Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Introducing 18 New, Fully Managed Connectors in Confluent Cloud
In our February 2020 blog post Celebrating Over 100 Supported Apache Kafka® Connectors, we announced support for more than 100 connectors on Confluent Platform. Since then, we have been focused on bringing more and more of these connectors onto Confluent Cloud so that you don’t have to self-manage them. Fully managed connectors enable you to realize value faster from a data in motion platform by making integrations effortlessly easy and reliable without any operational burden or management complexity. This allows you to shift focus back on building features and innovations that serve your customers directly.
It has been a busy few months for Confluent’s Connect team, and we’re excited to announce broader coverage of popular source and sink systems with 18 new fully managed connectors on Confluent Cloud.
Now generally available, our recently released fully managed connectors are:
Additionally, we’ve released the Databricks Delta Lake Sink connector in preview so that you can start testing it in non-production environments.
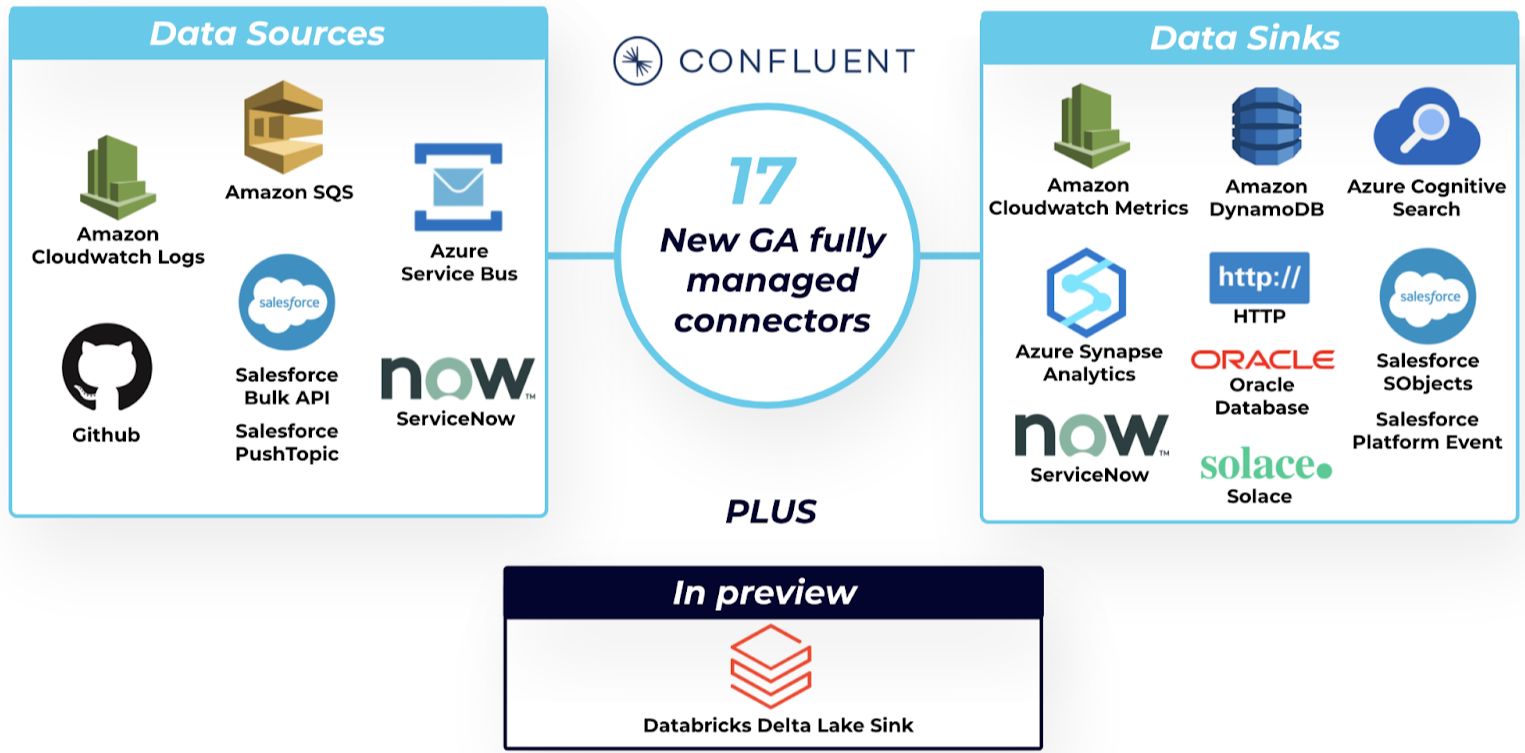
Confluent Cloud’s 18 new connectors cover a diverse set of popular systems and applications from cloud platform products to SaaS apps
When using these new fully managed connectors alongside helpful out-of-the-box features like single message transforms (SMTs), data output preview, and connector log events, you can now experience just how easy it is to start building transformative use cases in Confluent Cloud. Of course, we won’t be able to discuss in detail each of these 18 new connectors in this blog post. Instead, we’ll focus on a popular real-time data warehouse ingestion use case that can be relevant to several of these new connectors. Finally, we’ll put it to action with a demo scenario showcasing the Salesforce Bulk API source connector, Azure Synapse Analytics sink connector, and SMTs.
