' = 'devrel,apachekafka,confluentinc,ksqldb,kafkasummit,kafka connect,rmoff,tlberglund,gamussa,riferrei,nehanarkhede,jaykreps,junrao,gwenshap' );
Message ------------------------------------- Created connector SOURCE_TWITTER_01 ------------------------------------- ksql>
The credentials you need to supply can be obtained from Twitter and either be embedded in the connector configuration directly or—as I’ve done here—put in a file that is then used at runtime to embed the credentials securely.
With the connector created, we can check its status:
ksql> DESCRIBE CONNECTOR SOURCE_TWITTER_01;
Name : SOURCE_TWITTER_01 Class : com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector Type : source State : RUNNING WorkerId : kafka-connect-01:8083
Task ID | State | Error Trace --------------------------------- 0 | RUNNING | ---------------------------------
And we’ll see that in our list of available topics, a new one has been created, twitter_01:
ksql> SHOW TOPICS;
Kafka Topic | Partitions | Partition Replicas ------------------------------------------------------------------- _kafka-connect-group-01-configs | 1 | 1 _kafka-connect-group-01-offsets | 25 | 1 _kafka-connect-group-01-status | 5 | 1 _schemas | 1 | 1 default_ksql_processing_log | 1 | 1 twitter_01 | 1 | 1 -------------------------------------------------------------------
We can sample the messages from the topic to inspect it:
ksql> PRINT twitter_01 FROM BEGINNING LIMIT 1; Format:AVRO 12/5/19 10:13:46 AM UTC, ���ş���!, {"CreatedAt": 1575540819000, "Id": 1202531473485643776, "Text": "This is super cool!! Great work @houchens_kim!", "Source": "http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>", "Truncated": false, "InReplyToStatusId": -1, "InReplyToUserId": -1, "InReplyToScreenName": null, "GeoLocation": null, "Place": null, "Favorited": false, "Retweeted": false, "FavoriteCount": 0, "User": {"Id": 22950433, "Name": "Kevin King", "ScreenName": "MobileGist", "Location": "NYC", "Description": "Mobile Product Maven. Once ran 404 days in a row for @runningthree65, take the summers off from social media. I love streaks & am an @ARMYWP_Football fan.", "ContributorsEnabled": false, "ProfileImageURL": "http://pbs.twimg.com/profile_images/1181600534215704579/okYwyPrv_normal.jpg", "BiggerProfileImageURL": "http://pbs.twimg.com/profile_images/1181600534215704579/okYwyPrv_bigger.jpg", "MiniProfileImageURL": "http://pbs.twimg.com/profile_images/1181600534215704579/okYwyPrv_mini.jpg", "OriginalProfileImageURL": "http://pbs.twimg.com/profile_images/1181600534215704579/okYwyPrv.jpg", "ProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1181600534215704579/okYwyPrv_normal.jpg", "BiggerProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1181600534215704579/okYwyPrv_bigger.jpg", "MiniProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1181600534215704579/okYwyPrv_mini.jpg", "OriginalProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1181600534215704579/okYwyPrv.jpg", "DefaultProfileImage": false, "URL": null, "Protected": false, "FollowersCount": 432, "ProfileBackgroundColor": "FFFFFF", "ProfileTextColor": "8C94A2", "ProfileLinkColor": "8CB2BD", "ProfileSidebarFillColor": "424C55", "ProfileSidebarBorderColor": "FFFFFF", "ProfileUseBackgroundImage": true, "DefaultProfile": false, "ShowAllInlineMedia": false, "FriendsCount": 246, "CreatedAt": 1236275305000, "FavouritesCount": 