Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Introducing Confluent Platform 5.0
We are excited to announce the release of Confluent Platform 5.0, the enterprise streaming platform built on Apache Kafka®. At Confluent, our vision is to place a streaming platform at the heart of every modern enterprise, helping infrastructure owners get the most out of Kafka and empowering developers to build powerful applications with real-time, streaming data. With a comprehensive streaming platform, companies can better integrate all their disparate data sources into a single source of truth and respond in real time to every event affecting the business.
Since the release of Confluent Platform 1.0, we have provided an enterprise-class streaming platform that includes the latest in streaming technology based on Apache Kafka. Our latest release introduces significant new capabilities, from making infrastructure more secure, reliable and easier to manage, to enabling more powerful applications with streaming data.
With Confluent Platform 5.0, operators can secure infrastructure using the new, easy-to-use LDAP authorizer plugin and can deliver faster disaster recovery (DR) thanks to automatic offset translation in Confluent Replicator. In Confluent Control Center, operators can now view broker configurations and inspect consumer lag to ensure that they are getting the most out of Kafka and that applications are performing as expected.
We have also introduced advanced capabilities for developers. In Confluent Control Center, developers can now better understand the data in Kafka topics due to the new topic inspection feature and Confluent Schema Registry integration. Control Center presents a new graphical user interface (GUI) for writing KSQL, making stream processing more effortless and intuitive as well. The latest version of KSQL itself introduces exciting additions, such as support for nested data, user-defined functions (UDFs), new types of joins and an enhanced REST API. Furthermore, Confluent Platform 5.0 includes the new Confluent MQTT Proxy for easier Internet of Things (IoT) integration with Kafka. The latest release is built on Apache Kafka 2.0, which features several new functionalities and performance improvements.
Download Confluent Platform 5.0
Operate more secure, reliable and performant Apache Kafka
Operationalizing enterprise infrastructure is hard, and Apache Kafka is no exception. Our mission at Confluent is to make managing Kafka easy, and the latest release of Confluent Platform helps operators do just that.
Secure Kafka using the new LDAP authorizer plugin and control feature access in Confluent Control Center
As customers adopt Confluent Platform for their mission-critical data, security becomes an important consideration. Operators need to be able to easily manage user access to sensitive data, but doing so in Kafka has historically been difficult. Because security is top-of-mind for many of our customers, we have made several investments to improve security management in Confluent Platform and will continue providing new security features in later releases.
