Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Simplifying Apache Kafka Multi-Cluster Management Using Control Center and Cluster Registry
Most companies who have adopted event streaming are running multiple Apache Kafka® environments. For example, they may use different Kafka clusters for testing vs. production or for different use cases. Self-managing multiple Kafka clusters, however, can pose a challenge to system administrators.
To help Kafka administrators, we introduced the Cluster Registry in Confluent Platform 6.0, through which you can centrally register Kafka clusters in the Confluent Platform Metadata Service (MDS). MDS manages important information, such as authorization data about Confluent Platform environments, as we will explain in more detail below.
Confluent Platform also comes packaged with Confluent Control Center to manage and monitor multiple Kafka clusters. Often the set of clusters managed by Control Center is the same as the set registered with Cluster Registry in MDS. Because Cluster Registry and Control Center are essentially storing the same information, this leads to the following drawbacks:
- Duplicate work: User must register Kafka clusters in both tools
- Error prone: Different places mean that cluster name could very well end up being different for the same cluster
In Confluent Platform 6.0.1, we have added support in Control Center for reading the cluster information from Cluster Registry to avoid the above pitfalls.
What is Control Center?
Confluent Control Center is a web-based tool for managing and monitoring Apache Kafka as well as Confluent software components, such as Kafka connectors, Schema Registry, and ksqlDB. Control Center provides a user interface that allows developers and operators to get a quick overview of cluster health; to observe and control messages, topics, and Schema Registry; and to develop and run ksqlDB queries.
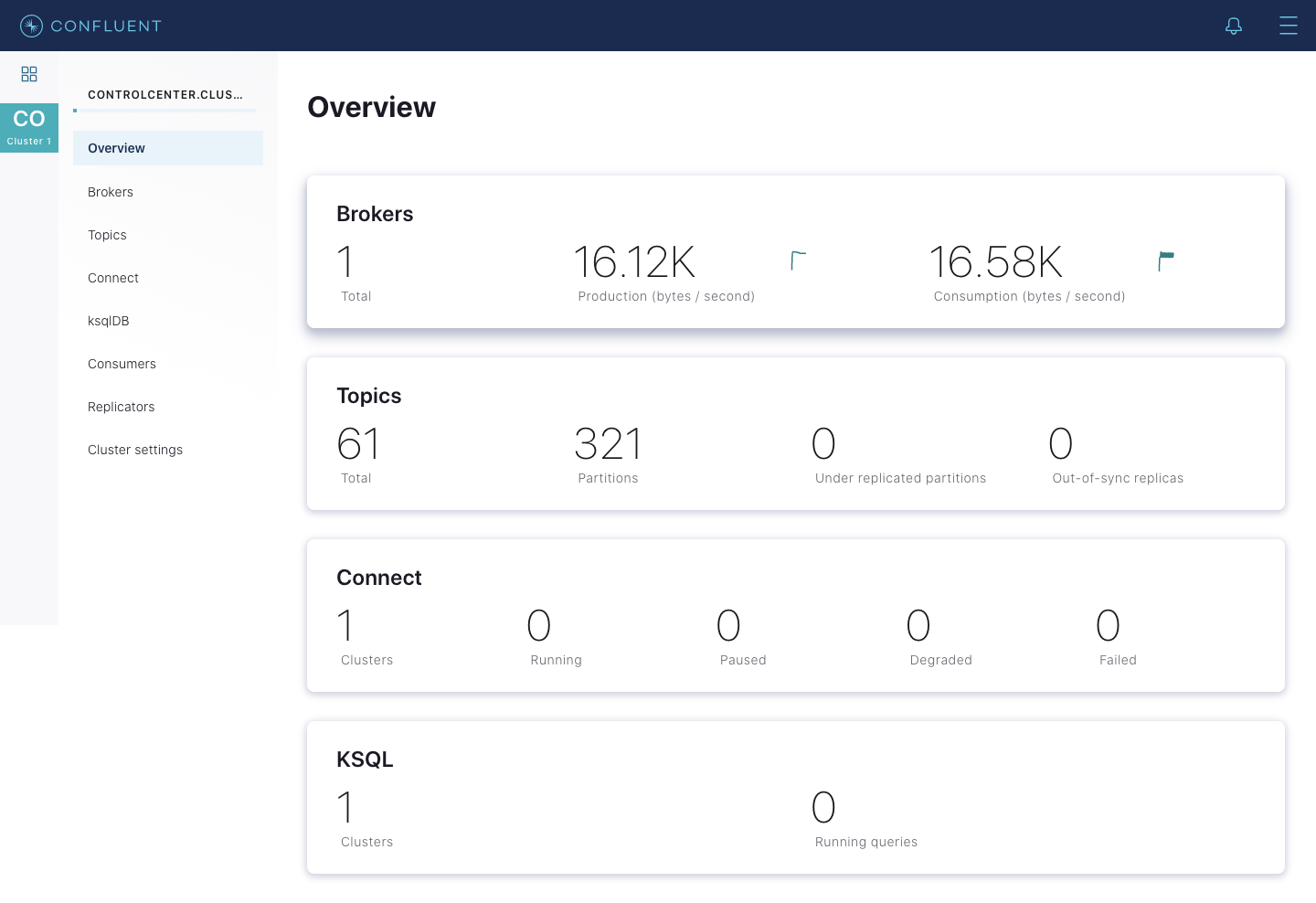
Manage and monitor multiple clusters
You can use Control Center to manage and monitor not just one but multiple Kafka clusters. To do so, each Kafka cluster must be specified in the Control Center configuration file. In the example below, we specify a cluster named lon-prod for our London production traffic:
confluent.controlcenter.kafka.lon-prod.bootstrap.servers=localhost:9192
The above cluster in turn will appear in Control Center UI as shown below:
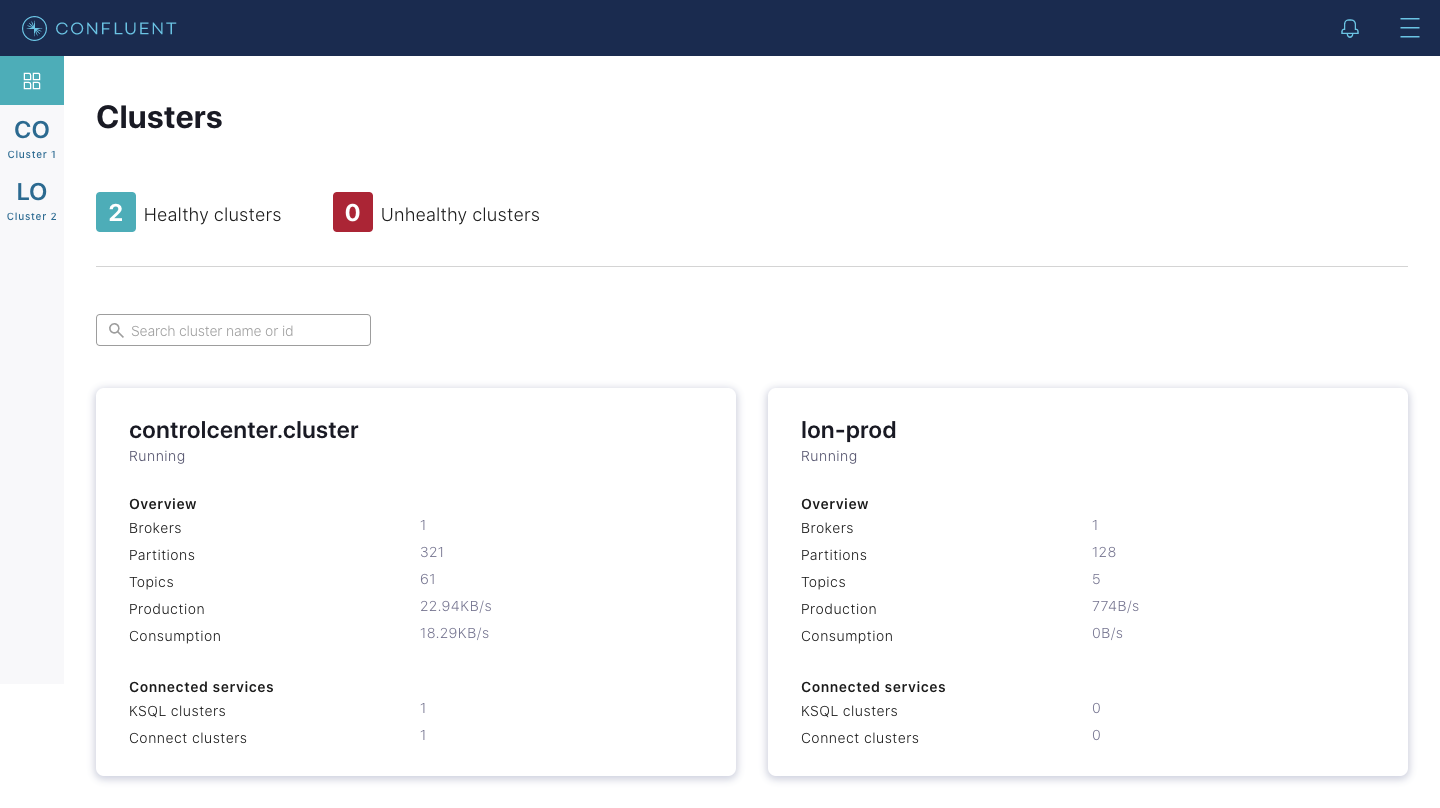
Please refer to the documentation on multi-cluster configuration for details.
