Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
ksqlDB 0.12.0 Introduces Real-Time Query Upgrades and Automatic Query Restarts
The ksqlDB team is pleased to announce ksqlDB 0.12.0. This release continues to improve upon the usability of ksqlDB and aims to reduce administration time. Highlights include query upgrades, which let you evolve queries even as they process events, and automatic restarts for persistent queries when they encounter errors.
Below, we’ll step through the most noteworthy changes. Check out the changelog for the complete list, including bug fixes and other enhancements.
Updating persistent queries with “CREATE OR REPLACE”
ksqlDB has many supported operations for persistent queries, including the ability to filter results with a WHERE clause. But what happens when you would like to change the filtering criteria? Previously, such a change would require terminating the query and recreating an updated version with the new criteria. With ksqlDB 0.12.0, you can now modify an existing query in place and not miss a beat in processing your streams.
WHERE clause expression upgrades
Let’s look at a motivating example. Imagine a query that reads from a stream of purchases made at ksqlDB’s fictional flagship store, ksqlMart, and filters out transactions that might be invalid:
CREATE STREAM purchases (product_id INT KEY, name VARCHAR, cost DOUBLE, quantity INT); CREATE STREAM valid_purchases AS SELECT * FROM purchases WHERE cost > 0.00 AND quantity > 0;
Over time, ksqlMart changes its return policy and begins issuing full refunds. These events have a negative cost column value. Since these events are now valid, ksqlMart needs to update the query to remove the cost > 0.00 clause:
CREATE OR REPLACE STREAM valid_purchases AS SELECT * FROM purchases WHERE quantity > 0;
This CREATE OR REPLACE statement instructs ksqlDB to terminate the old query and create a new one with the new semantics. The new query will continue from the last event that the previous query processed. ksqlDB supports nearly all upgrades to WHERE clause expressions.
Schema upgrades
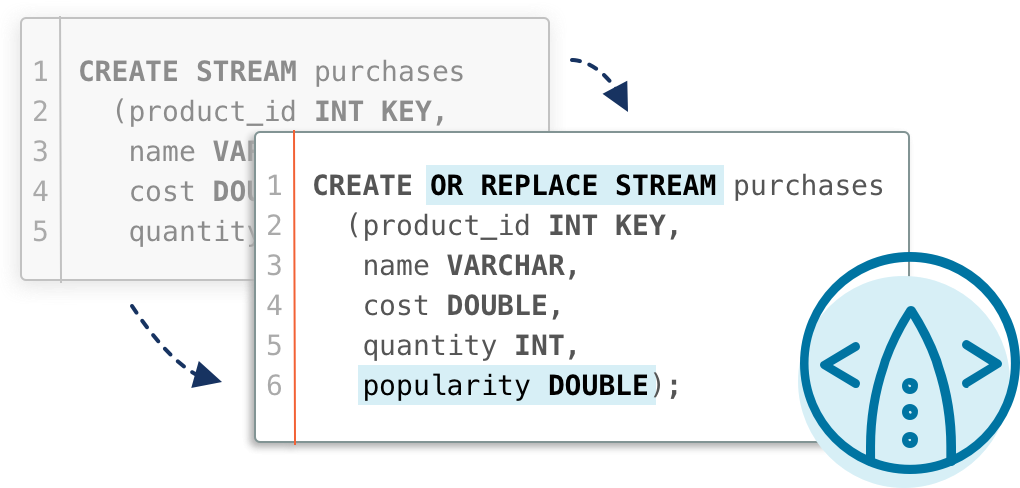
As time goes on, let’s imagine ksqlMart gets more sophisticated in their usage of Apache Kafka® to monitor their input. They start publishing a new field to the purchases stream, named popularity. In order to reflect this change in their valid_purchases stream, they need to issue two different commands:
CREATE OR REPLACE STREAM purchases (product_id INT KEY, name VARCHAR, cost DOUBLE, quantity INT, popularity DOUBLE); CREATE OR REPLACE STREAM valid_purchases AS SELECT * FROM purchases WHERE quantity > 0;
The first statement adds the field popularity to the stream purchases, while the second statement ensures that the SELECT * expression is reevaluated so that popularity is added to valid_purchases as well.
With these two powerful upgrade mechanisms, queries can adapt as your uses evolve, and, most importantly, your updated queries pick up right where they left off! For more details and examples on this feature, read the documentation.
Auto restarts for persistent queries
While processing data in a persistent query, the system can sometimes hit a condition that prevents the query from making progress, putting it into an ERROR state. Perhaps you’ve encountered this yourself due to transient networking issues or a Kafka ACL change, for example.
Historically, this scenario has required a restart of your server (and all the running persistent queries) to recover the one query that has exited with a transient error.
Starting with ksqlDB 0.12.0, the persistent queries will automatically be restarted and begin where they left off. This often reduces operational burden and saves time and resources because intervention isn’t required. More details can be found on GitHub.
Get started
Get started with ksqlDB today, via the standalone distribution or with Confluent Cloud, and join the community in our #ksqldb Confluent Community Slack channel.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.