Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
From the Cellar to the Cloud – How Aedifion is Driving Next-Generation Building Automation with Confluent
It is no exaggeration that a lot is going wrong in commercial buildings today. The building and construction sector consumes 36% of global final energy and accounts for almost 40% of global energy-related CO2 emissions1. Worse, many of those buildings deliver only poor indoor air quality and thermal comfort, affecting the health and cognitive performance of occupants2.
It is also no exaggeration that we could do a lot better. Case studies show that primary energy consumption can be reduced by roughly 35% while even improving user comfort at the same time3—yes, it’s a win-win. Further, these studies show that we don’t even need new walls, insulation, or hardware to realize this potential—we just need to optimize building operations using the digital Building Automation Systems (BASs) that are already available in most commercial buildings today.
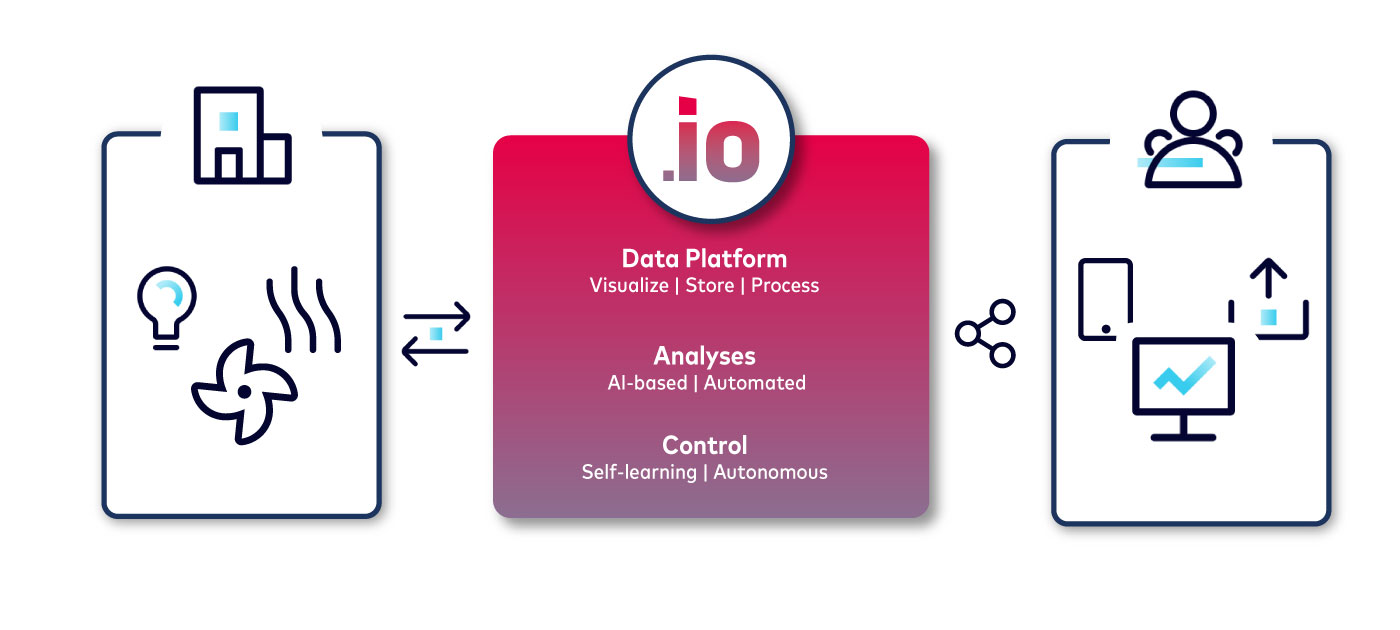
Figure 1: High-level overview of data-driven products for monitoring, analytics, and control of commercial buildings.
Facing these challenges, aedifion drives the decarbonization of the built world with digital, data-driven monitoring, analytics and controls products that enable stakeholders across the board to operate buildings better and meet their Environmental, Social, and Corporate Governance (ESG) goals. To this end, we collected and incorporated feedback from building operators, facility management, service technicians, and, last but not least, from the occupants.