2519, "UtcOffset": -1, "TimeZone": null, "ProfileBackgroundImageURL": "http://abs.twimg.com/images/themes/theme2/bg.gif", "ProfileBackgroundImageUrlHttps": "https://abs.twimg.com/images/themes/theme2/bg.gif", "ProfileBannerURL": "https://pbs.twimg.com/profile_banners/22950433/1571766063/web", "ProfileBannerRetinaURL": "https://pbs.twimg.com/profile_banners/22950433/1571766063/web_retina", "ProfileBannerIPadURL": "https://pbs.twimg.com/profile_banners/22950433/1571766063/ipad", "ProfileBannerIPadRetinaURL": "https://pbs.twimg.com/profile_banners/22950433/1571766063/ipad_retina", "ProfileBannerMobileURL": "https://pbs.twimg.com/profile_banners/22950433/1571766063/mobile", "ProfileBannerMobileRetinaURL": "https://pbs.twimg.com/profile_banners/22950433/1571766063/mobile_retina", "ProfileBackgroundTiled": false, "Lang": null, "StatusesCount": 4509, "GeoEnabled": true, "Verified": false, "Translator": false, "ListedCount": 30, "FollowRequestSent": false, "WithheldInCountries": []}, "Retweet": false, "Contributors": [], "RetweetCount": 0, "RetweetedByMe": false, "CurrentUserRetweetId": -1, "PossiblySensitive": false, "Lang": "en", "WithheldInCountries": [], "HashtagEntities": [], "UserMentionEntities": [{"Name": "Kim Houchens", "Id": 857023885761429504, "Text": "houchens_kim", "ScreenName": "houchens_kim", "Start": 32, "End": 45}], "MediaEntities": [], "SymbolEntities": [], "URLEntities": []}
Notice that ksqlDB detects the serialisation used (in this case Avro) and deserialises the message accordingly. ksqlDB supports data in JSON, Avro, and CSV (delimited).
If you want to see the unbounded stream, you can just remove the LIMIT clause from the PRINT statement and ksqlDB will show every message as it arrives until you press Ctrl-C.
Now we’ll declare a stream on top of the topic. A stream is just a Kafka topic with a schema—and we have the schema already because we’re using Avro, which makes this command nice and simple:
ksql> CREATE STREAM TWEETS WITH (KAFKA_TOPIC='twitter_01', VALUE_FORMAT='Avro');
Message ---------------- Stream created ----------------
If you have JSON or CSV data on your source topic, you just need to modify the above statement to include your schema definition, as shown in these examples.
Filtering columns with ksqlDB
With the stream created, we’re not restricted to only viewing the entire message (and the Twitter payload is not minimal!). We can pick out just the column of interest:
ksql> SELECT USER->SCREENNAME, TEXT FROM TWEETS EMIT CHANGES; +-------------------+------------------------------------------------------------------------------------------+ |USER__SCREENNAME |TEXT | +-------------------+------------------------------------------------------------------------------------------+ |MobileGist |This is super cool!! Great work @houchens_kim! | |Riaan428 |RT @Snapplify: Look out! Snapplify CEO is at @AWSreInvent in Las Vegas this week. �� Gre | | |at to be part of this innovative, engaged crowd, re… | |filrakowski |RT @dabit3: Look closely at this slide. https://t.co/CXZJt384ds | |Will_Taggart |Attending @AWSreInvent on Dec 2-6 in Las Vegas? Stop by our AI in Healthcare session & see| | | demos on Practical #Robotics, #Blockchain, 3D Insights & Collaboration, Automated #Trust,| | | & Conversational Intelligence at Booth #2416. https://t.co/RYekSbMAMN | |iamangelamolina |@xelfer @AWSreInvent @acloudguru oh I'm looking forward to this already! https://t.co/4iwp| | |BATC6u | […]
A few things to observe here:
- The USER entity is a nested object with SCREENNAME as a field within it, so we use -> to access it.
- This is a push query so it needs the EMIT CHANGES suffix. We’re essentially saying to ksqlDB that as the query result changes we want those incremental changes sent to us.
- If you run this for yourself, you’ll notice that the statement continues running since the data is unbounded. If you want to return to the ksqlDB prompt, you need to press Ctrl-C.
