Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Leave Apache Kafka Reliability Worries Behind with Confluent Cloud’s 10x Resiliency
As businesses increasingly rely on Apache Kafka® for mission-critical applications, resiliency becomes non-negotiable. Any unplanned downtime and breaches can result in lost revenue, reputation damage, fines or audits, reduced CSAT, or critical data loss.
Therefore, a cloud service is only as useful as it is resilient. Take our customer 10x Banking (their name is coincidental), which depends on Confluent Cloud to be highly reliable and resilient for its many international banking customers.
“Customers expect banking to be flawless with financial products that are targeted and hyper-personalized for their individual needs…. We can’t have a 99.9 percent reliable platform, it has to be 100 percent.” – Mark Holt, Chief Product and Engineering Officer, 10x Banking.
We take pride in our investments in Confluent Cloud’s resiliency and the trust we’ve gained from providing a reliable service for our customers. We’ve managed 15,000+ Kafka clusters (the largest in the world) across all environments around the globe to build a cloud-native Kafka service that can handle both common and esoteric failures in the cloud. Read on to learn more about how we built Confluent Cloud to be 10x more available and durable than open source Apache Kafka.
Kafka is designed with resiliency through replication, but that’s just the beginning
In the context of a cloud service, resiliency means two things. Availability—the platform is always accessible—and durability—the data stored within is also protected from any anomaly such as corruption, loss, etc. Apache Kafka achieves a certain level of resiliency through replication—both across machines in a cluster and across multiple clusters in multiple data centers. However, this design is insufficient for a highly reliable data streaming service in the cloud.
Let’s take a Kafka deployment in the cloud that follows all best practices using the picture below. Here, we have three brokers running in a Kubernetes cluster and some servers, along with load balancers to increase availability. This is just for one availability zone—setting up across AZs does not happen out-of-the-box with Apache Kafka, and requires additional infrastructure with more complexity. With all these elements for just one AZ, there are several things that can go wrong:
- Infrastructure failures such as those on instances and block storage can occur on the underlying cloud environments you are running Kafka on
- Network issues caused by any underlying VPC, docker network, or network protocol