Too abstract? Don’t worry, we’ve got some numbers: In a recent case study, aedifion shows that significant reductions are possible even in newly constructed buildings such as the Kaiser Hof Cologne, a 12,000 square meters prestige office complex built in 2019. In this project, 149 devices and 14,798 datapoints were automatically discovered on the BAS and semi-automatically mapped onto 359 digital micro twins for which 744 analyses were run periodically each week. Our analytics informed us about everything from malfunctioning devices to optimization potentials and were automatically condensed, prioritized, and complemented by concrete recommendations for action. Putting them into practice, the Kaiser Hof building operation not only achieved impressive energy and CO2 savings already during the first optimization cycle but improved indoor climate and tenant comfort at the same time (Fig. 2).

Figure 2: Significant reductions achieved in the Kaiser Hof Cologne.
Source: Kaiser Hof | Köln Case Study
The prerequisites for aedifion’s products are twofold: secure connectivity and reliable data collection. In this article, we take a closer look at how Confluent Cloud helps aedifion realize these goals at scale—how Confluent helps aedifion to do better. To understand why we chose Confluent Cloud as the centerpiece for our data pipeline, let’s take a look at our requirements.
Understanding the requirements
It is important to understand that there is no typical commercial building and no one-size-fits-all solution. aedifion’s products are used in small and large office buildings, energy plants, trade fair halls, shopping centers, and according to SmartScore, the smartest building in the world: the Hammerbrooklyn in Hamburg. Their buildings can have anything from a few thousand datapoints (in a small office building) up to hundreds of thousands of datapoints (in exhibition and conference halls, airports), e.g., sensors, actuators, operation status, setpoints, and so forth. With the variety of sources comes a variety of requirements for the data pipeline, among which the following are the most important to our use cases:
- Scalability: Depending on the required temporal resolution of the collected data, throughput can reach anything from tens to thousands of messages per second per building. Similarly, a roll-out may include only one to hundreds of buildings. The data pipeline should thus scale elastically in both the number of messages per building and in the number of buildings.
- Security: Security is of the highest priority since tampering with collected data, or worse, with control signals issued to the BAS can cause damage to buildings and injury to persons. Hence, the data pipeline must afford confidentiality, integrity, and authenticity of all exchanged data and facilitate fine-grained access control.
- Availability: Mission-critical functionality, such as alerting and controls, requires that collected data is always up-to-date and that even under high load, downtimes are minimal and do not cause data loss.
- Replayability: The ability to replay collected data simplifies, e.g., development of streaming analytics, errors recovery, or reproducible stress testing.
It goes without saying that this minimal list of requirements only scratches the surface. Additional requirements, depending on the needs of the customer, include integrations, ease of client development, on-premise deployment, schema management, observability, operational costs, adoption, community, and support.
Scouting solutions
It quickly became clear that we needed some kind of asynchronous messaging system to fulfill the sketched-out requirements for our data pipeline. That was the easy part—the hard part was choosing one.
Due to looming customer on-premise requirements and a healthy paranoia of vendor lock-in, we concentrated on open source messaging protocols with open source implementations, shortlisting MQTT, Kafka, AMQP, and NATS. After a thorough qualitative and quantitative evaluation of our options, we chose Apache Kafka® as our messaging system of choice due to its superior delivery guarantees, performance, and adoption.
We were also looking for a managed service to keep operational and maintenance overhead to a minimum. Among the offerings evaluated from different competitors, we finally chose Confluent Cloud due to:
- Pricing: Confluent Cloud offers a true pay-per-use pricing model that perfectly matches our elastic scalability requirements.
- Integrations: The selection of (managed) connectors, e.g., for Postgres, MQTT, and Salesforce, allow us to quickly evolve our data pipeline into a general data and event backbone for the whole backend.
- Simplicity: Confluent Cloud offers simple and intuitive APIs that integrate well into our existing DevOps processes.
- Schema management: We collect different types of data from buildings, e.g., sensor/actuator time series data, metadata, alarms, and control messages. All of these have different formats that we can easily manage in Confluent’s Schema Registry.
- On premise: While we love Confluent Cloud for the above-mentioned reasons, it is good to know that we can download and install Confluent Platform and have the same functionality on-premises when our customers demand it.