- If you want to read data from the beginning of the topic, rather than waiting for new messages to arrive, issue this command:
SET 'auto.offset.reset' = 'earliest';
Now comes the really useful bit—what if instead of a topic of multi-KB messages per tweet, we actually just want a topic with a handful of the fields in each message? Or perhaps we have a stream of source data with some fields of sensitive information that we cannot let another consumer see, but we still want the other consumer to be able to make use of the rest of the message. With ksqlDB, you can take an inbound stream and write to a new stream based on projections over the source. That could be something as simple as picking a few fields from the source and specifying them in the SELECT:
CREATE STREAM TWEETS_THIN AS SELECT ID, USER->SCREENNAME, TEXT FROM TWEETS EMIT CHANGES;
Now we have a new stream with a much more streamlined schema:
ksql> DESCRIBE TWEETS_THIN;
Name : TWEETS_THIN Field | Type ---------------------------------------------- ROWTIME | BIGINT (system) ROWKEY | VARCHAR(STRING) (system) ID | BIGINT USER__SCREENNAME | VARCHAR(STRING) TEXT | VARCHAR(STRING) ---------------------------------------------- For runtime statistics and query details run: DESCRIBE EXTENDED <Stream,Table>;
The stream is backed by a Kafka topic, which by default is named the same as the stream, but we could override that if we wanted.
ksql> PRINT TWEETS_THIN LIMIT 1; Format:AVRO 12/5/19 10:13:46 AM UTC, {"ID": 1202531473485643776, "USER__SCREENNAME": "MobileGist", "TEXT": "This is super cool!! Great work @houchens_kim!"} ksql>
Filtering a stream with ksqlDB
So far, we’ve just taken every message in the source stream and written that message but just a subset of the columns out to a new stream. You won’t always want to do this though. Perhaps you’ve got a “noisy” source with lots of data that you want to parse down to just the relevant messages. Imagine HTTP response codes on a website—a whole lot 200s, but it’s only the 400s and 500s we want to know about as they indicate an error. This is easily done with ksqlDB. Here, I’m goingn to do it based on whether a tweet was a retweet or not:
CREATE STREAM TWEETS_ORIGINAL AS SELECT * FROM TWEETS WHERE RETWEET=false;
CREATE STREAM RETWEETS AS SELECT * FROM TWEETS WHERE RETWEET=true;
Now we’ve got the source stream split into two new ones:
ksql> SHOW STREAMS;
Stream Name | Kafka Topic | Format ------------------------------------------------------------ TWEETS | twitter_01 | AVRO RETWEETS | RETWEETS | AVRO TWEETS_ORIGINAL | TWEETS_ORIGINAL | AVRO […] ------------------------------------------------------------
Both RETWEETS and TWEETS_ORIGINAL are populated with any messages matching the declared condition as they arrive. If you’ve set auto.offset.reset to earliest as mentioned above, then the streams will also have processed the existing messages on the source topic for any matching messages.
Dynamic predicates in ksqlDB
How about if we wanted to filter on something dynamic? A RETWEET is just a Boolean field, but maybe we want to take the source stream and arbitrarily route tweets from certain users to a new stream without having to recreate stream each time we change the users of interest.
To do this, we are going to introduce a new concept: the ksqlDB table. Whereas a stream is an unbounded series of events with a schema, a table is about state for a given key. To learn about this in more detail see this Kafka Summit talk. We’re going to build a table that contains our alert criterion. This is also a handy opportunity to show off another feature of ksqlDB, that of being able to populate a topic directly from the CLI itself.
CREATE TABLE ALERT_CRITERIA (LANGUAGE VARCHAR, CAPTURE_TWEETS BOOLEAN) WITH (KAFKA_TOPIC='ALERT_CRITERIA', VALUE_FORMAT='JSON', KEY='LANGUAGE', PARTITIONS=1);
Note that we’re using JSON here, simply because we can! I’ve specified the key, since a table needs a key (otherwise you can’t identify the value you want to retrieve). I could have actually omitted the LANGUAGE field from the schema and used ROWKEY alone but didn’t do that here for clarity.
