Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Reducing the Total Cost of Operations for Self-Managed Apache Kafka
We kicked off Project Metamorphosis last month by announcing a set of features that make Apache Kafka® more elastic, one of the most important traits of cloud-native data systems. This month, we’re focusing on another important trait of cloud-native data systems: cost effectiveness.
Reducing costs and operating efficiently is always a top priority for businesses, especially for the data architecture that underpins the digital side of a business, such as Kafka. Although Kafka is free to download, modify, use, and redistribute, managing a complex distributed system at scale still comes with substantial costs. We can bucket these costs into three broad categories:
- Infrastructure costs: includes the compute, storage, and networking resources allocated to a Kafka cluster. The cloud has made infrastructure utilization more efficient, but the costs can still add up as event streaming spreads throughout an organization, additional clusters are spun up, and more and more data is sent into Kafka. Deploying Kafka on premises often exacerbates the costs.
- Operational costs: includes allocating engineering resources for managing Kafka rather than building event streaming applications or other high-value projects for the business. In addition to requiring engineers to build components and tools for a more complete event streaming architecture, Kafka requires several engineers to operate the platform once it has been deployed.
- Downtime costs: includes costs associated with unexpected cluster failures and maintenance. While some choose to ignore these costs because they are difficult to quantify, their significance becomes abruptly apparent when an incident does occur. Downtime costs can also have latent long-term consequences, including reputational damage, reduced customer satisfaction, data loss, and other negative outcomes resulting from a lack of regulatory compliance.
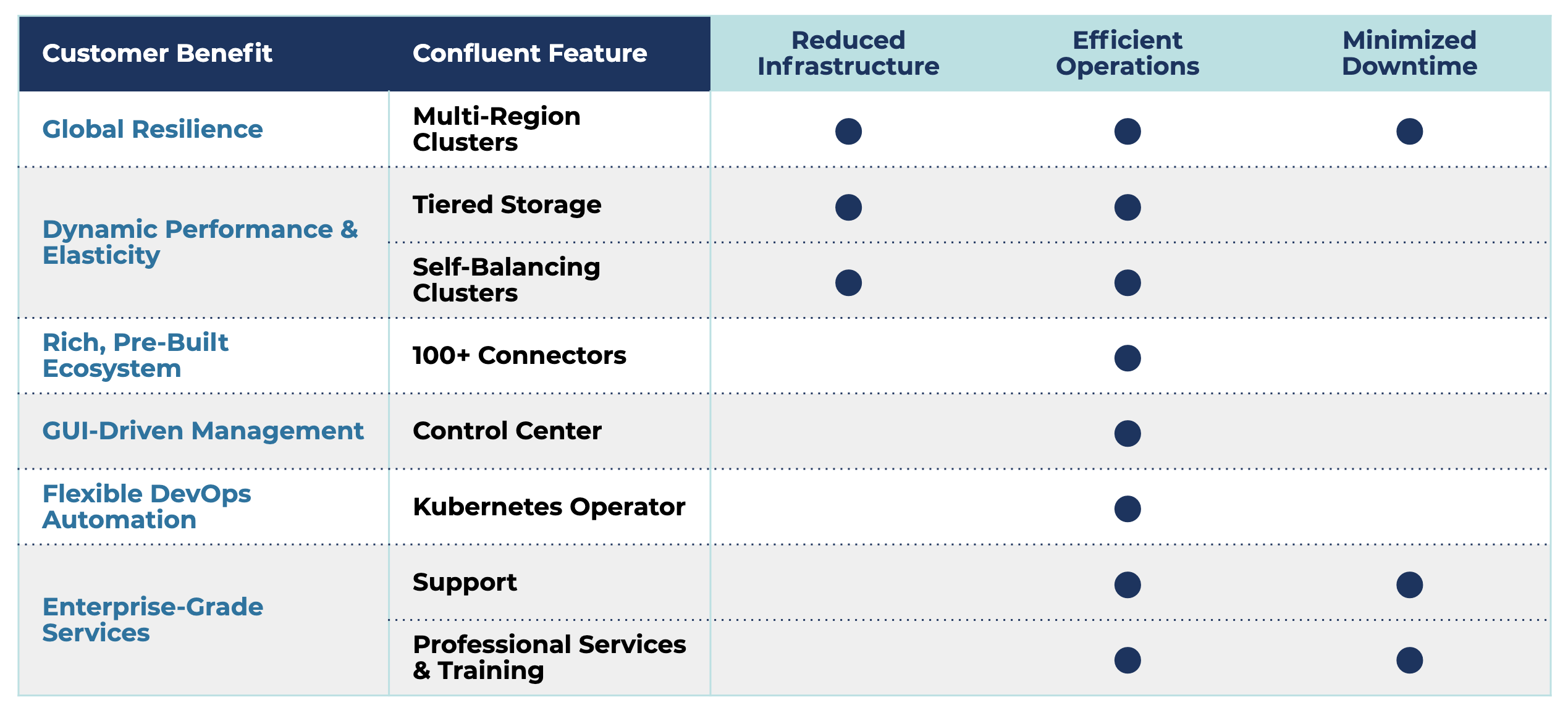
While no software offering can compete with the cost savings offered by a fully managed cloud offering like Confluent Cloud, Confluent Platform includes a number of essential features that make self-managed Kafka clusters vastly more cost effective than implementing the open source software alone. Cumulatively, a Confluent Platform subscription can reduce the total cost of ownership for self-managing Kafka by up to 40%. Let’s walk through how these Confluent Platform features impact the three cost categories highlighted above.
