Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
To Pull or to Push Your Data with Kafka Connect? That Is the Question.
Today, every company is a data company. There are many different data pipeline, integration, and ingestion tools in the market, but before you can feed your data analytics needs, data must be collected before any processing can begin. Often collecting and delivering data to the right place in the right format is even more challenging than data analytics. In my Kafka Summit session, I shared about my team’s experience with replacing an SIEM vendor’s data collection layer with Kafka Connect. Your data may be different than ours, but the data collection approach will likely look the same. This post expands on my Kafka Summit session and focuses on how to collect data from many different remote hosts and services with more explanation on the technical details.
Once you have Kafka up and running, it’s time to feed it with the data. When collecting data, there are two fundamental choices to make: Are we going to poll the data periodically (pull), or will the data be sent to us (push)? The answer is both! Let’s take a look at how using these three components:
NettySource Source Connector
First, here’s a quick recap on what the NettySource connector is and why you need it. The connector was developed to receive data from different network devices to Apache Kafka®. The connector will help you to receive data using both the TCP and UDP transport protocols and can be extended to support many different application layer protocols. Support for some of these protocols are already available, but for others where it is not available, the connector makes new implementations easy.
Let’s walk through different connector configurations from the simplest to the most advanced.
Netty connector configuration
connector.class=com.mckesson.kafka.connect.nettysource.NettySourceConnector topic=network_data transport.protocol=TCP bind.address=10.0.0.10 port=1111
This minimal configuration will allow you to receive network data as is. Minimal configuration options are required to run the connector:
- transport.protocol: used to receive data; supports TCP or UDP
- bind.address: defines which interface should have a port open; default of 0.0.0.0
- port: the port to listen to; required, no default value
Note that different defaults will be applied depending on the selected transport protocol. If TCP transport is configured, the input stream will split into records using \n or \0 terminating bytes; for UDP, records will be created from each datagram packet.
| ℹ️ | Tip: The easiest way to test that the connector is running and receiving data is to use Linux:
$ echo -e "Test Message\n" | ncat localhost 1111 |
Populated headers
Kafka record headers can be used for different purposes, and the connector’s default implementation adds the following headers for each produced Kafka record:
- remoteHost
- remotePort
- localHost
- localPort
Headers can be used to route, filter, and transform messages from different hosts.
TLS/SSL support
For TCP transport, cryptographic protocols can be configured. To enable TLS, add the following configuration:
ssl.enabled = true ssl.keystore.type = JKS ssl.keystore.location = keystore.jks ssl.keystore.password = <password> ssl.key.alias = my_key ssl.key.password = <password>
For more configuration options, check out the Kafka docs or connector documentation.
| ℹ️ | Tip: To validate SSL/TLS configuration, use openssl commands:
$ echo -e "Test Message\n" | openssl s_client -connect 127.0.0.1:1111 |
Additional configuration options
In the real world, basic configuration is not enough. Fortunately, there are some extended configuration options available.
Multiple tasks and ports
You may find that one instance of the connector is not sufficient to consume a large amount of data. To address this, you can configure multiple tasks. Multiple tasks may happen to run on the same Kafka Connect worker, so to avoid port conflicts, you can define multiple ports:
tasks.max=3 ... ports=1111,2222,3333
If multiple ports are configured, each task will attempt to start listening to listed ports in the order that they are declared. If one port is already in use, the next from the list will be taken; if all declared ports are in use, the task will fail.
Health check and a load balancer
Once you’ve configured multiple tasks, the next reasonable step would be to place connectors behind a load balancer. To enable “active check” on the load balancer, we need to enable the health check listener on the connector side:
healthcheck.enabled=true healthcheck.port=4444
Once you’ve enabled the health check, a simple TCP listener will start on the configured port (use healthcheck.ports if multiple ports are configured).