Let’s load some data:
INSERT INTO ALERT_CRITERIA (LANGUAGE, CAPTURE_TWEETS) VALUES ('de', TRUE); INSERT INTO ALERT_CRITERIA (LANGUAGE, CAPTURE_TWEETS) VALUES ('jp', TRUE); INSERT INTO ALERT_CRITERIA (LANGUAGE, CAPTURE_TWEETS) VALUES ('es', FALSE);
As this data is being inserted into the topic, see how the system column exposing the message’s key (ROWKEY) matches the LANGUAGE column that we declared as the key.
ksql> PRINT ALERT_CRITERIA; Format:JSON {"ROWTIME":1575556129750,"ROWKEY":"de","LANGUAGE":"de","CAPTURE_TWEETS":true} {"ROWTIME":1575556129815,"ROWKEY":"jp","LANGUAGE":"jp","CAPTURE_TWEETS":true} {"ROWTIME":1575556129886,"ROWKEY":"es","LANGUAGE":"es","CAPTURE_TWEETS":false}
Now we can join to the inbound stream of tweets using standard SQL syntax:
CREATE STREAM TWEETS_ALERT AS SELECT T.* FROM TWEETS T INNER JOIN ALERT_CRITERIA A ON T.LANG = A.LANGUAGE WHERE A.CAPTURE_TWEETS = TRUE;
This gives us a new stream (and therefore topic) that is populated only with the tweets matching the criteria that we have specified. Let’s use some more ksqlDB functionality to validate that our new stream is correct by building a COUNT aggregate on top of it, which is broken down by LANG:
- Source stream:
ksql> SELECT LANG,COUNT(*) FROM TWEETS GROUP BY LANG EMIT CHANGES; +------+------------+ |LANG |KSQL_COL_1 | +------+------------+ |fi |2 | |de |1 | |ja |1 | |et |4 | |it |1 | |und |5 | |en |153 |
- Filtered stream:
ksql> SELECT T_LANG,COUNT(*) FROM TWEETS_ALERT GROUP BY T_LANG EMIT CHANGES; +-------+-----------+ |T_LANG |KSQL_COL_1 | +-------+-----------+ |de |1 |
Since we’re using an INNER JOIN to the table, we can even do without the CAPTURE_TWEETS field since a row’s presence in the table alone would be enough for the join to succeed. The point of including it is to show how flexible this can be: we can update the table by inserting a new value for a given key, which then overrides any previous value. So if we want to temporarily stop capturing German tweets, for example, we’d just do this:
INSERT INTO ALERT_CRITERIA (LANGUAGE, CAPTURE_TWEETS) VALUES ('de', FALSE);
The TWEETS_ALERT stream query is still running, but any new events arriving on the source TWEETS topic are going to be evaluated against the current value of CAPTURE_TWEETS for the given LANGUAGE.
Of course, changing values on a ksqlDB table doesn’t have to be done through an INSERT on the CLI (it’s just a handy way to demonstrate the concepts). In practice, any application can write changes to the topic underpinning the table and thus drive the predicates used in the streaming query populating TWEETS_ALERT.
Aggregates in ksqlDB
So far we’ve seen how ksqlDB can be used as a stream processing engine, taking data from one Kafka topic, transforming it in various ways, and writing it to a new Kafka topic. But what about the DB bit of the ksqlDB name? Well, that’s where pull queries come in.