Real-time connection to a data warehouse
Modern cloud data warehouses power business-critical analytics for organizations at lower costs, increased elasticity, and improved performance compared to legacy ones. They support the ever growing amount of data and variety of workloads needed to drive informed business decisions and personalized customer experience. For organizations that have either already migrated off their legacy data warehouse or started in the cloud, the focus shifts to making sure that cloud data warehouse is populated in real-time with changes from the source data systems so that it continuously acts as the single source of truth. The sooner your data warehouse can reflect the current state of the business, the sooner and more confidently you can make decisions.
However, the most common way of ingesting data is still batch loading through traditional extract, transform, and load (ETL) jobs. This means that no matter how flexible or analytically powerful your data warehouse is, your queries are returning stale data from the past. This simply isn’t good enough in today’s digital-first world, especially for mission-critical use cases like live monitoring, inventory management, and financial services. Another common challenge is tackling the integration of multiple data silos with your data warehouse, especially across hybrid or multi-cloud environments. Building and managing your own custom connectors could take on average 3-6 engineering months per system, taking up precious engineering resources, adding perpetual operational burden, and delaying your time-to-value.
Using Confluent Cloud and our fully managed connectors as your streaming ETL pipeline makes it easy to achieve real-time data warehouse pipelines so that new data is available for querying immediately. Connectors also future-proof your data architecture for the addition of new systems or changes down the road. For example, the new Azure Synapse Analytics sink connector completes our offering of fully managed connectors for popular managed data warehouse solutions from Snowflake and each of the three major cloud providers, joining Amazon Redshift and Google BigQuery sink connectors.
Of course, data rarely comes in a form that’s immediately useful so you’ll likely also want to transform data. SMTs make it convenient for you to perform minor data adjustments in real-time within the managed connector, like inserting fields or masking sensitive information. ksqlDB stream processing takes care of more robust transformations, like merging multiple data sources or unlocking immediate insights. Processing data in stream with SMTs and ksqlDB improves scalability and eliminates the need for costly downstream processing of a high volume of data in the data warehouse or an intermediary system like a database.