The majority of enterprises standardize on AD/LDAP for identity-related services. The latest release of Confluent Platform introduces an LDAP authorizer plugin to set up access control for Kafka, allowing customers to use the user-group mappings in their LDAP server. The plugin works with any security protocol by mapping an authenticated user principal to one or more groups and allowing user-principal-based ACLs, as well as group-based ACLs. This simplifies access control management because a smaller number of rules can be used to manage access to groups or organizations.
Enterprises also need to ensure that end users cannot access sensitive data via Control Center for security and compliance reasons. In order to let administrators control application-wide access to features that reveal topic data, we have included feature access controls for topic inspection, schemas, and KSQL. When customers restrict access to a feature via the configuration file, Control Center’s UI will reflect this change upon startup, and users cannot circumvent these protections in any way.
Minimize disaster recovery time with automatic offset translation in Confluent Replicator
The disaster recovery (DR) response process is complex. Operators need to ensure that the data is replicated, applications failover, and applications then switch back when the original data center (DC) has recovered. Replicator supports operators along each step of the process by providing automation that minimizes the work needed during a DR response.
Replicator already automates the replication of topic messages and related metadata. With Confluent Platform 5.0, it also ensures that consumer offsets are available on the secondary cluster. When consumer client applications failover to the secondary cluster, Replicator handles consumer offset translation so that they can resume consuming near the last point they stopped consuming at in the original cluster. This minimizes the reprocessing that consumers needs to do in a disaster scenario without skipping messages.
To facilitate application failover and switch back in Confluent Platform 5.0, Replicator adds support for protection against circular replication. This guarantees that if two Replicator instances are configured to run, one replicating from DC1 to DC2, and the second instance configured to replicate from DC2 to DC1, Replicator will ensure that messages replicated to DC2 are not replicated back to DC1, and vice versa. As a result, Replicator safely runs in each direction.
Monitor more and manage better using Confluent Control Center
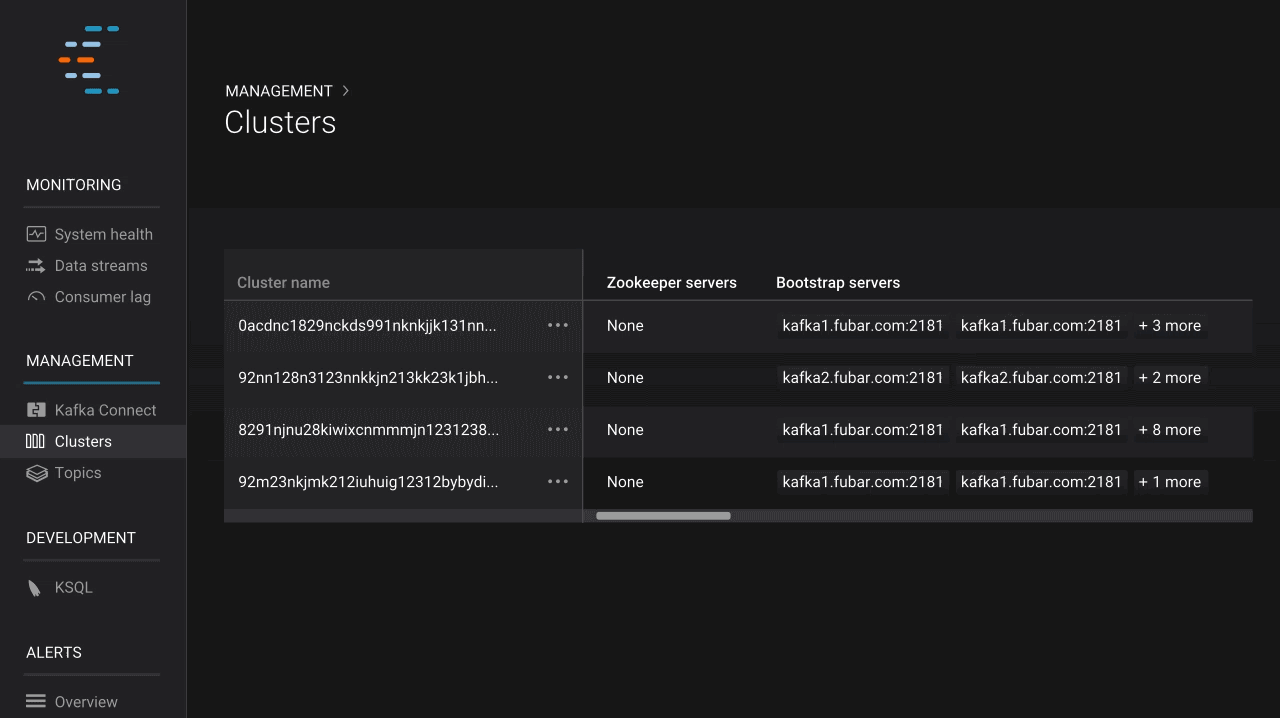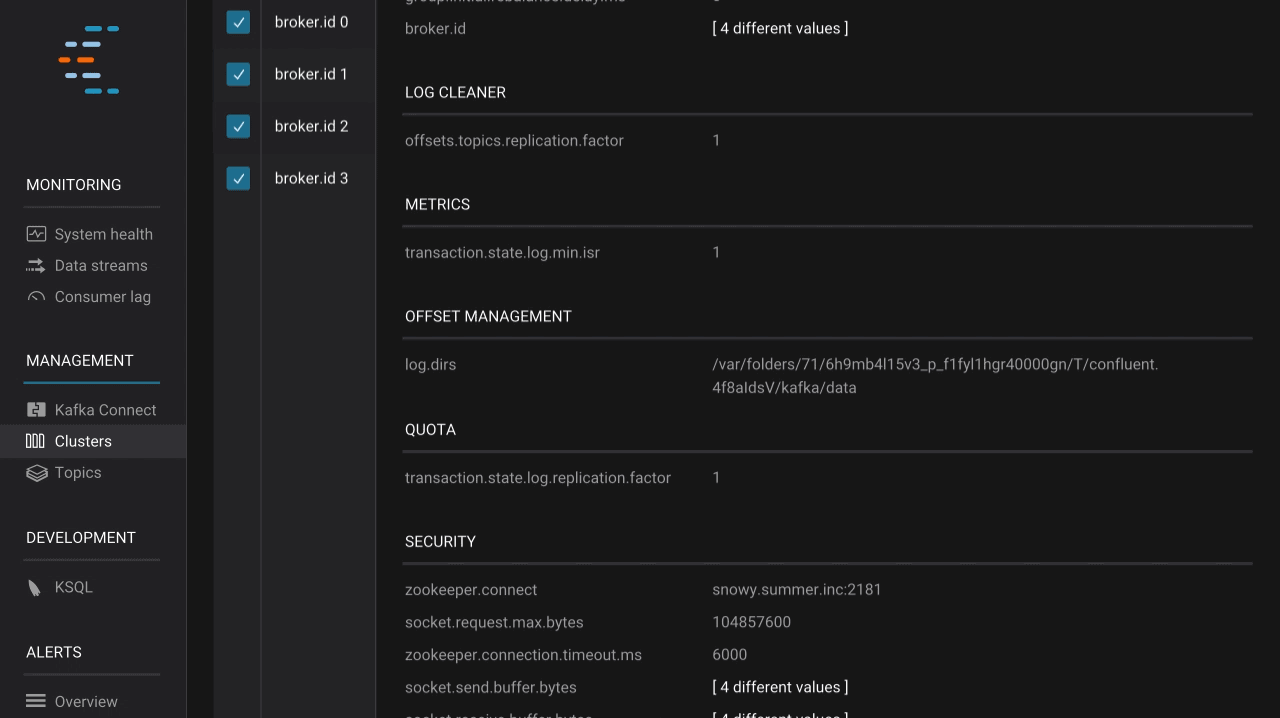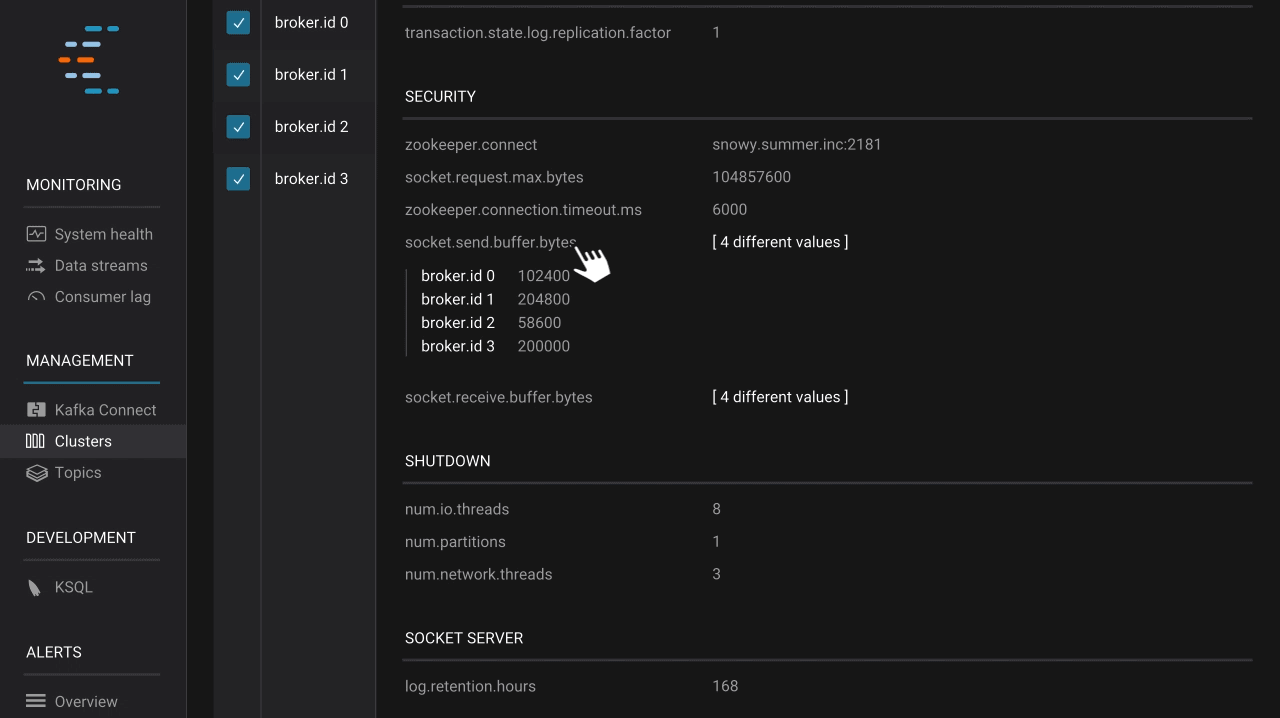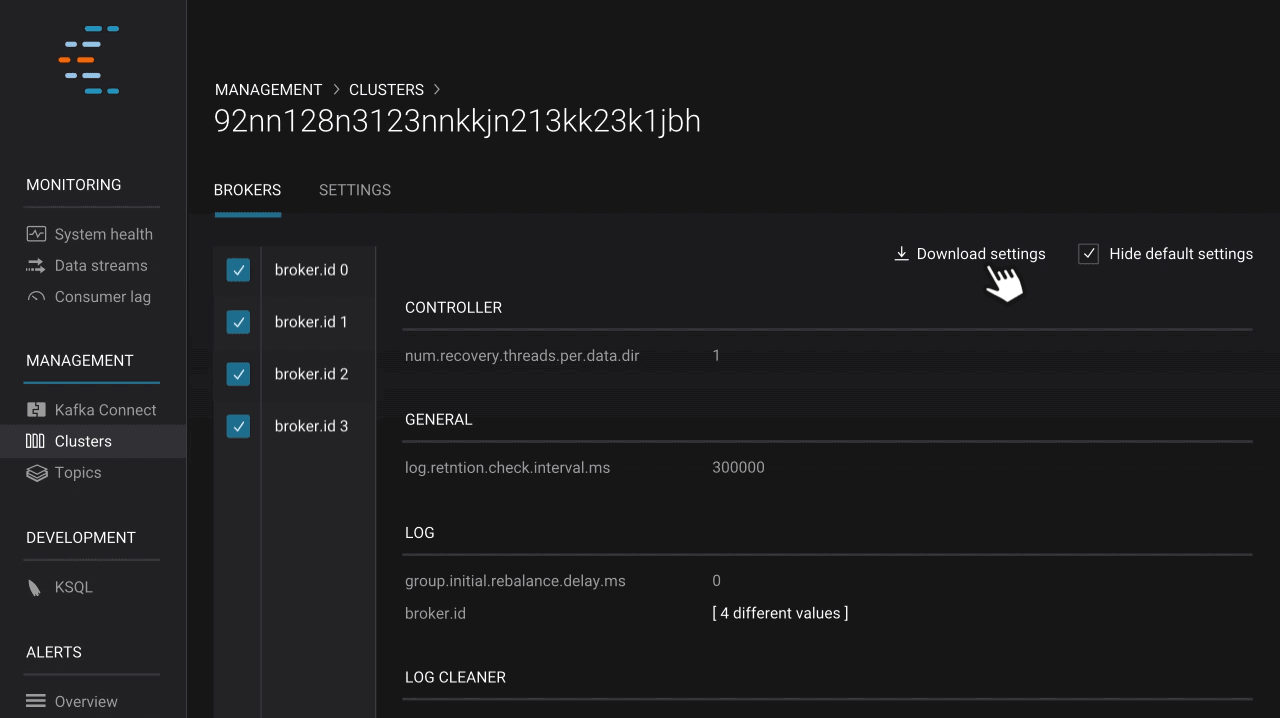
We built Control Center to deliver understanding and insight into the inner workings of Apache Kafka and streaming data, helping operators monitor and manage their Kafka installations as well as possible. Confluent Platform 5.0 introduces a broker configuration view that ultimately improves this experience. It empowers operators to see broker configurations across multiple Kafka clusters, check configuration values for specific brokers, compare differences within a cluster to identify potential risks such as mismatched security configurations in different brokers, and even download configurations. This new feature helps operators ensure that their brokers are set up correctly, enabling them to get the most out of Kafka.