Consider an application that’s processing a stream of tweets and wants to know how many times a given hashtag or user has been mentioned. Traditionally, this would involve writing the data to a datastore and performing the aggregation there:
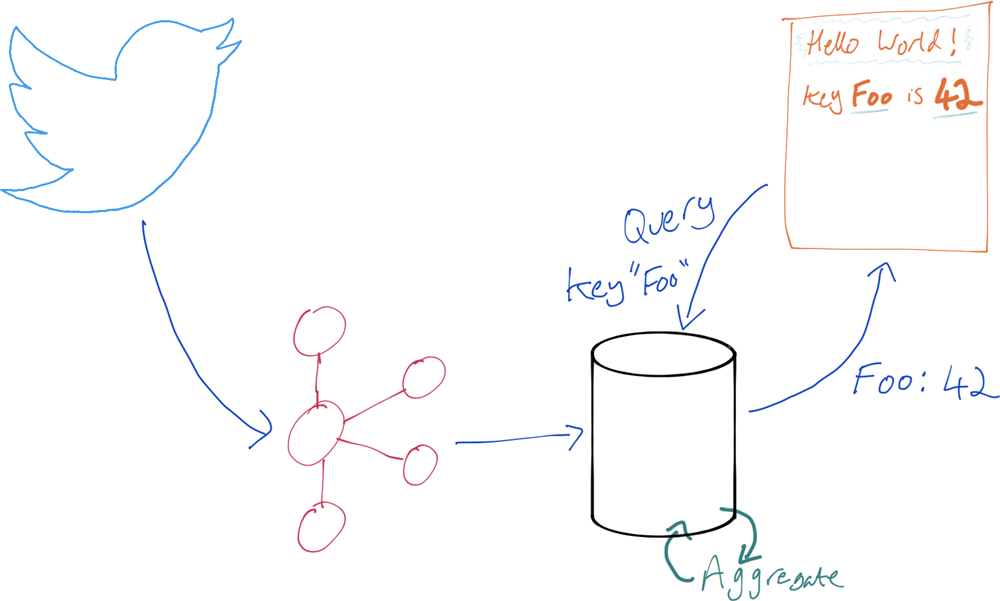
We can use ksqlDB to do this directly. It can build a stateful aggregation and make the state available directly to an application.
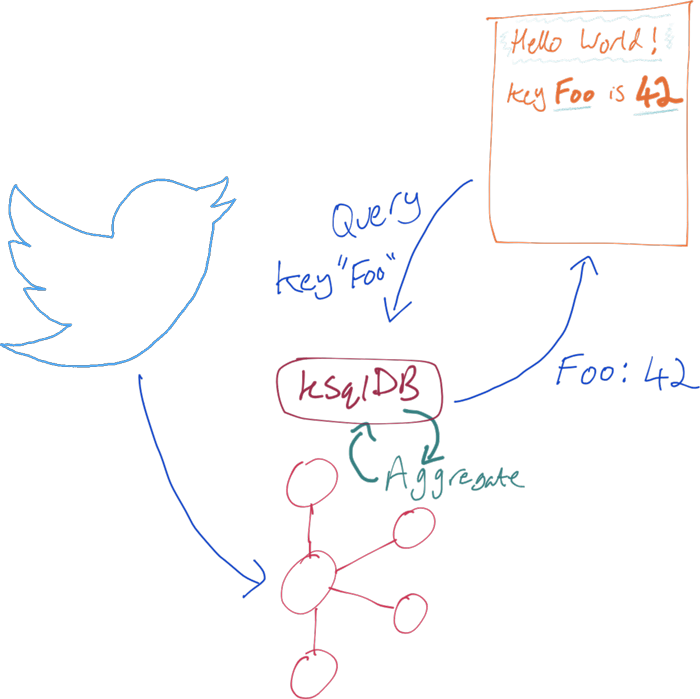
First up, the aggregation. We’re going to take advantage of the new EXPLODE function to take the array from the tweet of hashtags and/or users that have been mentioned in a tweet:
"HashtagEntities": [ { "Text": "Robotics", "Start": 110, "End": 119 }, { "Text": "Blockchain", "Start": 121, "End": 132 }, { "Text": "Trust", "Start": 173, "End": 179 } ], "UserMentionEntities": [ { "Name": "AWS re:Invent", "Id": 571241517, "Text": "AWSreInvent", "ScreenName": "AWSreInvent", "Start": 10, "End": 22 } ],
For each entity, we write a new message, meaning this row of hashtags from a single tweet:
ksql> SELECT ID, HASHTAGENTITIES FROM TWEETS WHERE ID =1202532395557089280 EMIT CHANGES; +--------------------+---------------------------------------------------------------------------------------------------------------+ |ID |HASHTAGENTITIES | +--------------------+---------------------------------------------------------------------------------------------------------------+ |1202532395557089280 |[{TEXT=Robotics, START=110, END=119}, {TEXT=Blockchain, START=121, END=132}, {TEXT=Trust, START=173, END=179}] |
…becomes this set of rows, one per array entry:
ksql> SELECT ID, EXPLODE(HASHTAGENTITIES)->TEXT AS HASHTAG FROM TWEETS WHERE ID =1202532395557089280 EMIT CHANGES; +--------------------+-----------+ |ID |HASHTAG | +--------------------+-----------+ |1202532395557089280 |Robotics | |1202532395557089280 |Blockchain | |1202532395557089280 |Trust |
So now, we create a stream of hashtags (converted to lowercase) and aggregate that stream:
CREATE STREAM HASHTAGS AS SELECT ID, LCASE(EXPLODE(HASHTAGENTITIES)-> TEXT) AS HASHTAG FROM TWEETS;
CREATE TABLE HASHTAG_COUNT AS SELECT HASHTAG, COUNT(*) AS CT FROM HASHTAGS GROUP BY HASHTAG;