- Errors during necessary maintenance activities including patching, bug fixes, and issues with the overall Kafka deployment
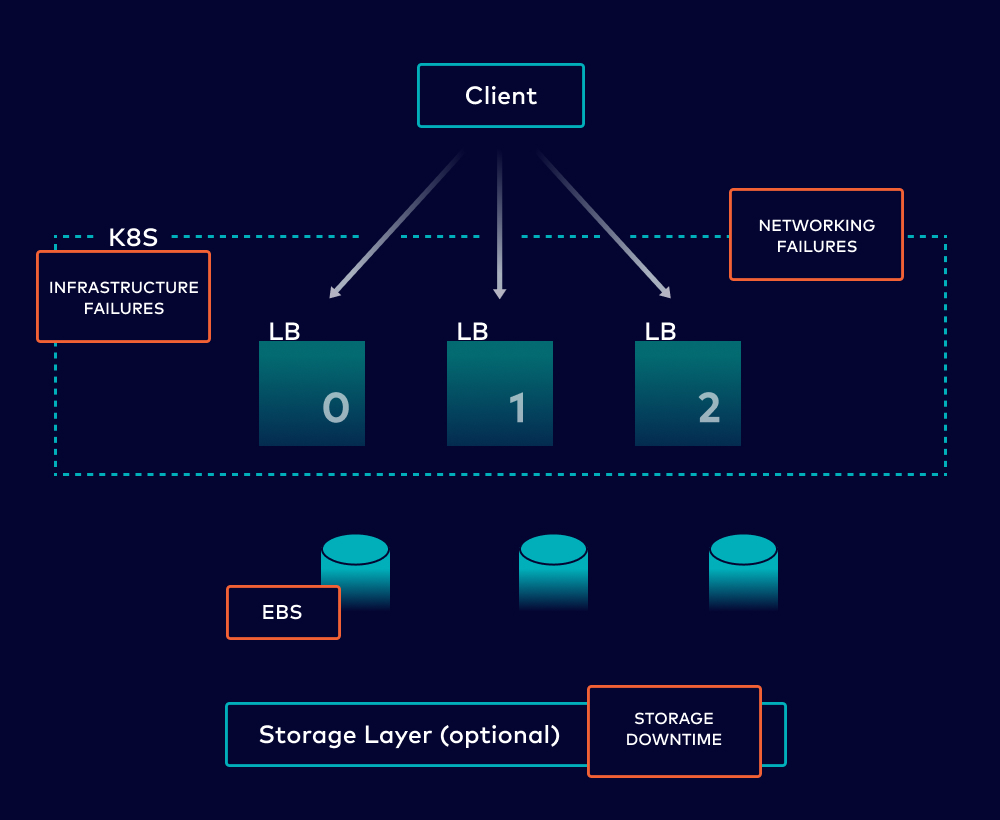
What’s a baseline SLA and downtime we can expect for this example cloud deployment? Let’s assume our brokers are running on EC2 (max 99.5% SLA for individual instances), we have the highest available EBS volumes (99.99% SLA), and we use Amazon elastic load balancers (max 99.99% SLA). We’ll also be nice and assume the underlying Kubernetes infrastructure has a negligible effect on availability. This gives us a baseline SLA = (0.995)^3 * (0.9999)^3*(0.9999)^3 = 0.9845, assuming 3 brokers on EC2, 3 LBs, and 3 EBS volumes. We’ll be generous and round up to 99%. This translates to a potential 5,256 mins (or 3.65 days) of downtime per year, and it presumes that we’ve sized the cluster appropriately and selected the right instances given the expected workload.
That’s just theoretical—in reality, building and maintaining this level of availability takes a lot of effort and manpower. Forrester interviewed several Kafka practitioners on the total economic impact of Confluent Cloud. To support a production-grade SLA, they modeled that a typical data-intensive organization would need four additional FTEs to operate open source Kafka in year one and the resources required will increase by 50% year-over-year as customer demand rises.
It’s easy to understand why this is the case—to really simplify the process, building in a production-grade SLA would require these FTEs to:
- Plan and size the clusters (likely over sizing), and deploy Kafka brokers with redundant data across availability zones for failover
- Manually install Kafka updates and patches to keep it running at the most stable version with minimized downtime
- Set KPIs for availability and build in operational processes to set alarms when measures aren’t met with corrective actions taken with built-in self-healing
- Closely monitor any environment or system component failure and address any unplanned downtime and breaches
By comparison, the interviewees said they only needed two full-time engineering resources focused on Confluent Cloud, even as demand rises. That’s because we at Confluent have spent millions of hours incorporating expertise into the service, abstracting away all these operational burdens, and bringing the benefits of the cloud without all the infrastructure and availability concerns.
Achieving 10x availability with 99.99% uptime SLA
Confluent Cloud promises 10x higher availability with a built-in 99.99% (“four 9s”) uptime availability SLA for our customers. This is not only one of the industry’s highest SLAs, but the most comprehensive. Why do we say that?