Prior to Confluent Platform 6.0.1, the aforementioned approach was the only option to configure multiple Kafka clusters for use with Confluent Control Center. In the following sections, we explain how the latest release makes multi-cluster management more convenient through the Cluster Registry.
What is Cluster Registry?
Built on the top of Confluent Platform Metadata Service (MDS), Cluster Registry enables you to keep track of which clusters you have installed. For those who are not familiar with MDS, the Confluent Platform Metadata Service manages a variety of metadata about your Confluent Platform installation. Specifically, the MDS:
- Hosts the Cluster Registry that enables you to keep track of which clusters you have installed
- Serves as the system of record for cross-cluster authorization data
- Provides a convenient way to manage audit log configurations across multiple clusters
A prerequisite for using Cluster Registry is enabling RBAC first. RBAC, aka Role-Based Access Control, is a method for controlling system access based on roles assigned to users within an organization. RBAC leverages the Confluent Platform Metadata Service to configure and manage its implementation from a centralized configuration context.
Register clusters
You can use either curl commands or the Confluent Platform CLI to register clusters. When registering a Kafka cluster in the Cluster Registry, you must specify the following information:
- Cluster name: The name of the Kafka cluster
- Cluster ID: The ID of the Kafka cluster
- Host name and port number: The connection information for the cluster
- Protocol used by the hosts and ports: The protocol should be SASL_SSL for Kafka clusters (or SASL_PLAINTEXT for non-production Kafka clusters) and HTTP or HTTPS for Kafka Connect, ksqlDB, and Schema Registry clusters
Register clusters using the CLI
To register a new Kafka cluster using the CLI:
- Log in to the MDS cluster first:
confluent login --url <protocol>://<host>:<port>
- Register the new Kafka cluster by running the following command:
confluent cluster register \ --cluster-name <exampleKafka> \ --kafka-cluster-id <kafka-ID> \ --hosts <10.6.6.6:9000,10.3.3.3:9003> \ --protocol SASL_PLAINTEXT
- Register a new Connect cluster associated with a new Kafka cluster:
confluent cluster register \ --cluster-name <exampleConnect> \ --kafka-cluster-id <kafka-ID> \ --connect-cluster-id <connect-ID> \ --hosts <10.6.6.7:8443> \ --protocol HTTP
Note: Substitute the values in < > with your information
For a complete guide, please refer to the Cluster Registry documentation.
Control Center + Cluster Registry
As mentioned in the introduction, in Confluent Platform 6.0.1, we added support in Control Center to read cluster information from Cluster Registry. This means that Control Center can use Cluster Registry as the primary source of cluster information over its configuration properties file.
The diagram below shows how Control Center discovers the cluster information when Cluster Registry is enabled and disabled.