Note that the second object we create is a table since it’s state (count) for a key (hashtag).
This table is maintained by ksqlDB and updated for any newly arriving hashtag. Here’s where it gets interesting. We can have the server send us a stream of changes to aggregates as they occur by using a push query:
ksql> SELECT HASHTAG, CT FROM HASHTAG_COUNT EMIT CHANGES; +----------------+------+ |HASHTAG |CT | +----------------+------+ |robotics |1 | |blockchain |1 | |trust |1 | |reinvent |95 | |stan |1 | |reinvent |96 | |winwithinstana |1 | |reinvent |97 | |cybersecurity |2 | […]
Note: reinvent appears several times since it’s a continuous query. Any time a new tweet arrives with a hashtag, the updated count is emitted. You have to cancel the query to return to the command prompt.
Here’s the really cool bit: we can query the state directly, with a pull query:
ksql> SELECT CT FROM HASHTAG_COUNT WHERE ROWKEY='reinvent'; +------+ |CT | +------+ |97 | Query terminated ksql>
The query returns once it’s finished (which is pretty much instantaneous), but it’s not a continuous query because it’s just pulling the state, and the state is just a given value. We can also run this same pull query against ksqlDB’s REST API, which means that any application can query the state:
$ time curl -s -X POST \
http://localhost:8088/query \
-H 'content-type: application/vnd.ksql.v1+json; charset=utf-8' \
-d '{"ksql":"SELECT CT FROM HASHTAG_COUNT WHERE ROWKEY=\u0027reinvent\u0027;"}' |
jq '.[] | select(.row!=null).row.columns'
0.03 real 0.00 user 0.00 sys
[
97
]
If we want to receive the state as it changes over time, then we can run a push query to have state changes pushed to us.
Wax on, wax off: Streams in, streams out
Just as we created an inbound connector to stream the data in from Twitter, we can also create connectors to stream data out to other destinations. As we just saw above, it could be that we don’t even need to write the data anywhere else. If we just want to query state in place, we can do that directly from ksqlDB. For ad hoc analytics, search, or specialised data access patterns such as property graph analysis, among other purposes, we may want to transform the data in ksqlDB and then route it to a more appropriate place for working with it.