High availability deployment
To implement a highly available data receiving service, you can run multiple Kafka Connect clusters that send data to the same Kafka cluster. This allows you to perform connector maintenance with zero downtime in receiving the data:
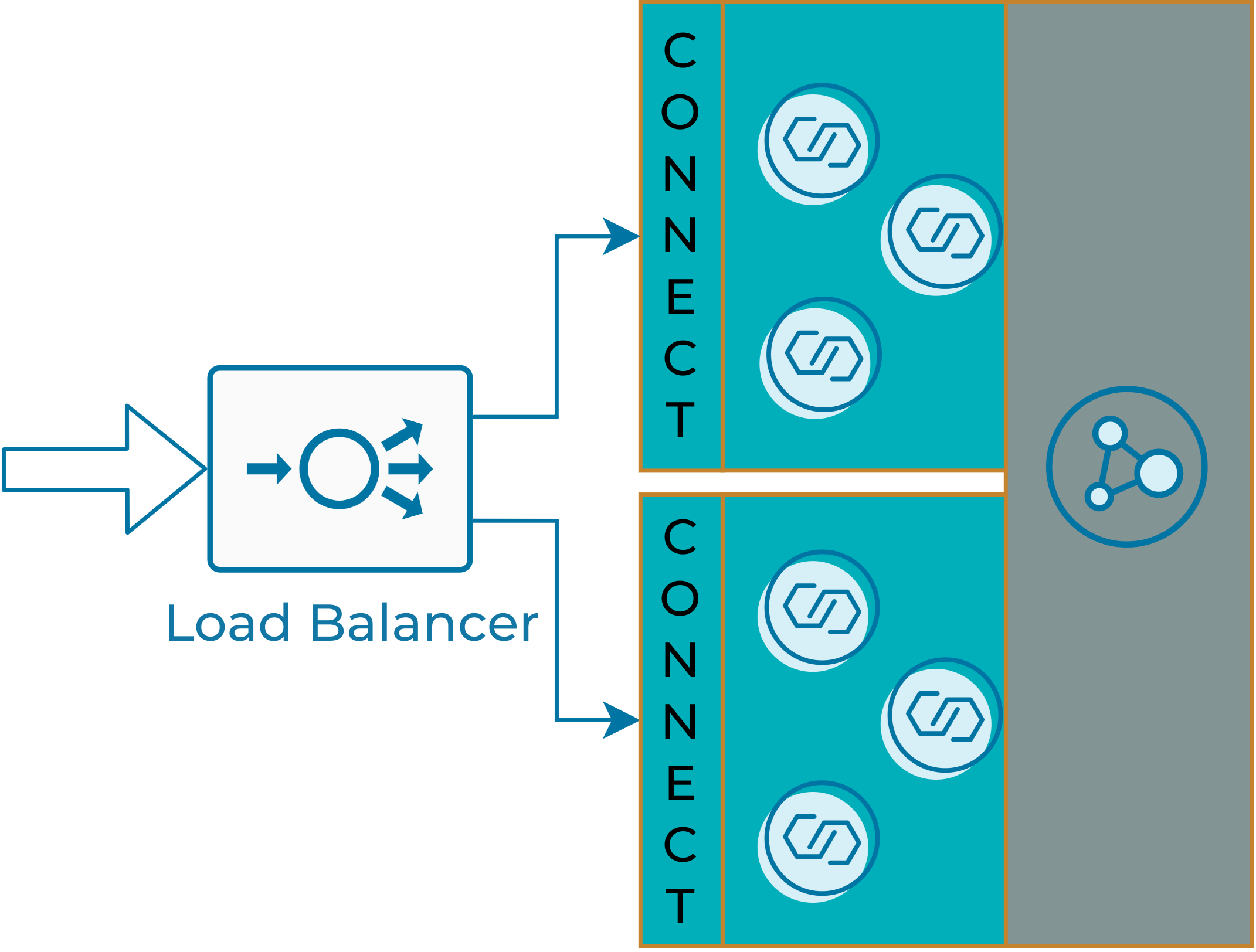
Highly available NettySource connector
You can perform this using any load balancing solution. HAProxy for TCP balancing and Keepalived (IPVS) for UDP. Below are very simple configurations for multi-backend Kafka Connect clusters.
HAproxy:
frontend test_1111
mode tcp
bind *:1111
timeout client 10m
maxconn 100
default_backend test_1111
backend test_1111
balance roundrobin
timeout server 5m
option tcp-check
tcp-check connect port 1111
## KC backend #1
server b1_s1 10.0.1.1:1111 check
server b1_s2 10.0.1.2:1111 check
# KC backend #2
server b2_s1 10.0.2.1:1111 check
server b2_s2 10.0.2.2:1111 check
Keepalived:
virtual_server 10.0.0.1 1111 {
protocol UDP
lb_algo rr
lb_kind NAT
!KC backend #1
real_server 10.0.1.1 5001 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 4444
}
}
real_server 10.0.1.2 5001 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 4444
}
}
!KC backend #2
real_server 10.0.2.1 5001 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 4444
}
}
real_server 10.0.2.2 5001 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 4444
}
}
Connector queue configuration
Internally, the connector uses an in-memory queue. Depending on the size of the messages that the connector receives, you may want to adjust the capacity to avoid large memory consumption. The following parameter can be used to change queue capacity:
connector.queue.capacity=1000
The connector also supports custom queue implementation:
connector.queue.class=<custom implementation>
Custom queues must implement a BlockingQueue interface. Configurable can also be implemented for custom queue configurations.