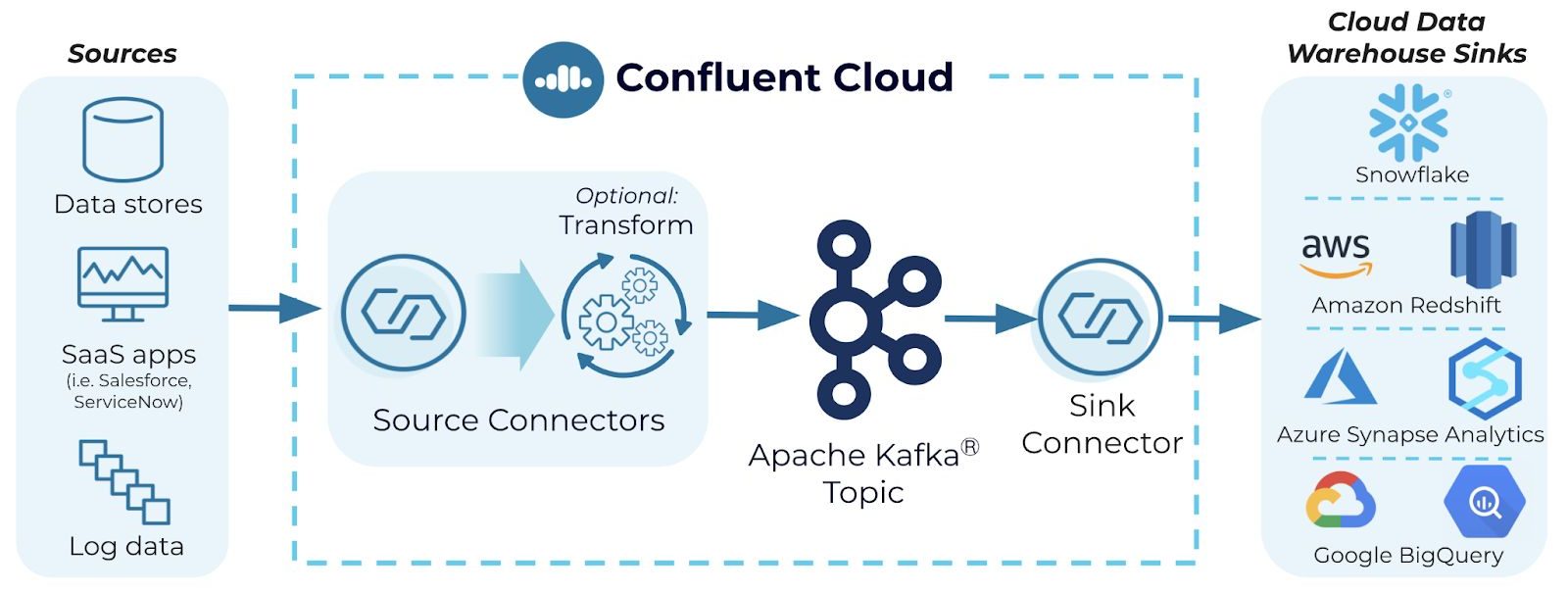
Connect to a cloud data warehouse of your choice
Let’s look at an example of how a cloud-native organization built on Azure can send events from their Salesforce to Azure Synapse Analytics in real-time while performing some lightweight transformations along the way with SMTs. If your company is on AWS or GCP or prefers using Snowflake, simply switch out the sink for the cloud data warehouse of your choice.
Demo scenario
Your company–we’ll call it Acela Loans–is a fintech consumer lending company that combines traditional risk factors like credit score with a proprietary algorithm to recommend a loan product. Acela Loans stores its prospect information in Salesforce and wants to send leads data from India, its newest regional expansion, to its Azure Synapse Analytics data warehouse for their data science team to use to further refine their algorithm.
Confluent’s fully managed Salesforce Bulk API source connector pulls records and captures changes from Salesforce.com using the Salesforce Bulk API Query. Bulk query is suitable for querying large data sets and reduces the number of API requests. The Azure Synapse Analytics sink connector continuously polls from Confluent and writes the data into Azure Synapse Analytics (SQL pool).
Using Salesforce Bulk API Source
Log into Confluent Cloud and set up a Kafka cluster running on Azure. For the purpose of this demo, we are choosing Azure as our Confluent Cloud environment because that is where our Azure Synapse Analytics data warehouse lives, but the Salesforce source connector is supported on all three cloud platforms, so feel free to choose AWS or GCP for your Kafka cluster if you are sinking to a different data warehouse.
Once the Kafka cluster is created, create a topic bulk_api_json_sr to capture the prospect data coming from Salesforce. Next, navigate to the left menu and click through Data integration > Connectors to search for the Salesforce Bulk API source connector. Notice as you search that we have several types of Salesforce source connectors available (Bulk API, CDC, and PushTopic) so that you can connect to your CRM through the method most suitable for your use case. Begin filling out the connector configurations page with your Kafka cluster and Salesforce credentials.