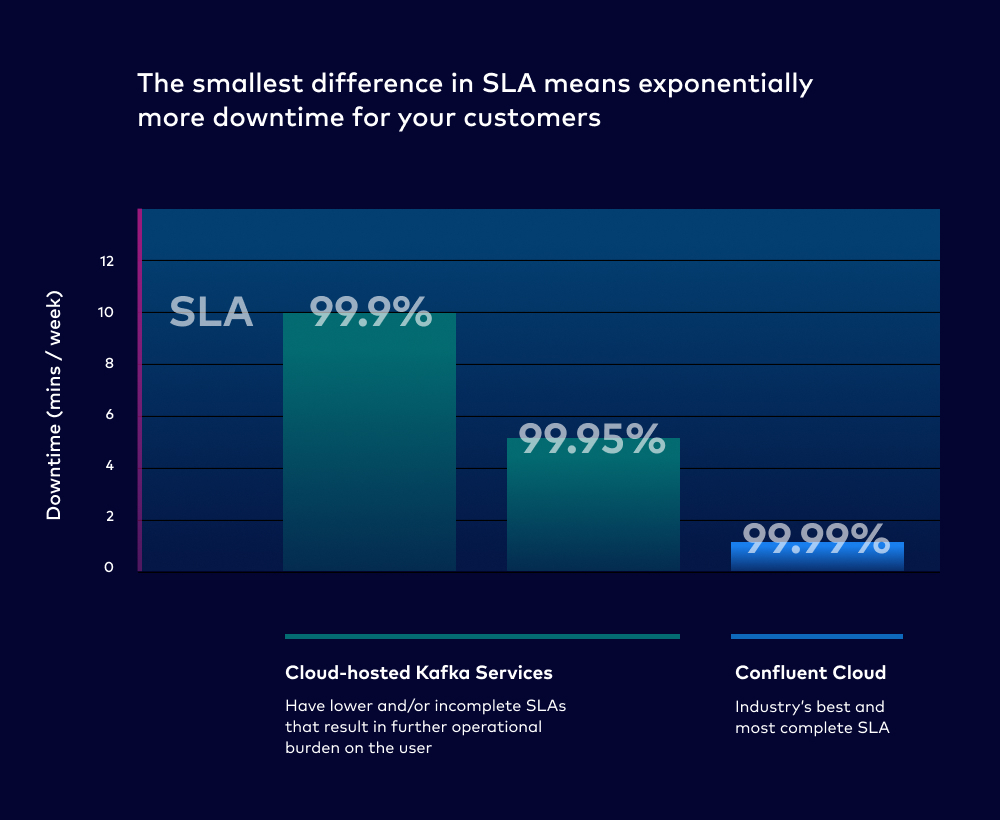
To start, the smallest increase in SLA means exponentially less downtime for your customers. Our example OSS Kafka deployment had a (generous) baseline SLA of 99%, with a potential downtime of 5,262 mins/year. Just two additional “.9s” in Confluent Cloud’s SLA translates to at most 52.6 mins of downtime per year. That’s 100x less downtime, and it’s why we say that Confluent cloud offers beyond 10x better availability than Apache Kafka. This is all built-in to the product: It doesn’t require all the additional FTEs to manually maintain a strong SLA on your own.
But it’s not just about the number; it’s also what is covered. Confluent Cloud’s SLA covers not only infrastructure but also Apache Kafka performance, critical bug fixes, security updates, and more—something no other hosted Kafka service can claim. It means that our systems will stay resilient to almost all major issues that can arise, even in the face of the most public of disasters.
For instance, even when AWS, Azure, and GCP each had outages that affected a cloud zone, which ravaged several critical apps and services, so far in 2022, Confluent Cloud stayed resilient and true to our improved SLA of 99.99% for MZ clusters.
Don’t just take it from us—our customers agree:
“Confluent has enabled us to put our clients’ data into the cloud because it’s resilient and reliable and we know it’s safe. Building our own Kafka capability, leveraging someone else’s Kafka capability was never going to be as resilient and reliable as using Confluent.” – Mark Holt, Chief Product and Engineering Officer, 10x Banking
How did we do this? There are a lot more improvements we’ve made over the years than what we can elaborate on in one blog post, but here are a few areas to highlight:
Built-in multi-zone availability in the product
Building redundancy into the system design is a core strategy to ensure high availability in spite of hardware and/or software failures. For example, while Kafka service is configured to have three replicas for every Kafka topic, we make sure that these three copies are distributed across three different availability zones. This ensures that two copies are available even if an availability zone experiences failures.