Connector customization
The connector is based on Netty project. If you are familiar with the Netty event model, you can customize the connector accordingly. TCP and UDP protocols have different default channel pipeline factories implemented. The following channel handlers are available in the default implementations:
| Handler name | Default implementation | Description |
| framer | TCP: DelimeterOrMaxLengthFrameDecoder | Decodes the received ChannelBuffers into meaningful frame objects. |
| decoder | StringDecoder | Decodes a received ChannelBuffer into a String |
| recordHandler | StringRecordHandler | Produces a Kafka record from decoded data |
Two options are available for customizing the connector: configure or replace default pipeline factories.
Pre-configured handlers can be changed or removed with configuration options. See the example below, which removes the decoder handler and replaces framer with custom implementation:
pipeline.factory.handlers=framer, decoder pipeline.factory.handlers.framer.class=com.mckesson.kafka.connect.nettysource.SimpleDelimeterFrameDecoder pipeline.factory.handlers.framer.maxFrameLength=8192 pipeline.factory.handlers.decoder.class=
If changing handlers of the default pipeline factory is not enough, you can replace whole with a custom implementation. This allows you to implement your own application protocols. The following example supports the HTTP protocol using the connector:
pipeline.factory.class=com.mckesson.kafka.connect.nettysource.HttpPipelineFactory pipeline.factory.handlers=recordHandler pipeline.factory.handlers.recordHandler.class=com.mckesson.kafka.connect.nettysource.HttpRequestContentRecordHandler
As you can see, the Netty Source Connector is a very powerful connector that allows you to receive different data from the network. For additional information, you can refer to the documentation.
PollableAPIClient Source Connector
The Netty Source Connector was made to receive data from a remote system, but the other way to collect data is to pull it from a remote system. This is where the PollableAPIClient Source Connector comes in. The purpose of this connector is to pull data from different remote APIs and services. What sets it apart is that it makes integration with new APIs quick and easy even for developers who have never worked with the Kafka Connect API before.
PollableAPIClient connector configuration
This connector is built on the concept of separating data ingestion from all the Kafka Connect API details. It allows you to plug in different data API implementations. Typically, the connector configuration looks like this:
connector.class=com.mckesson.kafka.connect.source.PollableAPIClientSourceConnector topic=api_data apiclient.class=com.mckesson.kafka.connect.source.PollableAPIClient poll.interval = 30000
Here, apiclient.class is a class that implements PollableAPIClient interface. Implementations for different public APIs can be found in the documentation. You can configure the frequency at which the remote API will be polled in two ways: via poll.interval or poll.cron.
The Kafka Connect API provides you with the ability to ”save” state between polls. Even after restarts, it will “pick up” state. Sometimes it may be required to (re)start data collection from a specific point. initial.offset is an additional configuration option available that allows you to set the starting point for your connector, as well as the value for this parameter (which can vary for different API client implementations). In some cases, you may need to reset the connector and force it to “forget” state. The reset.offsets=true configuration option allows you to do so. You can find more configuration parameters in the connector documentation.
Custom connector implementation
Now let’s talk about how to implement a custom client for the connector. There are two concepts around the Kafka Connect API to note:
- Partition: identification information of each bucket of data, which you may have in a connector; it can be file, directory, shard, data type, etc.
- Offset: identification information of a position within each bucket (partition), such as unique ID, incrementing field, and last modified timestamp; The offset value will be persisted automatically between executions
To implement a custom client, you need to implement the interface. Let’s take a closer look:
public interface PollableAPIClient extends Configurable, Closeable {
public List poll(String topic, Map<String, Object> partition, Map<String, Object> offset, int itemsToPoll, AtomicBoolean stop) throws APIClientException;
public List<Map<String, Object>> partitions() throws APIClientException;
public Map<String, Object> initialOffset(Map<String, Object> partition) throws APIClientException;
public void close(); }
- poll: key method the does the job
- partitions: allows you to define partitions
- initialOffset: initial offset for each partition created in the partitions() method
The first step is to define how data will be partitioned. Here is an example:
public List<Map<String, Object>> partitions() {
List<Map<String, Object>> partitions = new ArrayList<>(2);
for (String item : Arrays.asList("directoryAudits","signIns")) {
partitions.add(Collections.singletonMap(PARTITION_NAME_KEY, item));
}
return partitions;
}
The next step is to define the offset (starting point) for each partition:
public Map<String, Object> initialOffset(Map<String, Object> partition) {
return new HashMap<String, Object>() {
{
put(OFFSET_KEY_TIME, System.currentTimeMillis());
}
};
}
Finally, define the method that polls the data. Usually this consists of three steps:
- Restore/read a previously stored offset for a partition.