Infrastructure costs
To start, there are several Confluent Platform features that can greatly reduce your Kafka cluster’s infrastructure footprint. For use cases involving high data ingestion rates, lengthy data retention periods, or stringent disaster recovery requirements, Confluent Platform can help to reduce infrastructure costs by up to 50%.
One of the most important features for this cost category is Tiered Storage. Tiered Storage allows Kafka to recognize two tiers of storage: local disks and cost-efficient object stores, such as Amazon S3 or Google Cloud Storage (GCS). This enables you to offload older topic data from expensive broker storage to inexpensive object storage, significantly reducing storage costs. Tiered Storage also decouples the storage and compute layers in Kafka, enabling you to scale storage without having to scale compute, and vice versa. Now when you expand storage in your cluster, you can use the more cost-effective storage tier and avoid having to pay for additional local disks.
Self-Balancing Clusters, an upcoming feature planned for the next Confluent Platform release, further reduces Kafka’s infrastructure footprint. Self-Balancing Clusters fully automates partition reassignments, ensuring the data that remains on Kafka brokers is evenly distributed across the cluster. By preventing data from becoming skewed, the cluster optimizes its utilization of infrastructure resources. Self-Balancing Clusters complements Tiered Storage to allow for even greater infrastructure savings. By making Kafka more elastically scalable, clusters can scale up and scale down quickly depending on the load at the time. This means businesses can avoid over-provisioning resources up front and only have to pay for infrastructure when they actually need it.
Finally, Multi-Region Clusters reduce the infrastructure needed for multi-datacenter Kafka deployments. Introduced in Confluent Platform 5.4, Multi-Region Clusters enable you to run a single Kafka cluster across multiple datacenters, allowing much faster recovery times and greatly reducing costs associated with downtime (we’ll come back to this later). In terms of its impact strictly on infrastructure costs, Multi-Region Clusters leverage Kafka’s internal replication engine to durably replicate partitions across multiple datacenters rather than needing to deploy a separate Kafka Connect based replication tool. In other words, you no longer need to pay for additional machines to replicate your data to multiple locations.