In addition, we employ redundancy in the underlying infrastructure where possible. For example, we actively monitor workload and performance metrics to expand or shrink our multi-tenant clusters with excess capacity to handle workload spikes. We also enforce limits to ensure that a multi-tenant user gets the promised quotas despite any “noisy neighbors” from other tenants. We’re always refining the enforcement scheme for these thresholds to better handle highly skewed apps and workloads.
World-class cloud monitoring
Confluent has invested heavily in proactive cloud monitoring to learn about production problems before any workload impact. We monitor each cluster with Health Check that creates synthetic loads that fully emulate the network path and logic that a customer application would follow. The metrics collected are sent to our telemetry pipelines and persisted on a data lake, where we do analysis of the historical data weekly to identify variations and trends.
As a part of the analysis, we also identify any monitoring gaps to understand if there are gaps on our internal alarms (i.e., customer escalations not caught by our monitoring). This helps us build in potential improvements to Kafka as a product, and to the underlying cloud provider services infrastructure and dependencies.
Automation to handle cloud failures
No matter how prepared we are, for various reasons, incidents do occur. When that happens, our first goal is to first mitigate and minimize customer impact. With built-in self-healing automation, Confluent Cloud auto detects the unavailability of cloud service (storage, compute, etc.) and mitigates its impact by appropriately isolating the impacted node/replica. It also auto-rebalances the cluster to add/remove or uneven workload scenarios.
Post-mitigation, we perform a detailed root cause analysis and build improvements to avoid such architectural issues in the future. An outcome of this review is to improve runbooks and monitors, improve test coverage, reduce resolution time, and improve self-healing logic to detect the citation and remediate systematically.
Battle-tested operational processes
For any new design and feature, there is ample focus on developing extensive test plans with the aim to detect any regression before getting to production. In addition to usual unit and integration tests, we use failure injection mechanisms (Trogdor+ChaosMesh) to emulate faults and verify that each release is tolerant to those failures. In the multi-tenant environment, we also include load tests to ensure proper isolation is honored to avoid availability impact due to noisy neighbors.
Build in 20x or 30x availability with Cluster Linking
Confluent Cloud’s built-in multi-zone capability helps mitigate the most common cloud outage: single availability zone failures. But as mentioned above, organizations need even higher availability to defend against another class of failure: a regional outage across public cloud providers.
To further minimize downtime and data loss in a regional outage, we introduced Cluster Linking and Schema Linking to help organizations architect a multi-region disaster recovery plan for Kafka. These built-in features enable Confluent customers to keep data and metadata in sync across 65+ regions within all three major cloud providers, or on their own on-prem infrastructure with Confluent Platform, improving the resiliency of both in-cloud and on-prem deployments. Users can create active-passive or active-active disaster recovery patterns to hit a low RPO (recovery point objective) and RTO (recovery time objective).
Because Cluster Linking is built into fully managed Confluent Cloud clusters, it’s much easier to spin up than MirrorMaker2 (the open source equivalent to replicate data across regions with Apache Kafka) without any extra infrastructure or software. Learn more about how you can easily deploy multi-region disaster recovery and failover strategy with Cluster Linking in just three steps.
Don’t forget about durability
Durability is the other side of resiliency, and is a measure of data integrity. Our customers use Confluent Cloud for their most critical data, and they expect it to remain intact and available when they need it, in the same form when it was written. In measuring durability, a message is considered durable when it is committed to the broker, i.e., it is acknowledged by all in-sync replicas and the high water mark has advanced. Durability score is the percentage of durable messages to the total number of messages.
Apache Kafka primarily guarantees high durability through redundancy—when the data is replicated across brokers—and in some cases across availability zones. We’ve gone far beyond this to build tooling and durability services to detect and mitigate data integrity issues, relieving operators of the burdens of monitoring data integrity themselves. At Confluent, we provide durability for an average of tens of trillions of messages per day.
How did we do this? We took a three-pronged approach to achieve the strictest of durability standards that go far beyond Apache Kafka:
- Prevention: This is the foundation of our durability pillar and which starts by developing a comprehensive threat model to identify potential durability violations in Kafka or Confluent Cloud to different types of data and metadata, and the mitigation plans against these threats. In addition, we run advanced tests to validate and model sensitive operations for the log layer that can lead to changes in the metadata such as storage corruption, unintended metadata divergence, operational or configuration issues, and software bugs.