- Read data. There are two additional parameters:
- itemsToPoll: Informs the API client how many records are left until the configured batch.size gets full.
- stop: A mutable Boolean value.; clients should check this value (especially if it performs long-running requests). When stop == true, the client must terminate its activity and exit immediately.
- Store the last read position (offset) for the partition:
public List<SourceRecord> poll(String topic, Map<String, Object> partition, Map<String, Object> offset, int itemsToPoll, AtomicBoolean stop) throws APIClientException { //1 long startTs = offset.get(OFFSET_KEY_TIME); //2 List<SourceRecord> records = ... long endOffset = readData(partition, startTs, records); //3 offset.put(OFFSET_KEY_TIME, endOffset);return records; }
As you can see, building custom API clients is really easy. For more details and examples, please see the documentation.
Transformations library
Collecting data is just the first step, but it’s more important to bring data to the right place in the right format. This brings us to the transformations library, by which we perform three tasks:
- Sorting various types of data to different topics to process it in multiple ways
- Filtering data to keep only the valuable bits and skip the rest
- Transforming data to turn it into a desired format
Let’s take a look at how Kafka Connect transformations can help.
Tagging data
To sort out the data, we need to “tag” data first. Kafka record headers are a good way to go. We can rely on existing headers or add additional ones. The first transformation is AddHeader, which allows you to add headers to a Kafka Connect record. It’s as easy as:
transforms=add_src_hdr transforms.add_src_hdr.type=com.mckesson.kafka.connect.transform.AddHeader transforms.add_src_hdr.name=data.source transforms.add_src_hdr.value=mySource
This snippet adds a Kafka record header with the name data.source and the value mySource. There are two features that connectors support: conditions and expressions, which are used widely. Now, let’s take a look at them up close.
Conditions
Sometimes different transformations need to be applied to different types of data. Many transformations support conditions in order to apply or skip transformation. You can use the following configurations to define a condition:
| if | Depending on if_mode, it can be either String or a valid regular expression value |
| if_mode | find: Find the subsequence match: Match the entire string against the pattern eq: Check the String for equality contain: Find the substring without a regular expression in: Check if one value is from a static list of strings |
The example below will add a header if the record value contains a kafka substring:
transforms=add_src_hdr transforms.add_src_hdr.type=com.mckesson.kafka.connect.transform.AddHeader transforms.add_src_hdr.condition.if=kafka transforms.add_src_hdr.condition.if_mode=find
| ℹ️ | Note: Since Kafka 2.6, predicates have been added to the Kafka Connect API. We plan to implement conditions as predicates in the future. |
Expressions
Simple expressions can be used to address different parts of a Kafka record.
- KEY refers to the key data of a Kafka message
- VALUE refers to the body of a Kafka message
- TOPIC refers to the topic value of a Kafka message
- TIMESTAMP refers to the timestamp of a Kafka message
- PARTITION refers to the partition value of a Kafka message
- HEADER.<NAME> refers to the header with the <NAME> of a Kafka message
To use these expressions, they must be framed in ${…}, for example:
transforms.add_src_hdr.value=src:${HEADER.remoteAddr}
Filtering, routing, and data transformation
Three additional transformers are available:
| RegexFilter | Filter messages with regular expressions |
| RegexRouter | Route a message to a different topic based on regular expressions |
| RegexRules | Apply regular-expression-based transformation rules |
The simple data masking transformation example below can give you an idea of how to use transformations:
transforms=data_mask transforms.data_mask.type=com.mckesson.kafka.connect.transform.RegexRules transforms.data_mask.applyTo=VALUEtransforms.data_mask.rules=cc16,ssnus
transforms.data_mask.rules.cc16.find=\b\d{4}(-?\s?)\d{4}(-?\s?)\d{4}(-?\s?)\d{4}\b transforms.data_mask.rules.cc16.replacement=XXXX$1XXXX$2XXXX$3XXXX
transforms.data_mask.rules.ssnus.find=\b[0-9]{3}([\s-])[0-9]{2}([\s-])[0-9]{4}\b transforms.data_mask.rules.ssnus.replacement=SSS$1SS$2SSSS
More transformation configurations and documentation can be found on GitHub.
Conclusion
Collecting data can be a difficult task, especially if your data is in various forms across different places and you need to run it at scale. Kafka Connect is a brilliant solution for bringing your data into Kafka for further processing and analytics. The connectors and approaches described in this blog post will help you collect data with less effort. You can easily adopt the connectors to your needs both for “push” and “pull” data types. This is ultimately what makes for a rich data collecting ecosystem.
If you enjoyed this article and would like to learn more, watch my Kafka Summit talk: Feed Your SIEM Smart with Kafka Connect.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...