Transform with SMTs
At the bottom of the connector configuration page, we can add SMTs so that incoming messages are transformed as they come. For Acela Loans, they would like to perform the following two chained transformations prior to writing into Kafka:
- Filter by country for leads from India only
- Mask sensitive personal data like phone numbers and email addresses
To achieve this, we will first apply the Filter transformation to remove records that don’t fit the condition, then use the MaskField transformation to mask the “phone” and “email” fields.
![]()
In the “Transforms Name” field on the connector configuration UI, enter an alias for the transformation name–we’ll use “FilterCountry”–then click Add Transforms to reveal the expanded dialog box. Select the transformation type io.confluent.connect.transforms.Filter$Value and for the filter condition, specify that the “Country” field is equal to “India”. For filter type, use “include” to pass through records that match the condition and drop all other records. Lastly, for missing or null behavior, use “exclude” to drop any records that don’t have the “Country” field.
![]()
We’ll add a second transformation “MaskEmail” following similar steps but using the org.apache.kafka.connect.transforms.MaskField$Value transformation type. Select the fields “Email” and “Phone” on which the masking will be applied. The fields will be masked with the value provided in the “replacement” field, which we’ll replace with the word “REDACTED”.
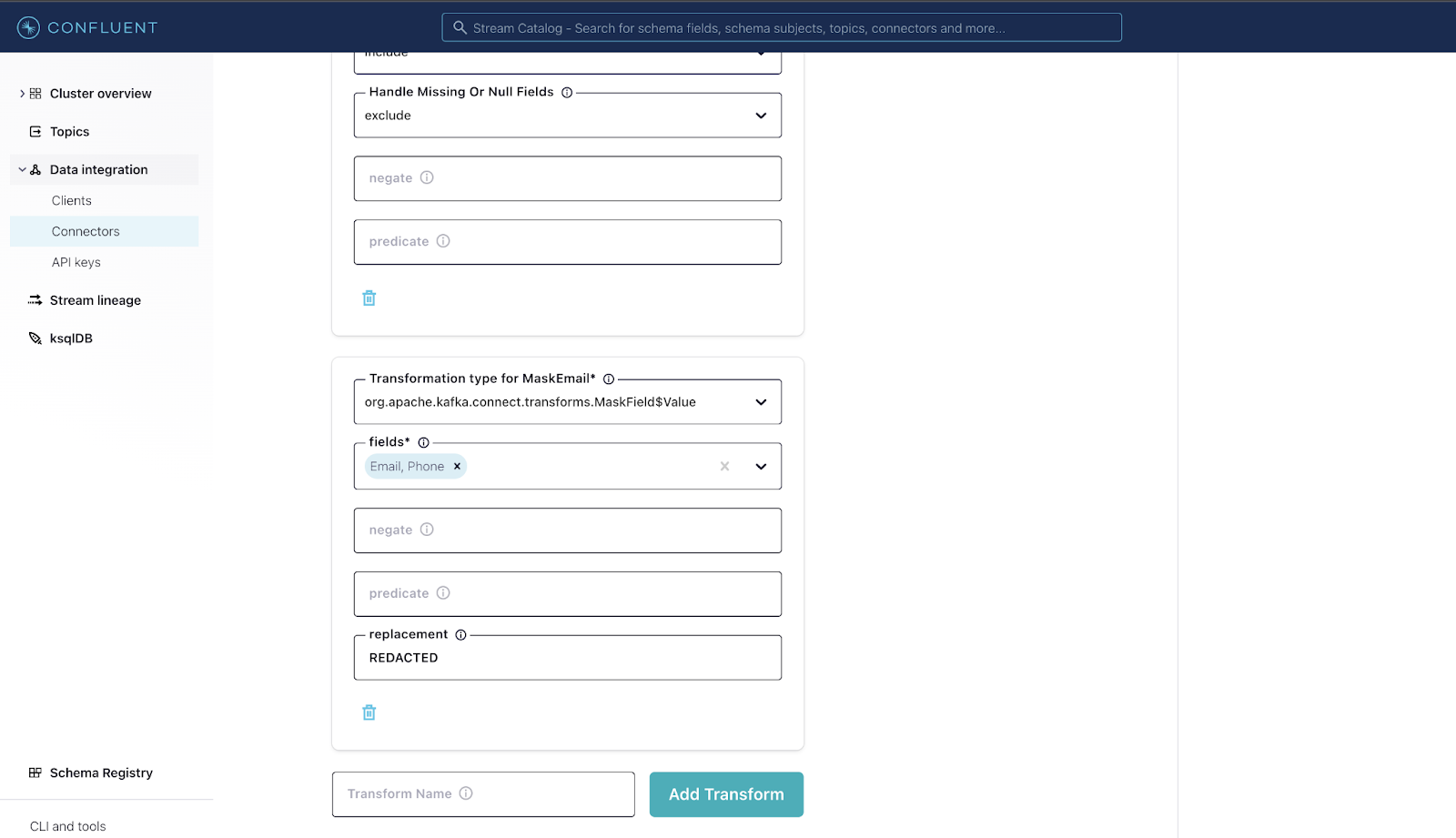
Now that we have our SMTs set up, it’s time to check our configurations and launch our connector. Click Next at the bottom of the page.