- Detection: Timely detection of any kind of durability lapse is important, especially considering our critical features such as Infinite Storage that can impact data integrity. We have built a full-featured auditing service that monitors for data loss in real time. This service is able to analyze sensitive operations such as the deletion of data and alert us for any kind of data loss in real time. In addition to this, this service also computes the durability score for our entire fleet providing us a global view of the health of our service. We are continuously enhancing this service to broaden the coverage for different data types as well as different operations to ensure we have the right level of visibility.
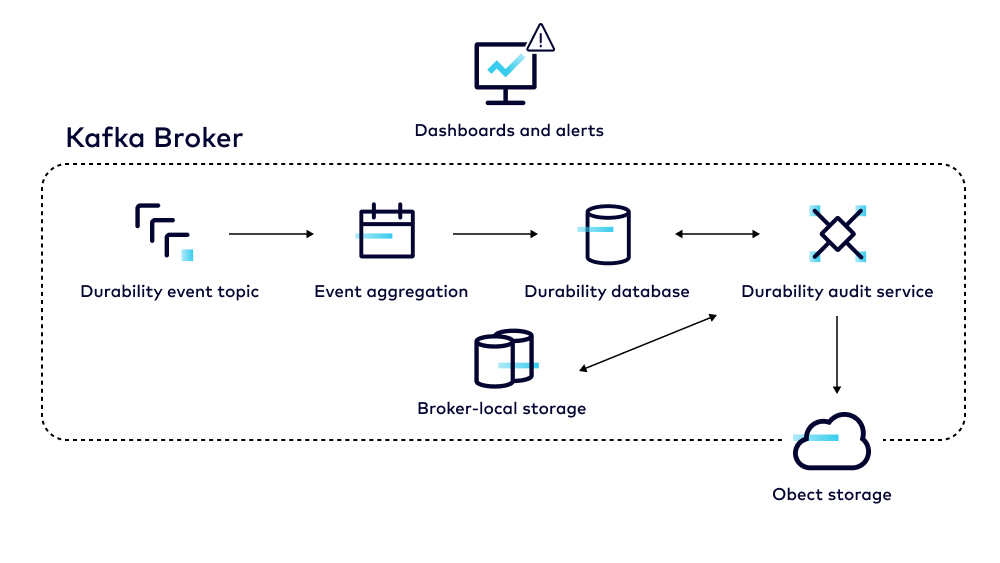
- Mitigation: When any durability lapse is detected, either due to system, operator or service provider errors, we need to be able to mitigate the impact and restore the cluster to a known good state. We have built continuous internal backup of the data, which along with restore allows us to mitigate and restore data at scale across the entire fleet.
Summary
We’ve made Confluent Cloud 10x more resilient than Apache Kafka so you can:
- Offload Kafka operations to a fully managed service that deploys, optimizes, upgrades, patches, and recovers Kafka out-of-the-box
- Significantly reduce downtime, data loss, or data corruption with 99.99% uptime SLA, multi-AZ deployment and a proactive durability audit service
- Accelerate global availability deployments with simplified geo-replication and multi-cloud data movement with Cluster Linking
Hear from more customers about how they have offloaded operational burdens with Confluent Cloud’s built-in resiliency.
To check out other areas where we’ve made Confluent a 10x better data streaming platform, sign up for our latest 10x webinar on Sept 29th to learn from our experts about how to train a ML model with 10x elasticity and storage, or just give Confluent Cloud a go with a free trial.
More posts in this series
- Introduction from our CEO: Making an Apache Kafka Service 10x Better
- Elasticity: Making Confluent Cloud 10x More Elastic Than Apache Kafka
- Storage: Building Kafka Storage That’s 10x More Scalable and Performant
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.