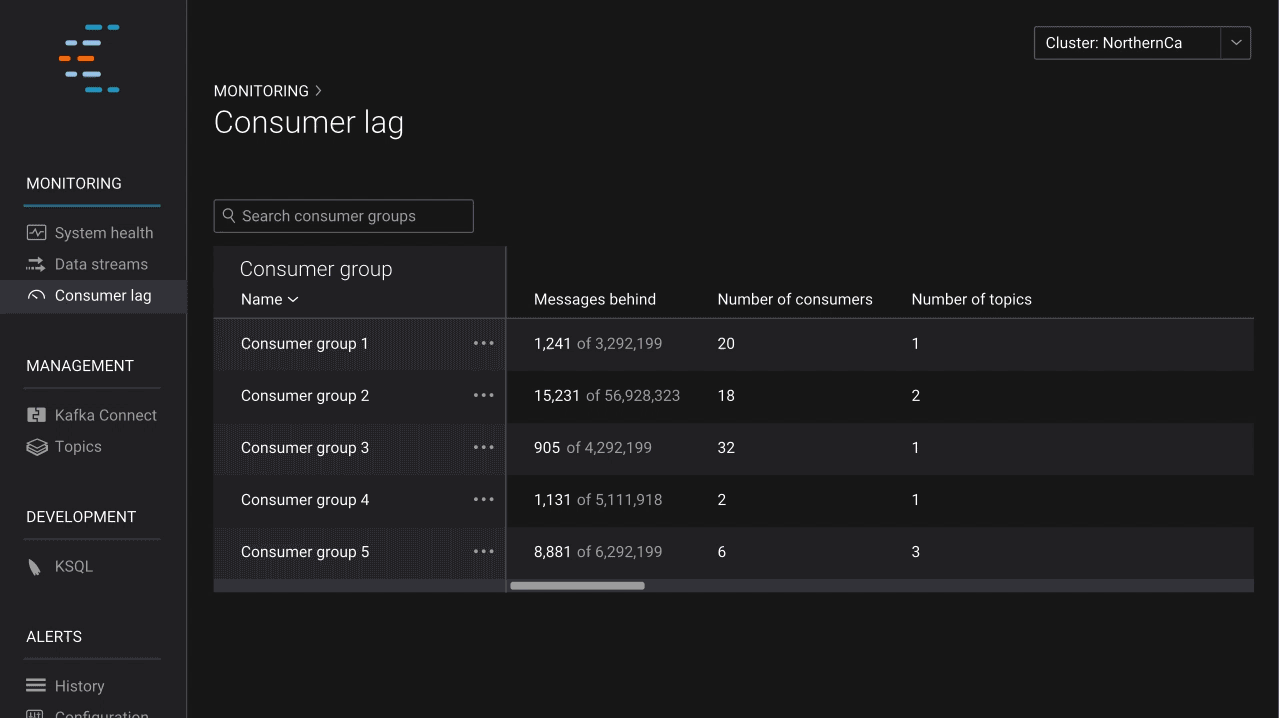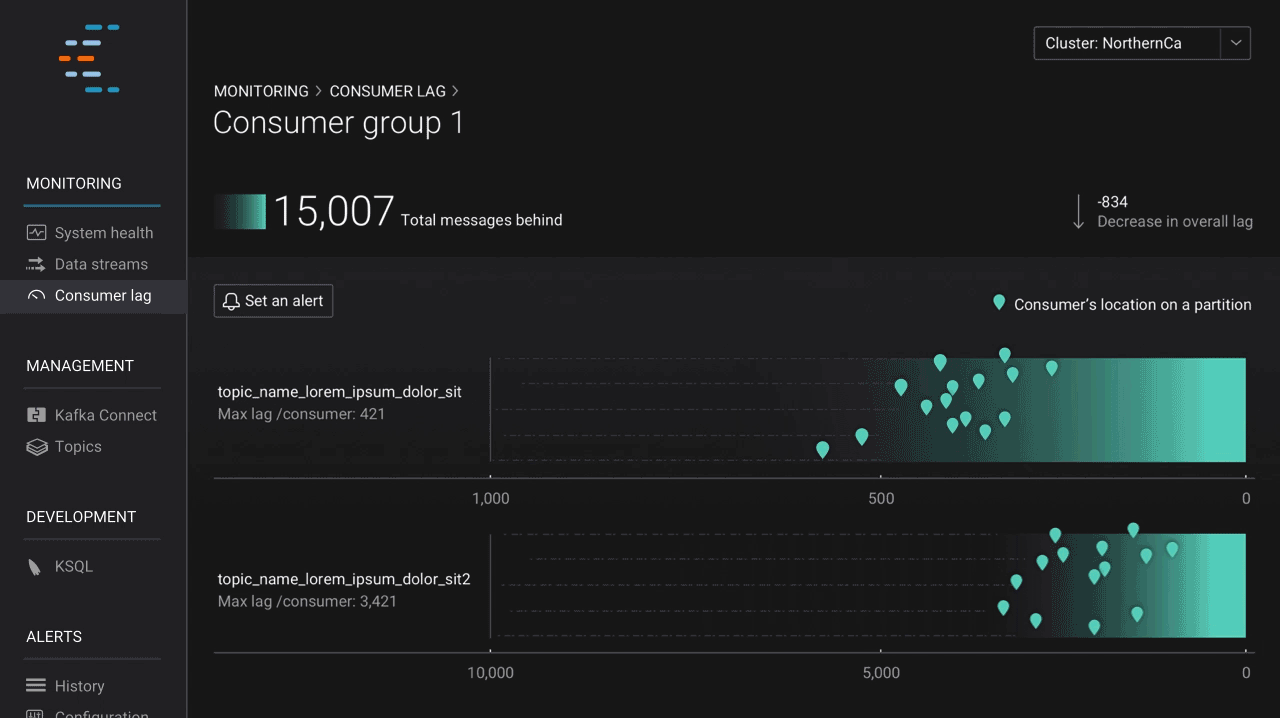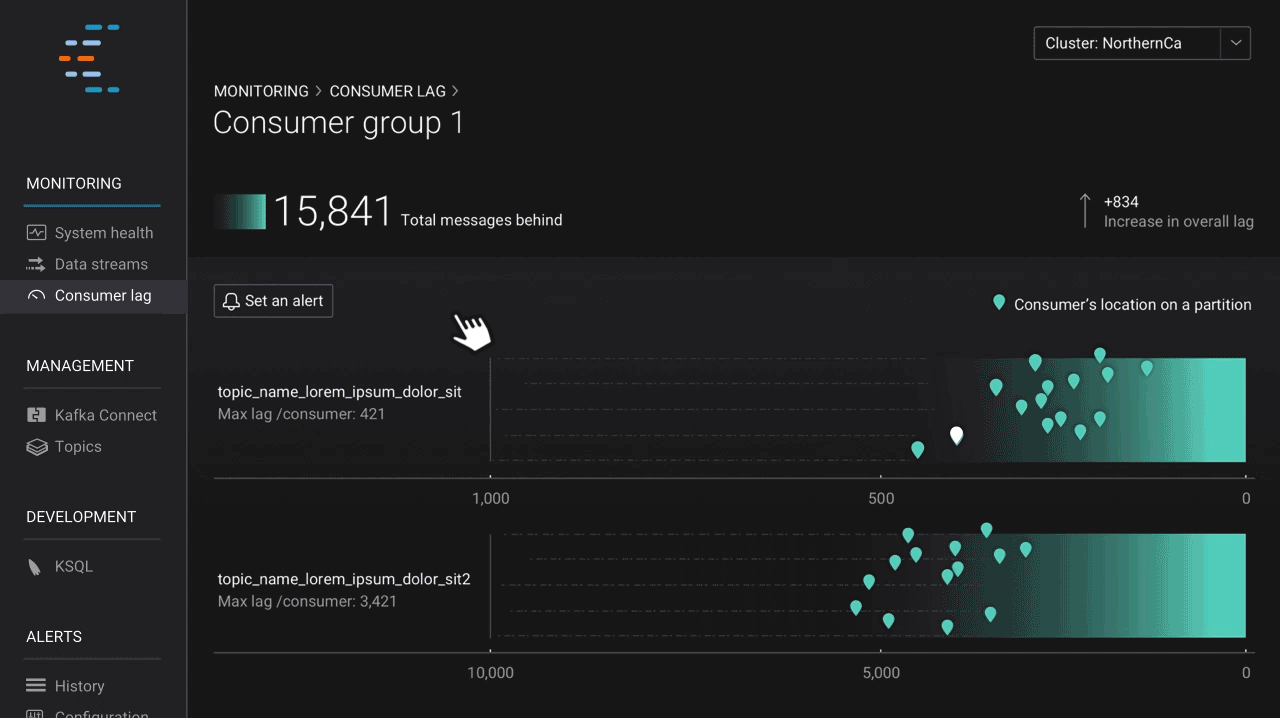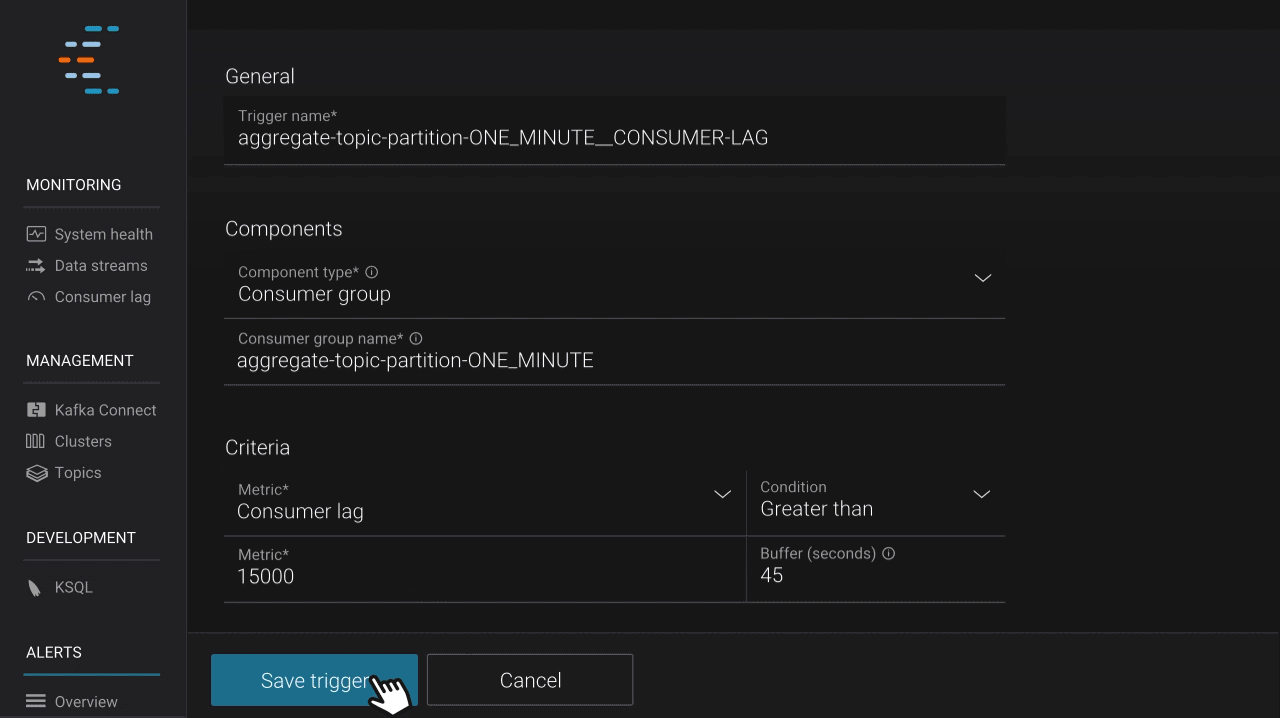
Once you have configured Kafka the way you want and have applications consuming data from topics, it’s important to understand how those applications are performing. Monitoring application performance is something that both operators and developers care about. Since its genesis, Control Center has included an advanced stream monitoring feature, which provides insight into end-to-end performance of the produce-consume cycle. In the latest release, we introduce consumer lag, which allows users to view how consumers are performing based on offset, spot potential issues at a glance, and take proactive steps to keep performance high. Users can also set alerts to monitor lag behind-the-scenes and notify them if issues arise.