Streaming messages from ksqlDB to a database
Let’s start with a simple example. We’re streaming data from a source (Twitter in this case), we’ve processed it (filtered out retweets), and now we want this information in a database. To do this, we simply create a sink connector:
ksql> CREATE SINK CONNECTOR SINK_POSTGRES_TWEETS_THIN WITH ( 'connector.class' = 'io.confluent.connect.jdbc.JdbcSinkConnector', 'connection.url' = 'jdbc:postgresql://postgres:5432/', 'connection.user' = 'postgres', 'connection.password' = 'postgres', 'topics' = 'TWEETS_THIN', 'key.converter' = 'org.apache.kafka.connect.storage.StringConverter', 'auto.create' = 'true' );
Message --------------------------------------------- Created connector SINK_POSTGRES_TWEETS_THIN ---------------------------------------------
The connector automagically creates the target object:
postgres=# \d "TWEETS_THIN" Table "public.TWEETS_THIN" Column | Type | Collation | Nullable | Default ------------------+--------+-----------+----------+--------- USER__SCREENNAME | text | | | TEXT | text | | | ID | bigint | | |
It continually populates:
postgres=# SELECT* FROM "TWEETS_THIN" FETCH FIRST 5 ROWS ONLY; USER__SCREENNAME | TEXT | ID ------------------+-----------------------------------------------------------------------------------------+--------------------- MobileGist | This is super cool!! Great work @houchens_kim! | 1202531473485643776 Riaan428 | RT @Snapplify: Look out! Snapplify CEO is at @AWSreInvent in Las Vegas this week. �� Gr | 1202531595023990784 filrakowski | RT @dabit3: Look closely at this slide. https://t.co/CXZJt384ds | 1202531602468872197 Will_Taggart | Attending @AWSreInvent on Dec 2-6 in Las Vegas? Stop by our AI in Healthcare session & | 1202532395557089280 iamangelamolina | @xelfer @AWSreInvent @acloudguru oh I'm looking forward to this already! https://t.co/4 | 1202532799988633600 (5 rows)
What about the aggregates that we built above? We can query them directly from an application, but maybe we also want to persist them to a database too. However, unlike a stream (which is append only and thus comparable to INSERTs to a RDBMS table), aggregates are stored in a ksqlDB table.
In a ksqlDB table, the key has a value that updates, and we will need to update the value in the database too. Fortunately, the database connector supports this by using UPSERTs ('insert.mode' = 'upsert') against a key that we declare from the payload ('pk.mode' = 'record_value', 'pk.fields' = 'HASHTAG'). By default, the connector will add all the columns available, including the system fields ROWTIME and ROWKEY. We use a feature of Kafka Connect called Single Message Transforms (SMTs) to remove these keys from the payload as the message is routed to the database.
CREATE SINK CONNECTOR SINK_POSTGRES_HASHTAG_COUNT WITH ( 'connector.class' = 'io.confluent.connect.jdbc.JdbcSinkConnector', 'connection.url' = 'jdbc:postgresql://postgres:5432/', 'connection.user' = 'postgres', 'connection.password' = 'postgres', 'topics' = 'HASHTAG_COUNT', 'key.converter' = 'org.apache.kafka.connect.storage.StringConverter', 'auto.create' = 'true', 'insert.mode' = 'upsert', 'pk.mode' = 'record_value', 'pk.fields' = 'HASHTAG', 'transforms' = 'dropSysCols', 'transforms.dropSysCols.type' = 'org.apache.kafka.connect.transforms.ReplaceField$Value', 'transforms.dropSysCols.blacklist' = 'ROWKEY,ROWTIME' );