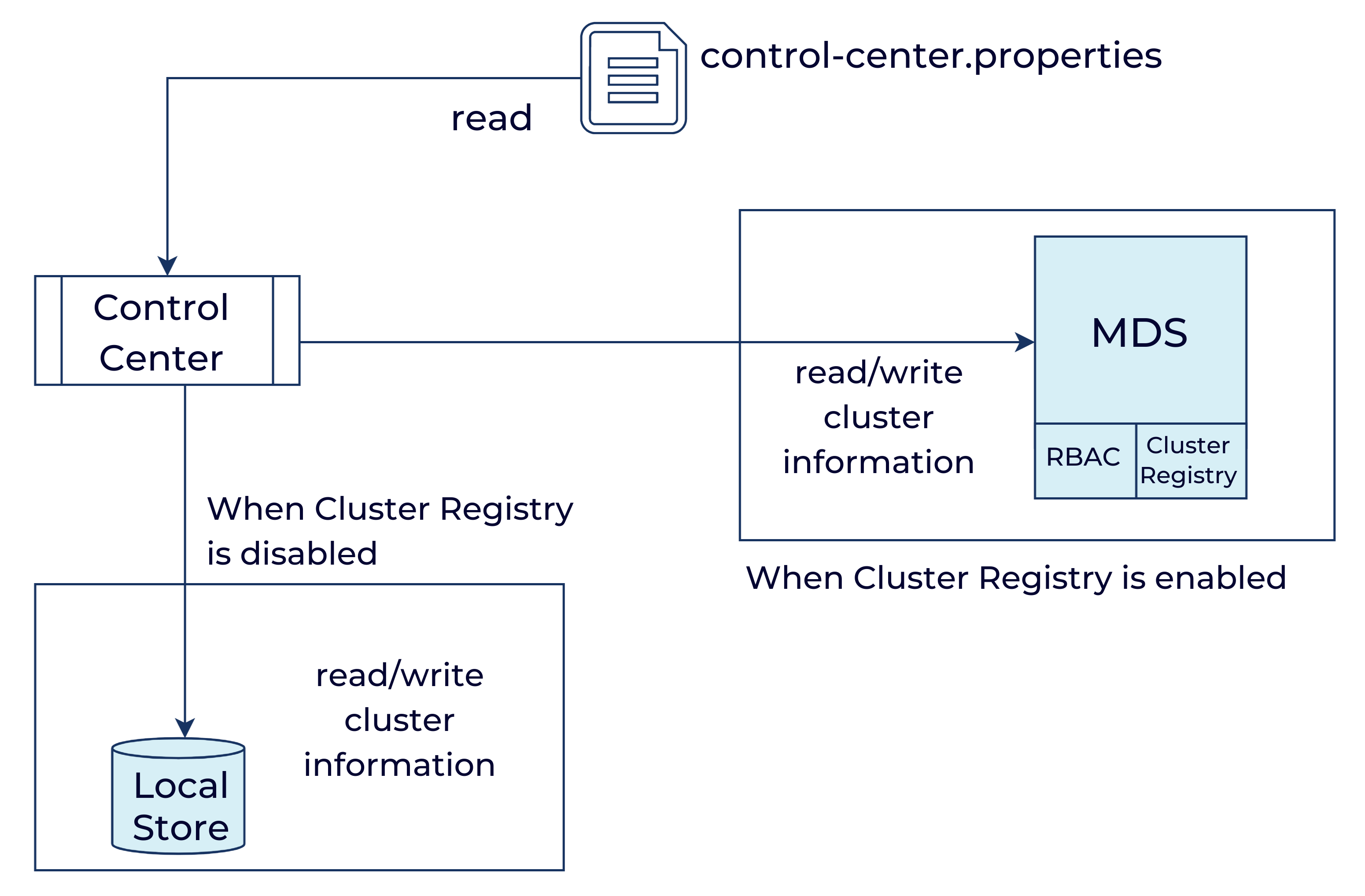
Enable Cluster Registry in Control Center
To enable reading cluster information from Cluster Registry, you can follow these steps:
- First, add the following configuration in Control Center’s properties file: confluent.metadata.cluster.registry.enable=true
- Second, add RBAC settings to the control-center.properties file as explained in this guide
After performing #1 and #2, start Control Center or reboot if it’s already running. Once started, Control Center should read the cluster information from Cluster Registry.
A few things to note:
- When Cluster Registry is enabled, there is no need to specify Kafka settings in Confluent Control Center’s configuration files. It is only needed if we need to specify extra properties for communicating with the Kafka cluster (e.g., ssl.* settings for encrypted communication).
- Control Center’s bootstrap cluster information still needs to be configured in the properties file. We cannot tell which cluster is the bootstrap cluster from Cluster Registry alone.
Migration scripts
To make it easier to migrate cluster information from Control Center to Cluster Registry, we have added the scripts below to Confluent Platform.