Build more powerful streaming applications with Kafka
Having a secure, reliable, and performant Kafka infrastructure is the first part of being successful with streaming data, but it’s not enough. Along with helping enterprises better monitor and manage Kafka, we strive to make building applications with streaming data straightforward, seamless and fast. Confluent Platform 5.0 delivers new capabilities for application developers in both Control Center and KSQL.
Understand and process streaming data with Confluent Control Center
Control Center now allows users to gain insight into the actual data in Kafka topics via a new topic inspection feature. Users can see the streaming messages in topics and read key, header, and value data for each message. Thanks to integration with Schema Registry, topic inspection supports JSON, string, and Avro data formats.
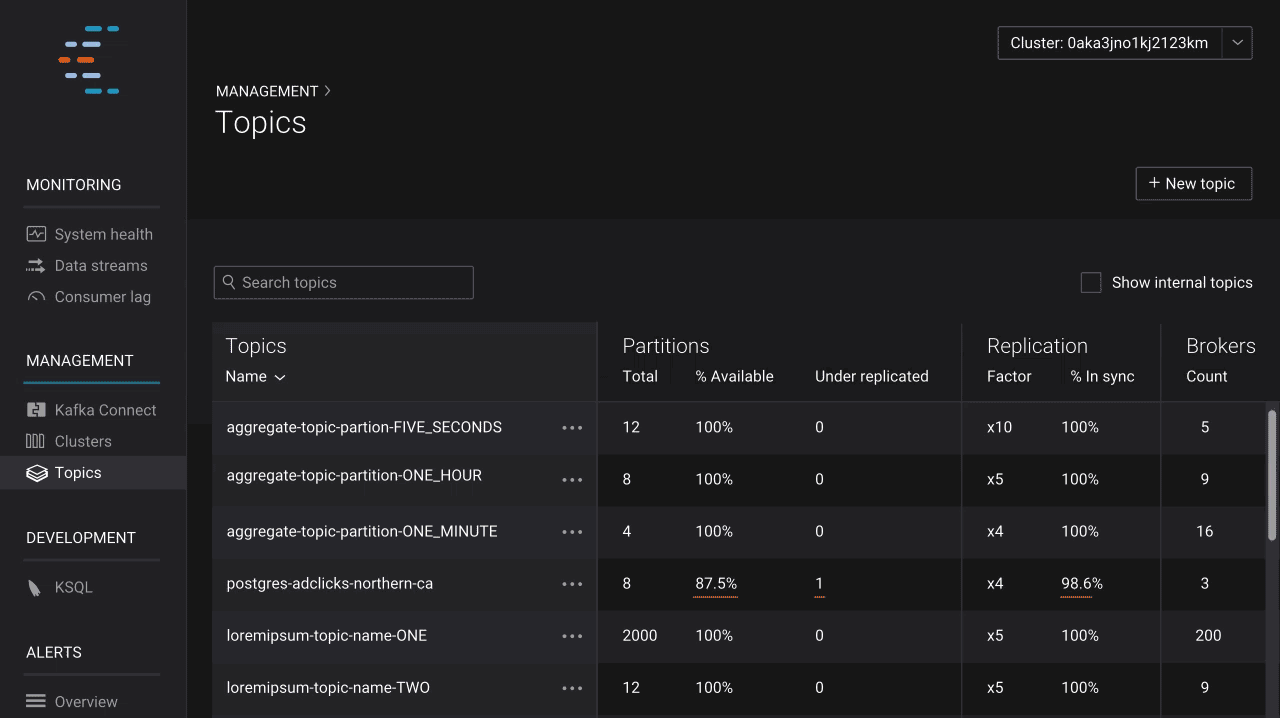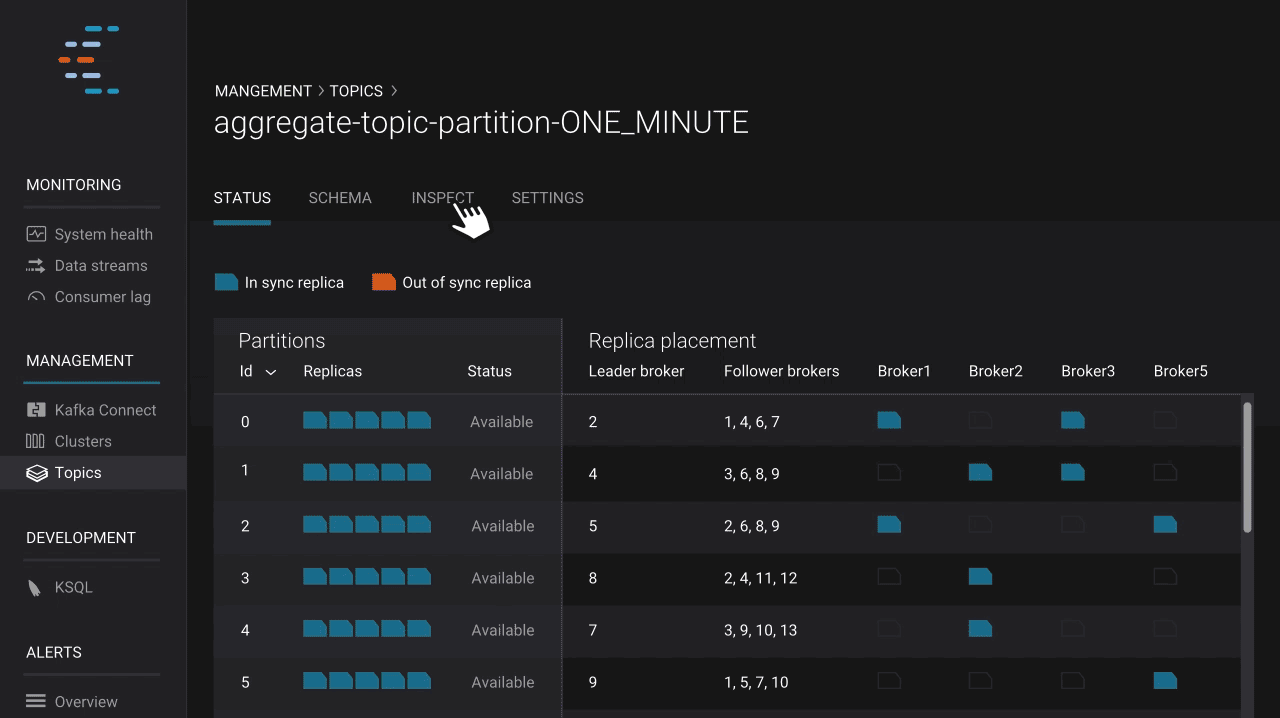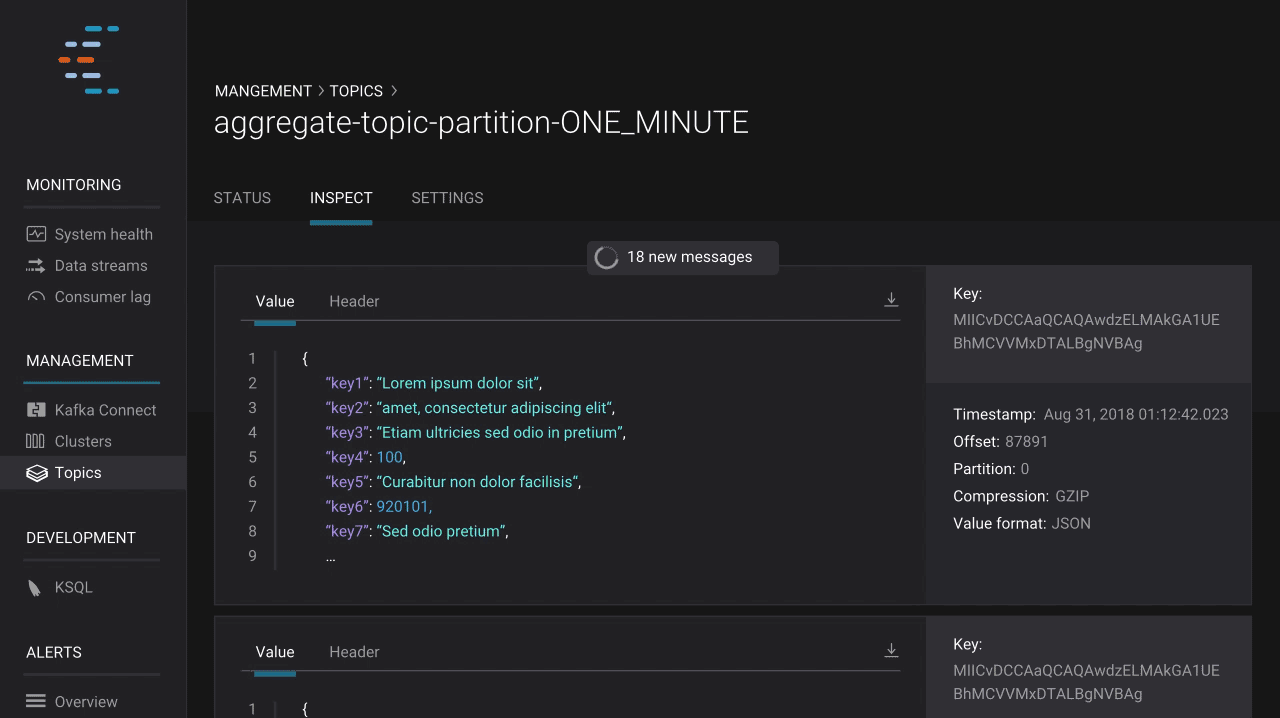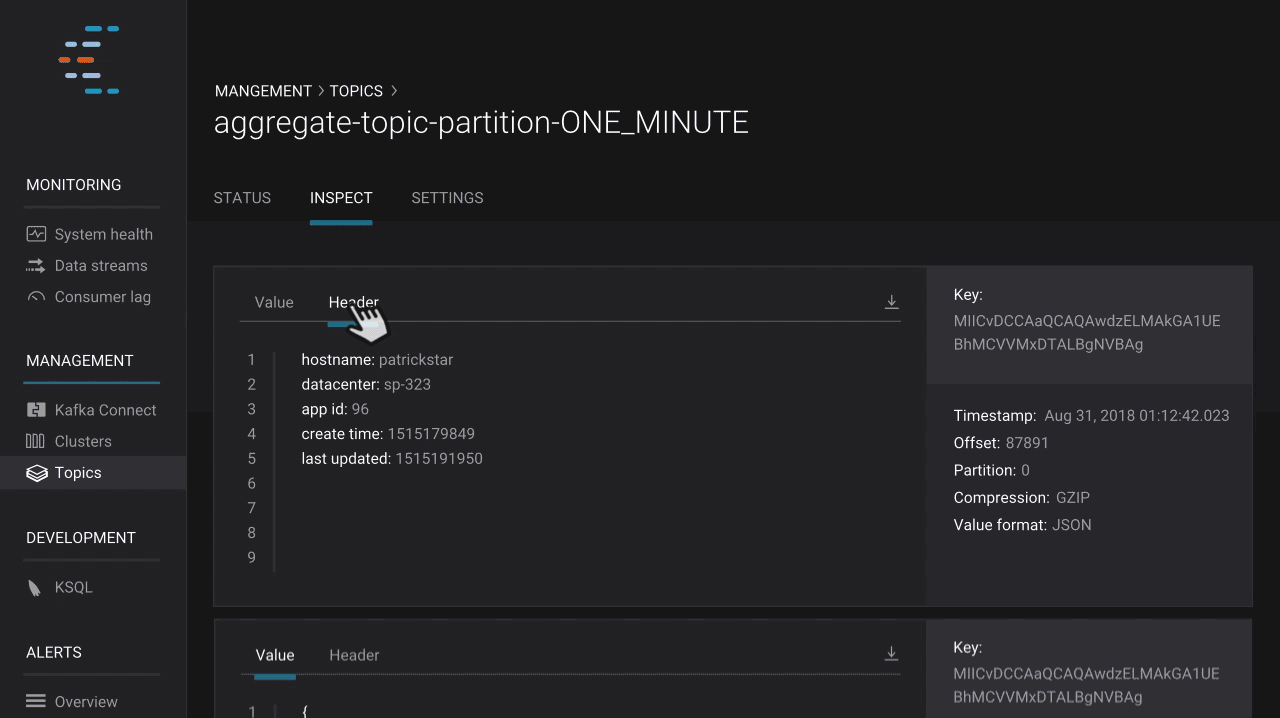
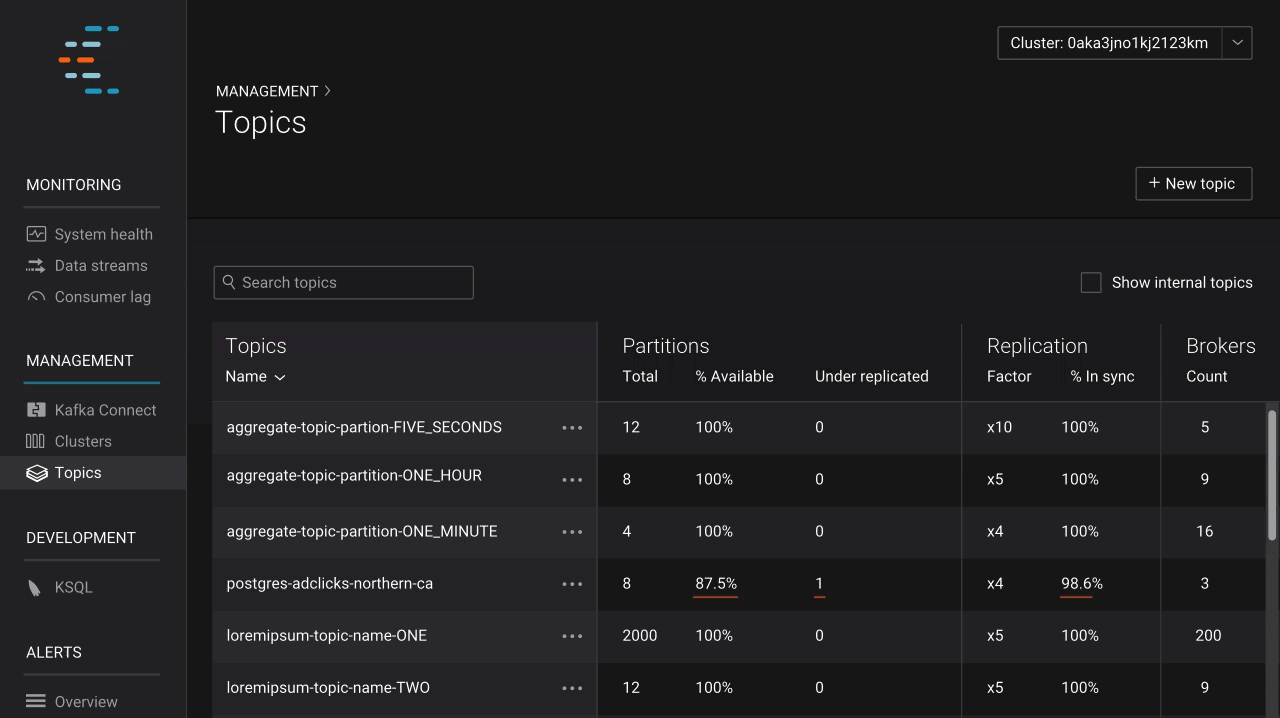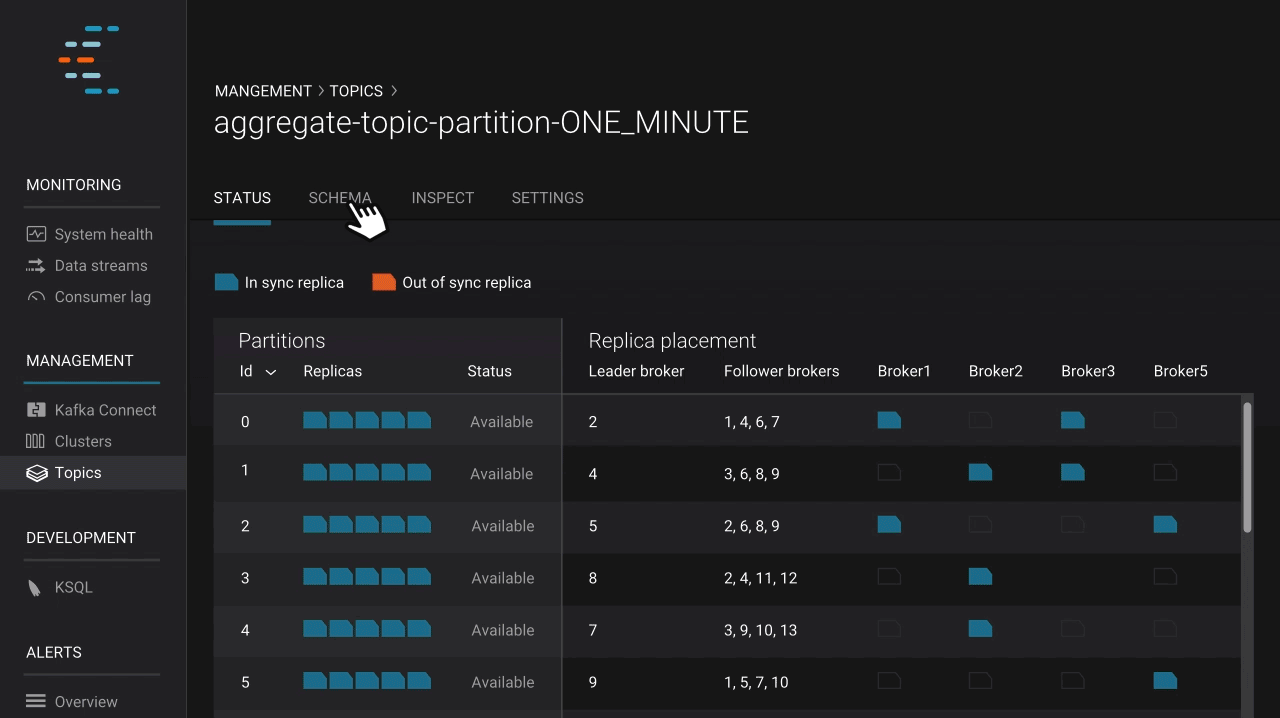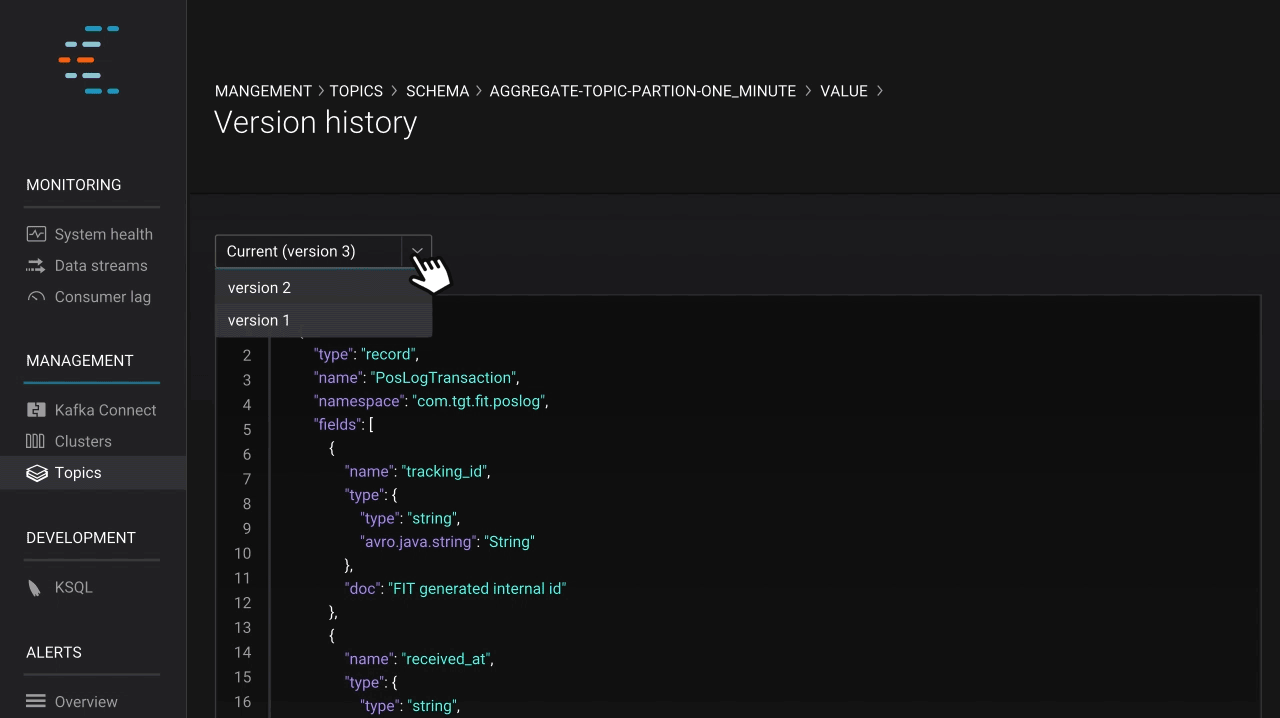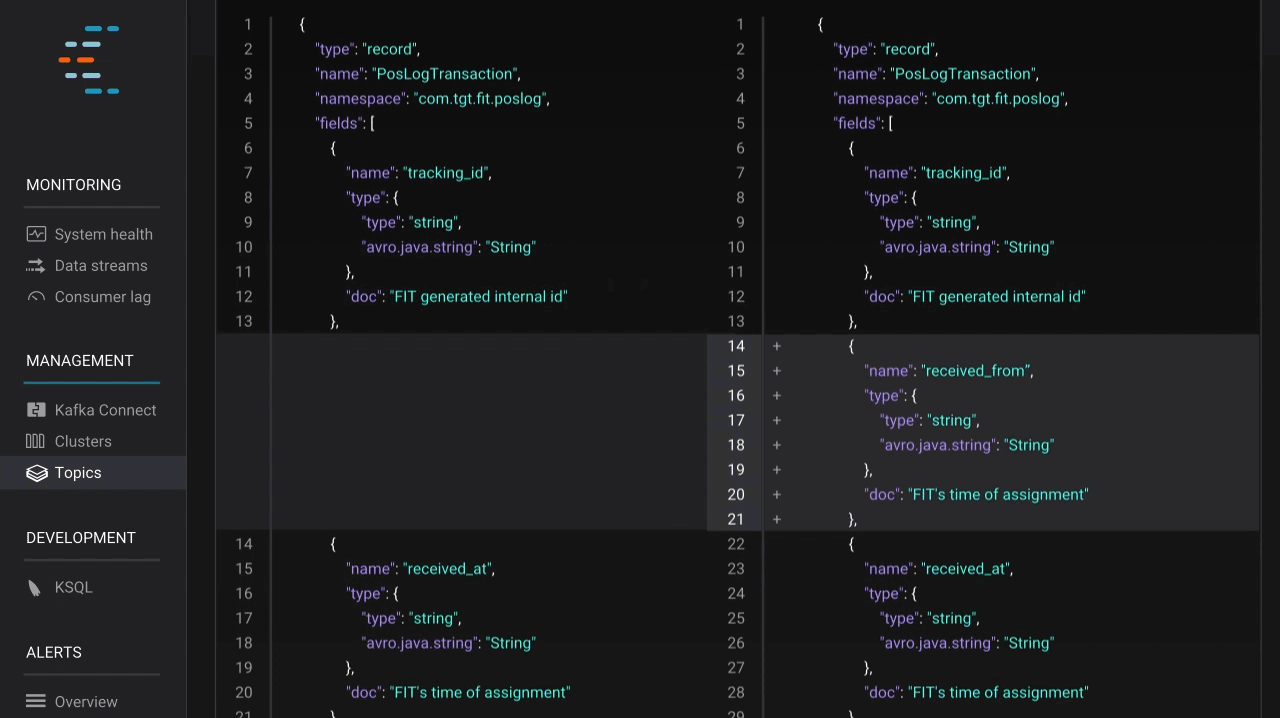
In addition to viewing message data, developers also need to understand how data is organized in order to build applications with Kafka. This need to understand data structure and manage compatibility quickly grows in importance as an enterprise scales up with Kafka. Confluent Schema Registry is a valuable tool for coordinating teams of developers, and makes managing a real-time streaming platform with multiple connected applications seamless. With the latest release of Confluent Platform, Control Center integrates with Schema Registry and allows users to see the key and value schemas for topics. Users can also view older schema versions and compare them against current versions in a git-like UI, which makes finding differences in evolving schemas and building applications on streaming data simple.