In the database, the aggregate values are updated in place as the aggregates are recalculated by ksqlDB:
postgres=# SELECT * FROM "HASHTAG_COUNT" ORDER BY "CT" DESC FETCH FIRST 5 ROWS ONLY; HASHTAG | CT --------------+----- reInvent | 202 awsreinvent | 124 AWS | 119 reinvent | 79 reInvent2019 | 46 (5 rows)
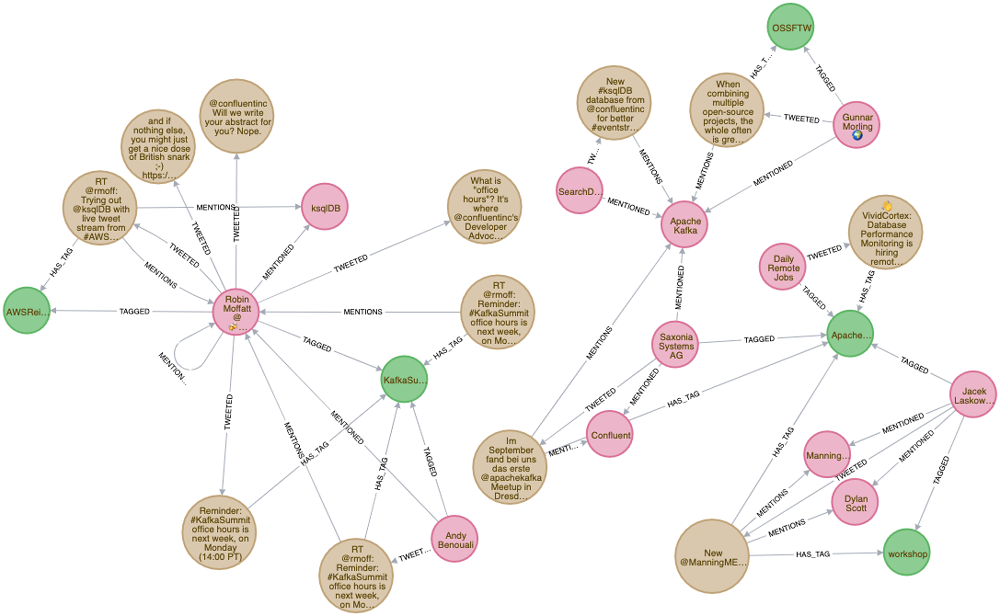
Streaming messages from ksqlDB to Neo4j
Sometimes a relational database just doesn’t quite cut it. But you’ve got the kind of dataset that lends itself well to property graph analysis, so what do you do? You stream it from ksqlDB to a dedicated graph database, such as Neo4j:
CREATE SINK CONNECTOR SINK_NEO4J WITH ( 'connector.class' = 'streams.kafka.connect.sink.Neo4jSinkConnector', 'topics' = 'twitter_01', 'neo4j.server.uri' = 'bolt://neo4j:7687', 'neo4j.authentication.basic.username' = 'neo4j', 'neo4j.authentication.basic.password' = 'connect', 'neo4j.topic.cypher.twitter_01' = 'MERGE (u:User{ID: event.User.Id}) ON CREATE SET u.Name = event.User.Name, u.ScreenName = event.User.ScreenName SET u.Location = event.Location, u.FollowersCount = event.User.FollowersCount, u.StatusesCount = event.User.StatusesCount MERGE (t:Tweet{ID: event.Id}) ON CREATE SET t.Text = event.Text, t.retweet = event.Retweet MERGE (u)-[:TWEETED]->(t) WITH event.HashtagEntities AS hashTags, t, u, event UNWIND hashTags AS hashTag MERGE (h:Hashtag{text: hashTag.Text}) MERGE (t)-[:HAS_TAG]->(h) MERGE (u)-[:TAGGED]->(h) WITH event.UserMentionEntities AS userMentions, t, u UNWIND userMentions AS userMention MERGE (um:User{ID: userMention.Id}) ON CREATE SET um.Name = userMention.Name, um.ScreenName = userMention.ScreenName MERGE (t)-[:MENTIONS]->(um) MERGE (u)-[:MENTIONED]->(um)' );
This connector’s a bit more complicated than the JDBC/PostgreSQL one above, because we’re using Cypher to describe how to model the data and the relationships within it. My thanks to Andrea Santurbano for his help with the code! With the data streaming into Neo4j, we can now visualise it in a very easy way:
Conclusion
In this article we’ve seen how you can use ksqlDB to ingest data from virtually any source and process it to create new streams of data, including filtering it for specific messages that match a predicate. We also built aggregations against the data, explored the huge value of being able to query that aggregate state directly, and saw how ksqlDB can push data directly out to datastores such as an RDBMS and Neo4j.
Whether you want to build a stream processing pipeline or take a stream of data and make its state available to an application directly, ksqlDB is for you! Ready to check ksqlDB out? Head over to ksqldb.io to get started. Follow the quick start, read the docs, and check out the project on Twitter!
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.