Connector configurations:
{
"name": "SalesforceBulkApiSourceConnector_2",
"config": {
"connector.class": "SalesforceBulkApiSource",
"name": "SalesforceBulkApiSourceConnector_2",
"kafka.topic": "bulk_api_json_sr",
"salesforce.instance": "https://login.salesforce.com/",
"salesforce.username": "pbhansali@confluent.io",
"salesforce.object": "Lead",
"salesforce.since": "2019-09-09",
"output.data.format": "JSON_SR",
"tasks.max": "1",
"transforms": "FilterCountry, MaskEmail",
"transforms.FilterCountry.type": "io.confluent.connect.transforms.Filter$Value",
"transforms.FilterCountry.filter.condition": "$[?(@.Country == 'India')]",
"transforms.FilterCountry.filter.type": "include",
"transforms.FilterCountry.missing.or.null.behavior": "exclude",
"transforms.MaskEmail.type": "org.apache.kafka.connect.transforms.MaskField$Value",
"transforms.MaskEmail.fields": "Email, Phone",
"transforms.MaskEmail.replacement": "REDACTED"
}
}
Once the connector is launched, we’ll go over to the bulk_api_json_sr topic to view the records that are populating. You can see the SMTs in action, filtering out leads from all other countries except from India and successfully masking email and phone fields.
Using Azure Synapse Analytics Sink
Now that the relevant data from Salesforce is processed and streamed into Confluent Cloud, we will send it to the data warehouse using Azure Synapse Analytics sink connector. Search for this connector in the left navigation menu and begin setup.
Enter your credentials and Azure SQL warehouse connection details. This connector supports auto-creation (auto create table) and auto-evolution (auto add columns). If auto.create is set to true, the connector creates the destination table if it’s missing, using the record schema as the basis for the table definition. If auto.evolve is true, the connector issues the alter command on the destination table for a new record with a missing column. The connector will only add a column to a new record. Existing records will have “null” as the value for the new column.