Once developers can view message data and understand how data is structured, they have the basic building blocks to start building applications. Last year, we announced KSQL, the streaming SQL engine for Apache Kafka, to help developers build powerful applications with streaming data. While Confluent Platform 4.1 presented an experimental web interface for developers to run KSQL, in the latest release, Control Center includes KSQL as part of a new development area. With this new GUI for KSQL, stream processing has never been more accessible. Developers can create streams and tables from topics, experiment with transient queries, and run persistent queries to filter and enrich data. What’s more, they can do all this with the power of autocompletion, which lowers the bar to getting started with stream processing. No more trying to figure out what streams and tables exist, or what syntax is right for a command—autocomplete guides developers along the way. KSQL in Control Center lowers the bar for both developers building streaming applications as well as operators who wish to debug cluster issues by filtering and consuming data from topics.
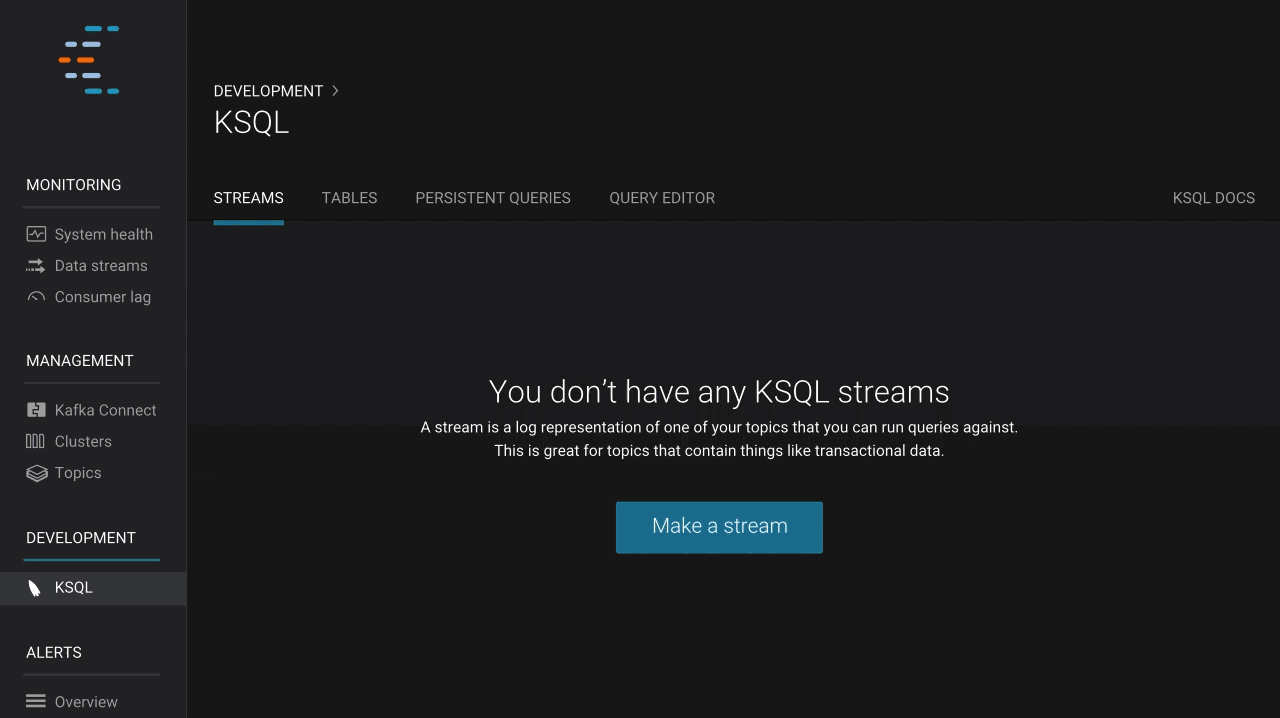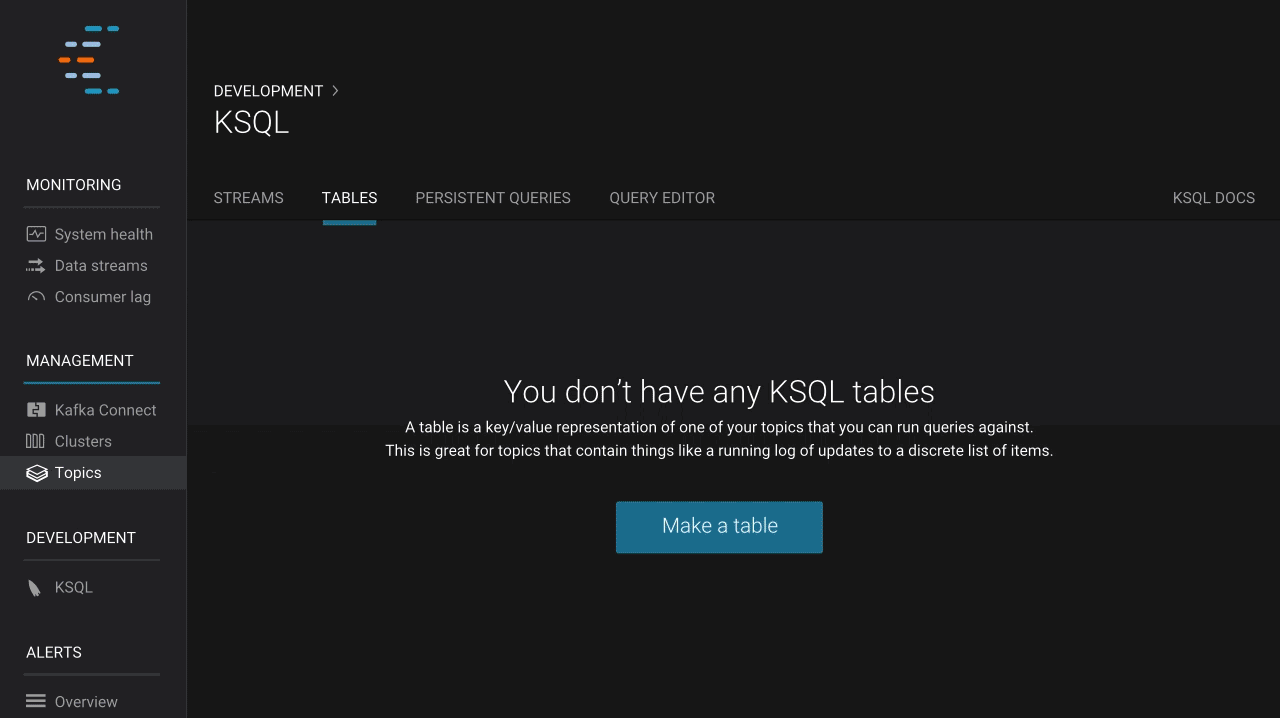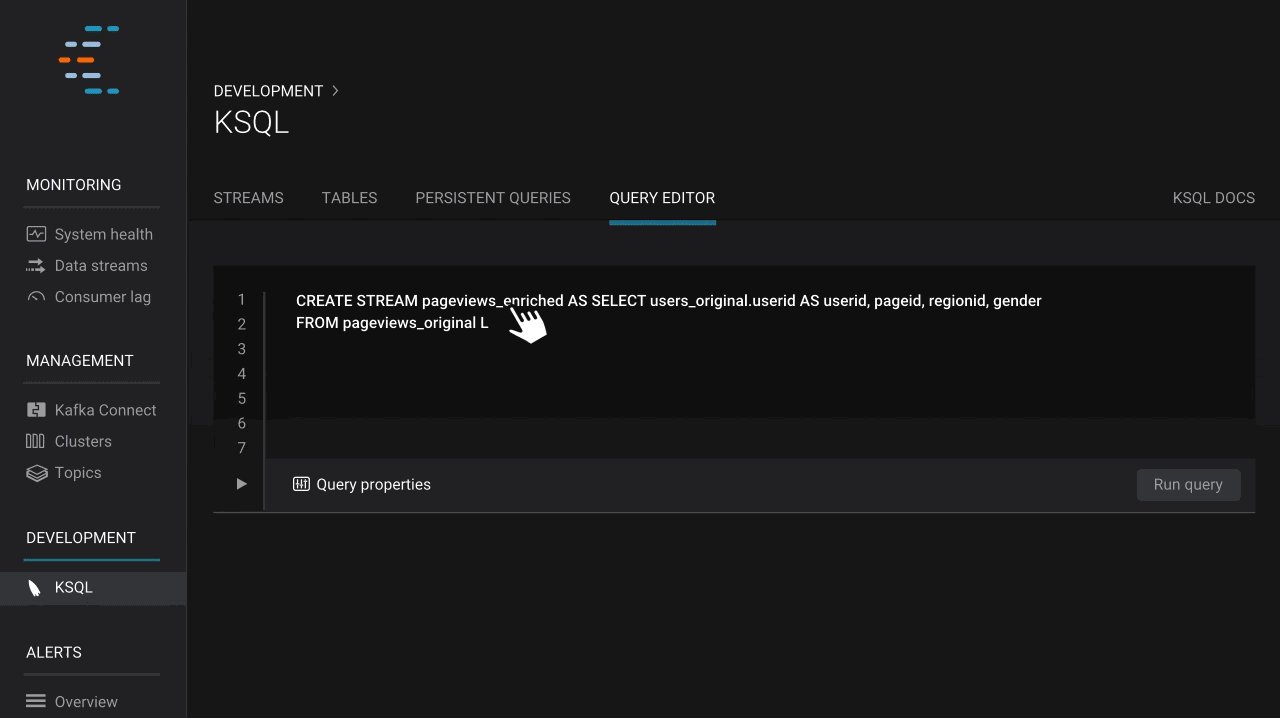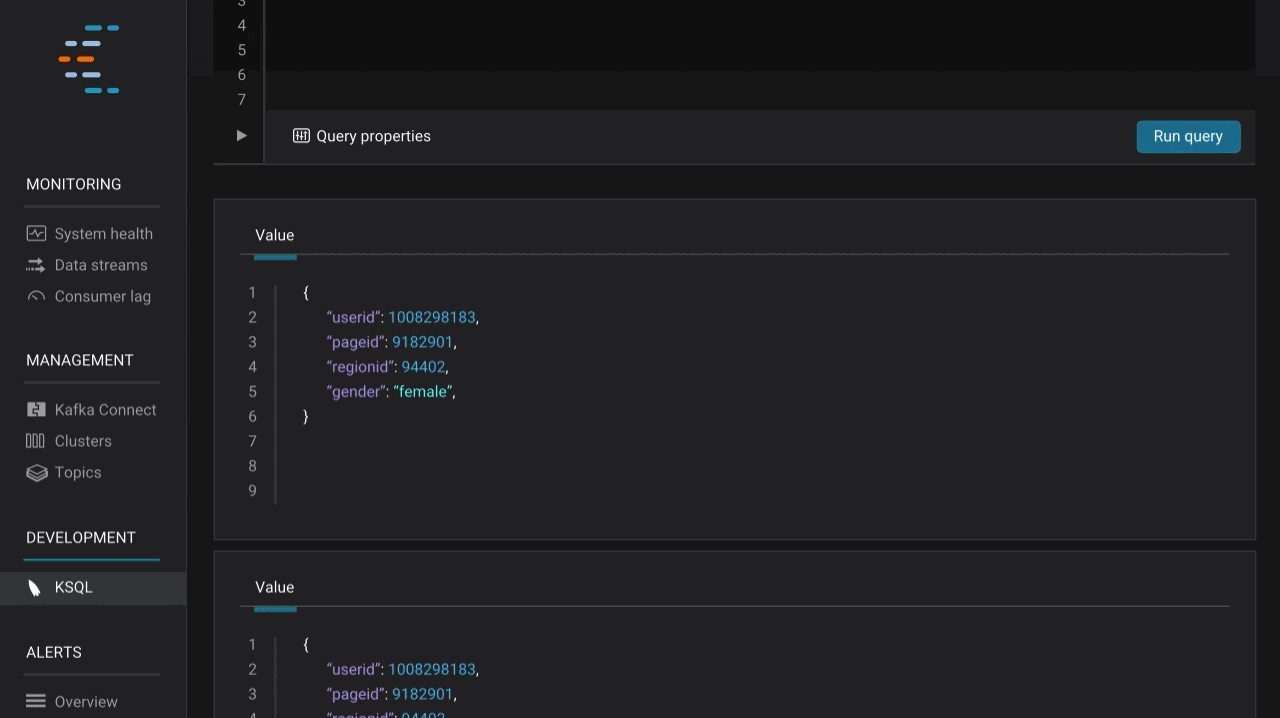
Build more powerful applications with KSQL
Along with providing better GUI support for building applications in Control Center, the latest release includes several highly requested KSQL functionalities.
The most commonly requested feature for KSQL has been support for nested data. Today, KSQL includes a STRUCT type that allows developers to work with nested data in both Avro and JSON formats. This means that you can use KSQL to process data from a broader variety of sources, and tasks such as data extraction and data conversion are even easier.
Another highly requested feature has been the ability to define your own computations that go beyond what KSQL provides out-of-the-box. The newly added User-Defined Functions (UDF) and User-Defined Aggregate Functions (UDAFs) open the door for many novel use cases, for which you need to perform custom computations over your data when KSQL’s built-in scalar functions or built-in aggregation functions are insufficient. Applying a machine learning model in real time to a stream of data is an example of an exciting new use case this allows. UDFs take one input row to produce one output row (e.g., ABS, SUBSTRING), whereas UDAFs take numerous input rows to produce one output row (e.g., SUM, MAX, COUNT).
KSQL also now supports stream-stream, table-table, and stream-table joins. Further, you can execute inner and outer joins in addition to left joins where appropriate for the joined entities. This means that KSQL now covers all of the available join operations in Kafka Streams, and this expanded scope lets you cover more use cases with KSQL. For example, in retail you can detect late shipments by joining a stream of orders with a stream of shipments; in advertising, you can match ad impressions with ad clicks.
Using KSQL’s new INSERT INTO syntax, events from different source streams and queries can be written to the same output stream. This can be useful in various cases, including situations where you have the same logical data arriving on multiple physical topics.