Operational costs
Confluent Platform can also help you reduce the number of hours spent both on building out components to make Kafka an enterprise-ready event streaming platform and managing the platform. Whether you’re just starting out with Kafka or looking to reduce the operational burden of existing clusters, Confluent customers can reduce their operational costs by up to 45% by leveraging our feature set and services. For many customers, infrastructure and operational savings can completely cover the cost of a Confluent subscription.
Building out an event streaming platform almost always requires, at minimum, developing connectors and integrating with a GUI. Developing connectors can be complex and time consuming, and some built by the community require ongoing maintenance. Integrating with a GUI is often more straightforward but requires thought as to what metrics need to be highlighted to effectively monitor and manage the cluster. That’s why Confluent Platform includes 100+ pre-built Kafka connectors and Control Center, our web-based GUI for management and monitoring of Kafka clusters, so your developers can start building event streaming applications that change your business rather than first needing to complete these lengthy, mundane tasks.
Once platform development is complete, a lot of time is needed to operate Kafka. Responsibilities for DevOps and platform teams include configuring, deploying, upgrading, scaling, and maintaining the uptime of the cluster. These tasks are manual and time intensive, requiring time that could otherwise be spent on other high-value projects for the business. Confluent Operator, which simplifies running Confluent Platform as a cloud-native system on Kubernetes, reduces the operational burden here.
First, it automates the configuration and deployment of Confluent Platform using a standardized, validated architecture that is based on years of experience running 4,500+ clusters for Confluent Cloud. Second, it automates rolling upgrades after a Confluent Platform version, configuration, or resource update, without impacting Kafka availability. Finally, it is capable of expanding a Kafka cluster with a single command, transforming the scaling process from one that is manual to one that is fully automated and elastic.
Confluent Support, Professional Services, and Training complement these features to further reduce the time needed for both platform development and operations. With over 1 million hours of technical experience with Kafka, Confluent can help customers quickly ramp up on Kafka fundamentals, integrate Kafka into their existing architecture, ensure the platform’s configuration meets best practices, and greatly reduce the time spent on troubleshooting and maintenance.
Downtime costs
Confluent Platform can have an enormous impact on downtime costs, our last major cost category. While downtime costs vary based on the customer and their use case, they are almost always substantial and must be accounted for, even if an unexpected event has not yet occurred. For the typical customer, Confluent Platform can reduce downtime costs by up to 60%, before even considering the hidden costs of downtime.
To minimize downtime costs, Confluent Platform offers Multi-Region Clusters as a next-gen disaster recovery solution. Multi-Region Clusters include automated client failover, so your producers and consumers can automatically fail over to the recovery site upon failure.
What does this mean for your Kafka operators? No need to deploy a separate Connect cluster, no offset translation, no DNS reconfigurations, no failover logic for clients, and far less planning for disaster recovery. It also means that recovery time objectives (RTOs) can be measured in seconds rather than hours when using a Connect-based replication tool. And for use cases where data cannot be lost, Multi-Region Clusters allow you to choose between synchronous and asynchronous partition replication on a per-topic basis, thus enabling recovery point objectives (RPOs) of zero for topics with your most sensitive data.
Much like for operational costs, Confluent Support complements our disaster recovery features to further reduce downtime costs. When a failure occurs, Confluent is available 24/7 to get your cluster back online. Having resolved thousands of issues for customers and learning from operating 4,500+ of our own clusters with a 99.95% uptime SLA in Confluent Cloud, Confluent can provide a targeted support experience to not only fix the issue but also ensure it does not reoccur.
Conclusion
In summary, Confluent Platform offers a complete set of enterprise-grade features and services that can help your business greatly reduce the total cost of ownership of self-managing Kafka. After summing up costs for infrastructure, operations, downtime, and a Confluent subscription, the total cost of ownership can be reduced by up to 40%, thus covering the cost of a Confluent subscription many times over. This, of course, is in addition to helping you succeed in your Kafka initiative with greater speed and reduced risk.
To learn about other work that is happening to make Kafka cost effective, check out the Cost Effective page as part of Project Metamorphosis.
Further reading
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.