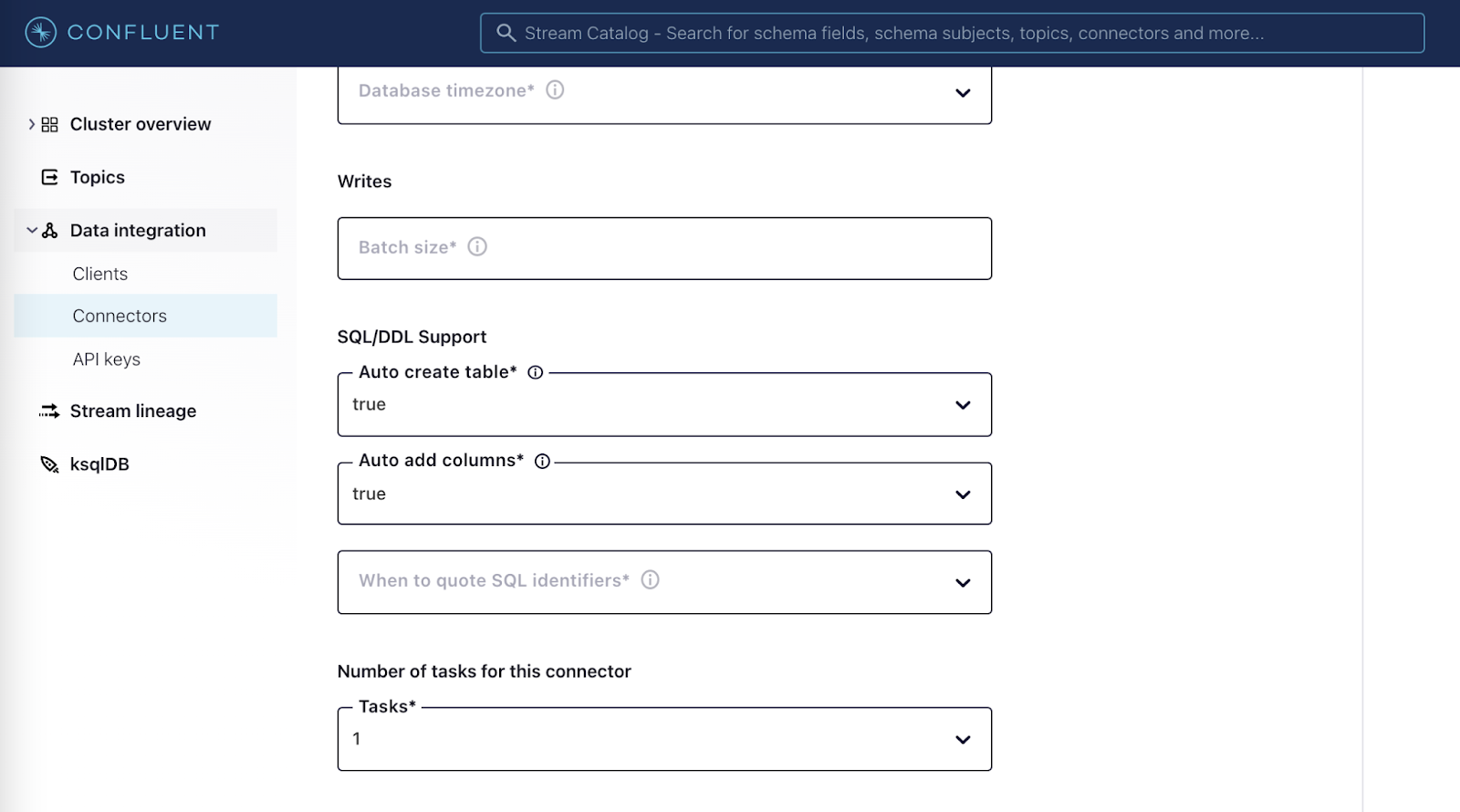
Connector configurations:
{
"name": "AzureSqlDwSinkConnector_1",
"config": {
"topics": "bulk_api_json_sr",
"input.data.format": "JSON_SR",
"connector.class": "AzureSqlDwSink",
"name": "AzureSqlDwSinkConnector_1",
"azure.sql.dw.server.name": "piyush-azure.database.windows.net",
"azure.sql.dw.user": "piyush",
"azure.sql.dw.database.name": "piyush_demo_synapse_dw",
"auto.create": "true",
"auto.evolve": "true",
"tasks.max": "1"
}
}
Launch the connector and check to see that it’s up and running. Heading over to Azure Synapse Analytics, you’ll see that the table has been created and populated with data from Confluent.
You now have a real-time data warehouse with a streaming pipeline from Salesforce to Azure Synapse Analytics, built easily on Confluent Cloud with fully managed connectors.
Summary
In this blog post, we announced the availability of 18 new fully managed connectors for AWS, Azure, Salesforce, and more. We also examined a popular use case of building out real-time data warehouse ingestion and walked through an example of populating customer data from Salesforce to Azure Synapse Analytics with lightweight transformations using SMTs. If you’re looking to learn more about modernizing your data warehouse from legacy systems across hybrid environments, check out our latest demo videos with Tim Berglund that show how to stream data into Snowflake, Amazon Redshift, Google BigQuery, or Azure Synapse Analytics.
If you haven’t already, sign up for a free trial of Confluent Cloud and start using our fully managed connectors today! Use the code CL60BLOG to get an additional $60 of free usage.*
Further reading
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.