While users enjoy the ability to define stream processing logic simply through SQL-like queries, developers often want to interact with KSQL programmatically in order to compose and run such queries. Through the KSQL REST API, you can leverage your favorite programming language, whether it’s Python, Go, .NET, Java, JavaScript, and even shell scripting, to work with KSQL. This lets you compose KSQL queries at runtime and submit them to the server when you cannot know the query ahead of time, making KSQL and Confluent Platform an even better fit for non-Java virtual machine and/or polyglot environments.
Streamline IoT integration with Kafka
More and more customers of all industries are integrating their IoT devices and gateways with Apache Kafka using the MQTT standard for applications, as in the cases of connected cars, assembly lines in manufacturing, and predictive maintenance. Until today, project teams had to insert an MQTT broker into the middle as an intermediary before building a custom ingestion pipeline into Kafka.
Confluent Platform 5.0 debuts MQTT Proxy to reduce these complexities and streamline IoT integration. It permits users to build a scalable proxy architecture similar to Confluent REST Proxy for HTTP(S) communication with Kafka. MQTT Proxy enables the replacement of third party MQTT brokers with Kafka-native MQTT proxies in order to remove the additional cost and complexity of intermediate storage and lag. The introduction of MQTT Proxy means that fewer services are required and the need to write a custom communication mechanism between MQTT and Kafka is eliminated.
Using Transport Layer Security encryption and basic authentication, MQTT Proxy supports the widely used MQTT 3.1.1 protocol and allows publishing messages in all three MQTT quality of service levels. Future releases will add bidirectional communication and more security options.
New in Apache Kafka 2.0
Like previous releases, Confluent Platform 5.0 is built on the most recent version of Apache Kafka in order to provide customers with the latest in streaming technology. Confluent Platform 5.0 includes Apache Kafka 2.0, which contains a number of new features, performance improvements, bug fixes, and support changes, including:
- 40 KIPs and 246 resolved JIRAs
- Prefixed wildcard access control lists (ACLs), fine-grained ACLs for CreateTopics
- Simple Authentication and Security Layer/OAuthBearer implementation
- Improved quota communication and customization of quotas
- Efficient memory usage for down conversion
- Fix log divergence between leader and follower during fast leader failover
- Improved timeout behaviour in the Java consumer, eliminating indefinite blocking when brokers are not available
- Kafka Connect REST extension plugin, support for externalizing secrets, and improved error handling with dead-letter queue functionality
- Scala API for Kafka Streams and other Streams API improvements
Apache Kafka 2.0 also drops support for Java 7 and removes the previously deprecated Scala producer and consumer. More details are available in the Apache Kafka 2.0 Release Notes.
Get started
Here are the best ways to get started with Confluent Platform:
- Try our free 30-day trial of Confluent Platform, which includes all of these additional capabilities.
- Further details can be found in the documentation.
- Receive expert training and technical consulting to get up and running quickly. Confluent Platform 5.0 is backed by our subscription support.
As always, we are happy to hear your feedback. Please post your questions and suggestions to the public Confluent Platform mailing list, join our community Slack channel, or contact us directly!
Special thanks to Apurva, Dan, Derrick, Erica, Ewen, Hojjat, Ismael, Jo, Joseph, Kai, Mikkin, Neha, Nick, Ran, Randall, Robin, Rohan, Rohit, Tim, Vahid, Victoria, and Vivian for their contributions to this post.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.