Setting it up
Figure 3 illustrates several different scenarios of our ingress and egress pipeline. Customers receive our Edge Device and connect it to their building automation network. The Edge Device is pre-configured for the customer, integrates all major automation protocols, automatically discovers available devices and their datapoints, and periodically collects sensor/actuator data, metadata, operation messages, and alarms—making installation and commissioning truly plug-and-play.
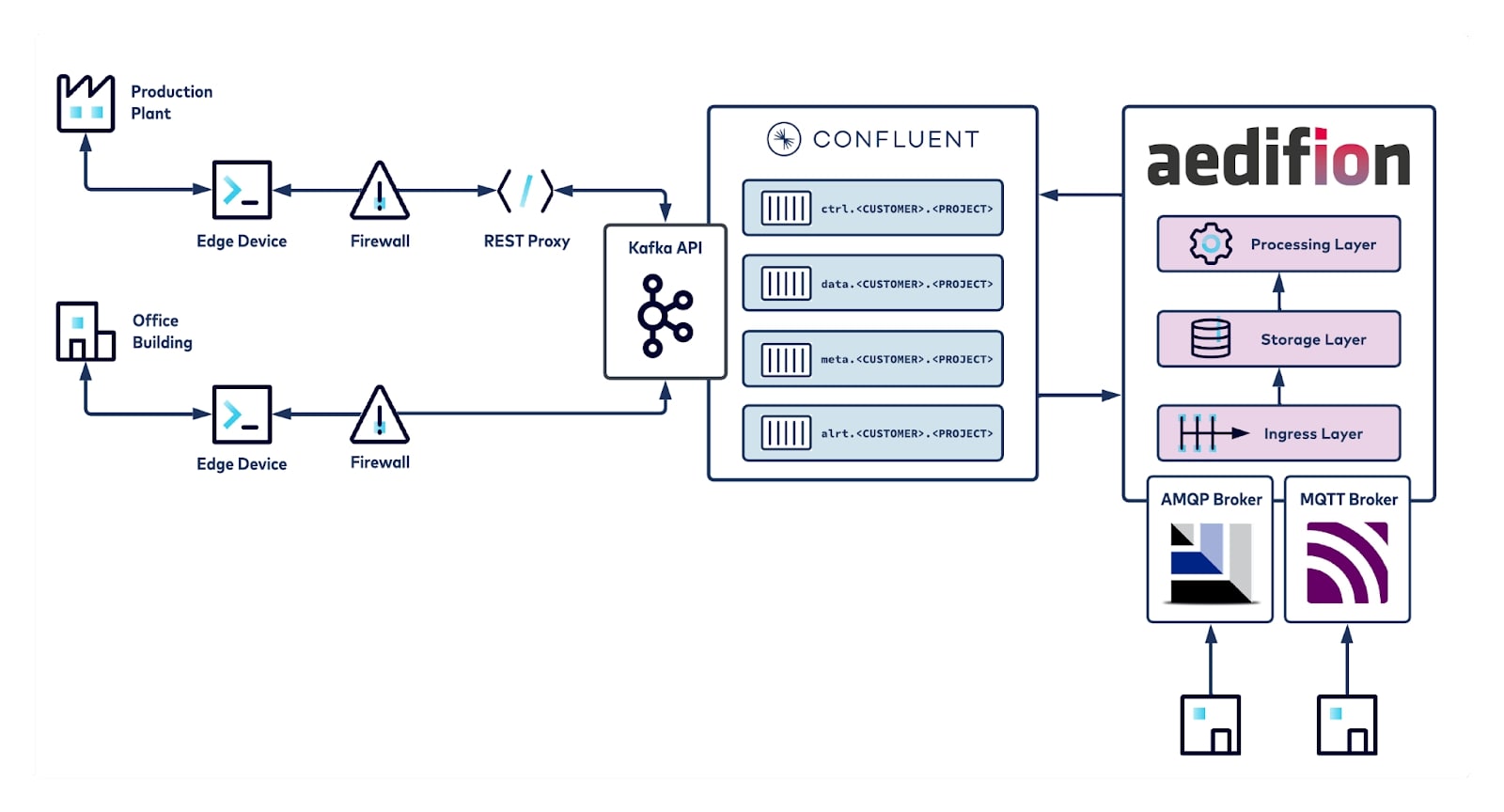
Figure 3: Kafka-based data pipeline at aedifion.