Control-center-export
You can use this script to export the existing cluster information from Control Center:
control-center-export --cluster control-center.properties --outfile exported-cluster-info.json
The exported data looks like this:
[
{
"clusterName": "lon-prod",
"scope": {
"path": [],
"clusters": {
"kafka-cluster": "jRCEm14eR_SadwCWqhXV-w "
}
},
"hosts": [
{
"host": "localhost",
"port": 9193
}
],
"protocol": "SASL_PLAINTEXT"
}
]
Cluster-information-migration-script
This script provides a way to import or export data off Cluster Registry. Here is how you can import cluster information into Cluster Registry:
cluster-information-migration-script -i --url http://mds:8090 -f exported-cluster-info.json
To export cluster information from Cluster Registry, you would perform a similar action:
cluster-information-migration-script -e --url http://mds:8090 -f cluster-info-to-export.json
Update cluster name from Control Center
Control Center has always allowed you to update a Kafka cluster’s name via a UI as shown below.
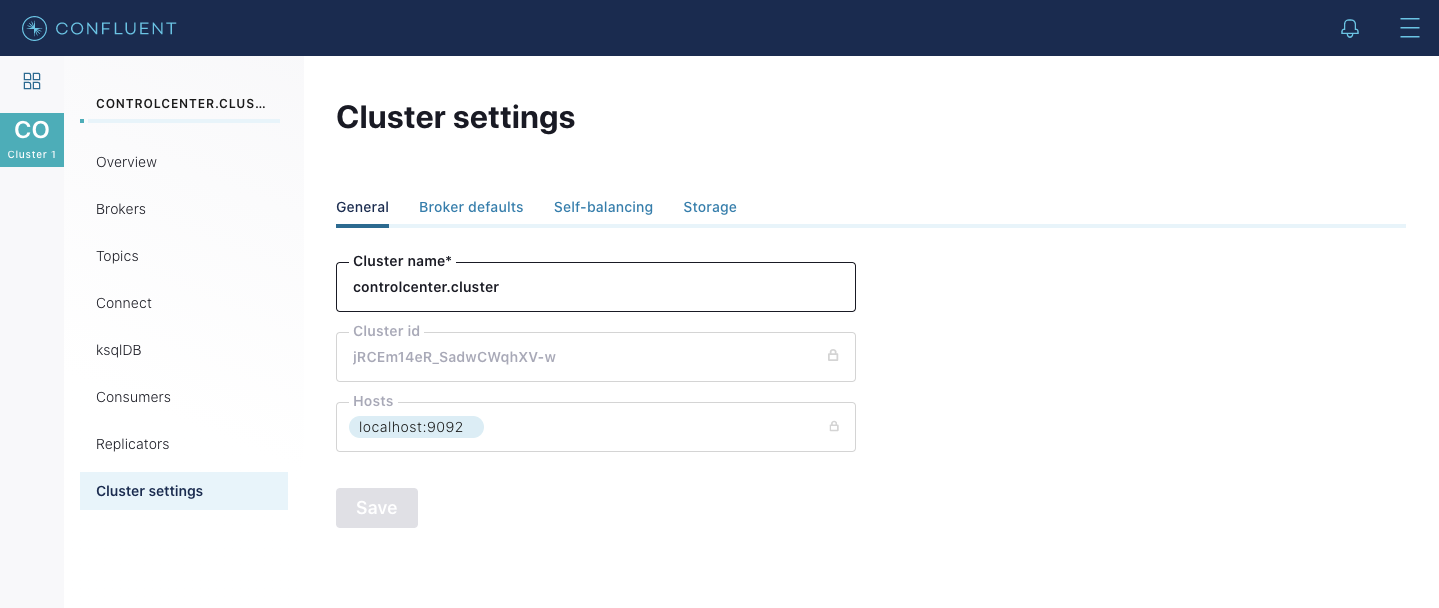
This is true when Cluster Registry is enabled as well. Control Center can not only read the cluster information from Cluster Registry, but it also allows you to edit the cluster name. The change is persisted in Cluster Registry.
For example, if the user changed the name from lon.prod to say nyc.prod, the result of the confluent cluster list command would be this:
> confluent cluster list > Name | Type | Kafka ID | Component ID | Hosts | Protocol >+----------------+-----------------+-----------+--------------+------------------------------+----------------+ > nyc.prod | kafka-cluster | jRCEm14eR_SadwCWqhXV-w | | localhost:9192 | SASL_PLAINTEXT
Conclusion
In summary, we encourage you to take advantage of Cluster Registry as the source of cluster information for Control Center. This is just the first step. We expect to add more to the integration story in the future, so stay tuned.
If you haven’t already but would like to get started with Cluster Registry today, you can download the Confluent Platform.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.