Collected data is published via Kafka to our clusters on Confluent Cloud (Fig. 3, bottom left). In some cases, a customer’s restrictive firewall policy only allows HTTP traffic, so we use the Confluent REST Proxy (Fig. 3, top left). Collected data is published into topics that follow a strict naming schema containing the data type and unique handles for customer and project (Fig 3., center). This serves multiple purposes: topic-level access control on the edge, auto-configuration and load balancing in the ingress layer, separation of tenants, and strict schema management along the whole pipeline.
Our ingress layer (Figure 3, right) runs multiple sets of self-built stateless connectors per data type that consume from Kafka and ingest into the storage layer, composed of both SQL and NoSQL databases. All our connectors support regex topic string subscriptions, e.g. alrt\.* or data\.aedifion\.*, so that we can, for example, allocate one consumer group per customer and scale painlessly through replication.
Our experience so far
We have so far migrated 30 buildings to our new Kafka-based Confluent Cloud-powered data pipeline. Practical experiences have been great so far and we see huge advantages over our now deprecated MQTT-based pipeline:
- We haven’t had any Confluent Cloud downtime—uptime is beyond the 99.5% advertised for basic clusters.
- Kafka serves as a reliable buffer between producers (our Edge Devices) and consumers (backend microservices) smoothing over bursts and temporary application downtimes.
- Development and quality of our internal (micro)services have significantly accelerated, since we can now depend on Kafka’s superior delivery guarantees and replay capabilities.
- Besides a thin layer of configuration and automation written in Ansible, we had zero operational and maintenance overheads with regard to Confluent Cloud.
Migrating more and more projects to the new data pipeline, we have also hit a minor hurdle: Sometimes, we deal with automation hardware that natively supports MQTT, but we haven’t seen any automation hardware supporting Kafka, yet. In these cases, we still instruct our customers to publish directly to aedifion’s own MQTT broker (Figure 3, bottom right) while we’re eagerly waiting for Confluent’s MQTT Proxy to become natively available on Confluent Cloud.
Quo vadis
The common goal of all of aedifion’s products is to contribute to the decarbonization of the built world by realizing optimization potentials in building operations automatically and at scale. In 2022, aedifion is looking forward to multiple roll-outs across fleets of a few hundred buildings each. With Kafka and Confluent, we not only feel well prepared for this challenge but are also already making plans to scale to thousands of buildings.
Meanwhile, we are planning to establish Confluent as the central data and event backbone in our microservice architecture, extending it to even more types of data and events such as logging and auditing, tracking user interactions, and running virtual datapoints (e.g., computing the average over multiple physical temperature sensors and emitting the result as a new datapoint). Confluent Cloud allows us to worry less about setting up and operating the required infrastructure and lets developers concentrate on adding value to our products instead.
Finally, we note that sustainable building management is an inherently continuous process and that success is closely tied to the efficient use of data. This data is collected from a live and dynamic world where seasons, residents, and policies regularly change.
Confluent is founded on the concept of data in motion, allowing us to consolidate our batch and real-time data pipelines into a single pipeline, fully embracing the constant change in our data.
References
[1] Abergel, Thibaut and Dean, Brian and Dulac, John: Towards a zero-emission, efficient, and resilient buildings and construction sector: Global Status Report 2017; UN Environment and International Energy Agency: Paris, France, 2017.
[2] Wang, Chao and Zhang, Fan and Wang, Julian and Doyle, James and Hancock, Peter and Mak, Cheuk Ming and Liu, Shichao: How indoor environmental quality affects occupants’ cognitive functions: A systematic review; Building and Environment, 2021.
[3] King, Jennifer and Perry, Christopher: Smart buildings: Using smart technology to save energy in existing buildings; American Council for an Energy-Efficient Economy, 2017.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



How to Implement Your First ML Function in Streaming
Learn how to add your first ML model to a real-time streaming pipeline. Learn a simple, low-risk pattern for inference, scoring, and deployment with Apache Kafka®.



Sustainable Streaming Architectures: A GreenOps Guide to Efficient, Low-Carbon Data Systems
Design energy-efficient, low-cost streaming systems. Learn GreenOps patterns to reduce compute waste, optimize storage, and lower the carbon footprint of real-time data.