Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Getting Started with Apache Kafka and Python
Welcome Pythonistas to the streaming data world centered around Apache Kafka®! If you’re using Python and ready to get hands-on with Kafka, then you’re in the right place. This blog post introduces the various components of the Confluent ecosystem, walks you through sample code, and provides suggestions on your next steps to Kafka mastery. However, before we begin stepping through some code, let’s quickly cover the fundamentals.
Brief introduction to key concepts and capabilities
At the very heart of Apache Kafka is the concept of a topic, which is an append-only sequence of records. Topics are organized into partitions that are hosted by a cluster of brokers. For high availability, partitions are replicated throughout the cluster. A Kafka record may contain a key and a value, and when it’s being published the key may be used to determine the destination partition. The default partitioner hashes the key (i.e., partition = hash(key) % num_partitions) to determine partition placement. If records don’t have a key, then they are distributed using a sticky partitioning strategy. When records are written to a partition by a producer they are stored at a unique position called an offset. With a key and the default partitioner, Kafka guarantees ordered delivery of records within a single partition. Since Kafka only stores bytes, keys and values must be serialized before being written and deserialized when being read. The serialization and deserialization of records is handled by a variety of available serializers and deserializers, which are reviewed in the next section.
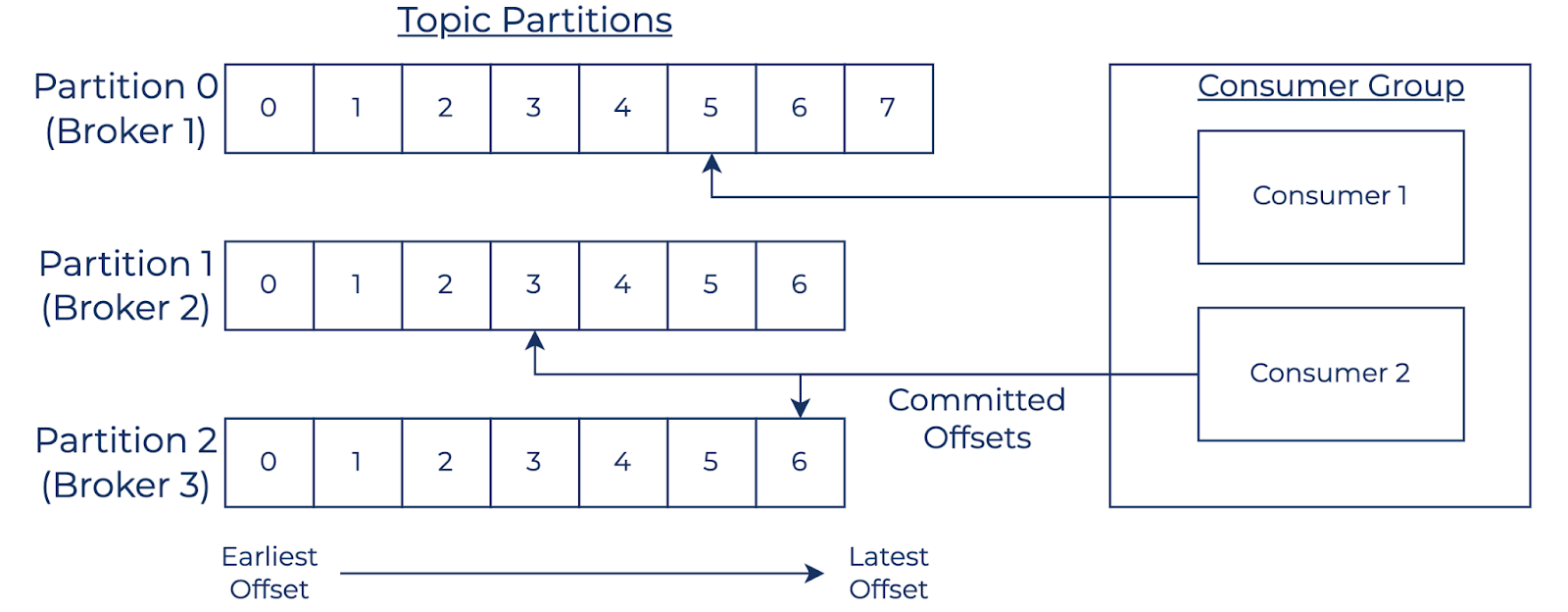
A consumer can subscribe to one or many topics, and when configured with a common group.id, can participate in a consumer group. Consumers in a consumer group not only collaborate to consume records in parallel, but also automatically begin to consume records from reassigned partitions when a member of the group becomes inactive. This process is named the consumer group rebalance protocol and is used by other components in the ecosystem. A key distinction between record consumption in Kafka and traditional message queues is that records persist on the broker until the configured retention policy takes effect. By default, a topic’s retention period is seven days and retention policies are also available to maintain records by partition size and by record key (called compaction). Consumers continuously poll brokers to retrieve additional records and advance their committed offsets. A consumer’s committed offset represents its position within the partition (i.e., the next record to read). When a consumer starts polling for the very first time, it has no committed offset. Therefore its auto.offset.reset parameter is used to determine the initial starting point. Besides auto.offset.reset, a consumer’s committed offset can be reset to any available offset, which allows for various replay use cases.
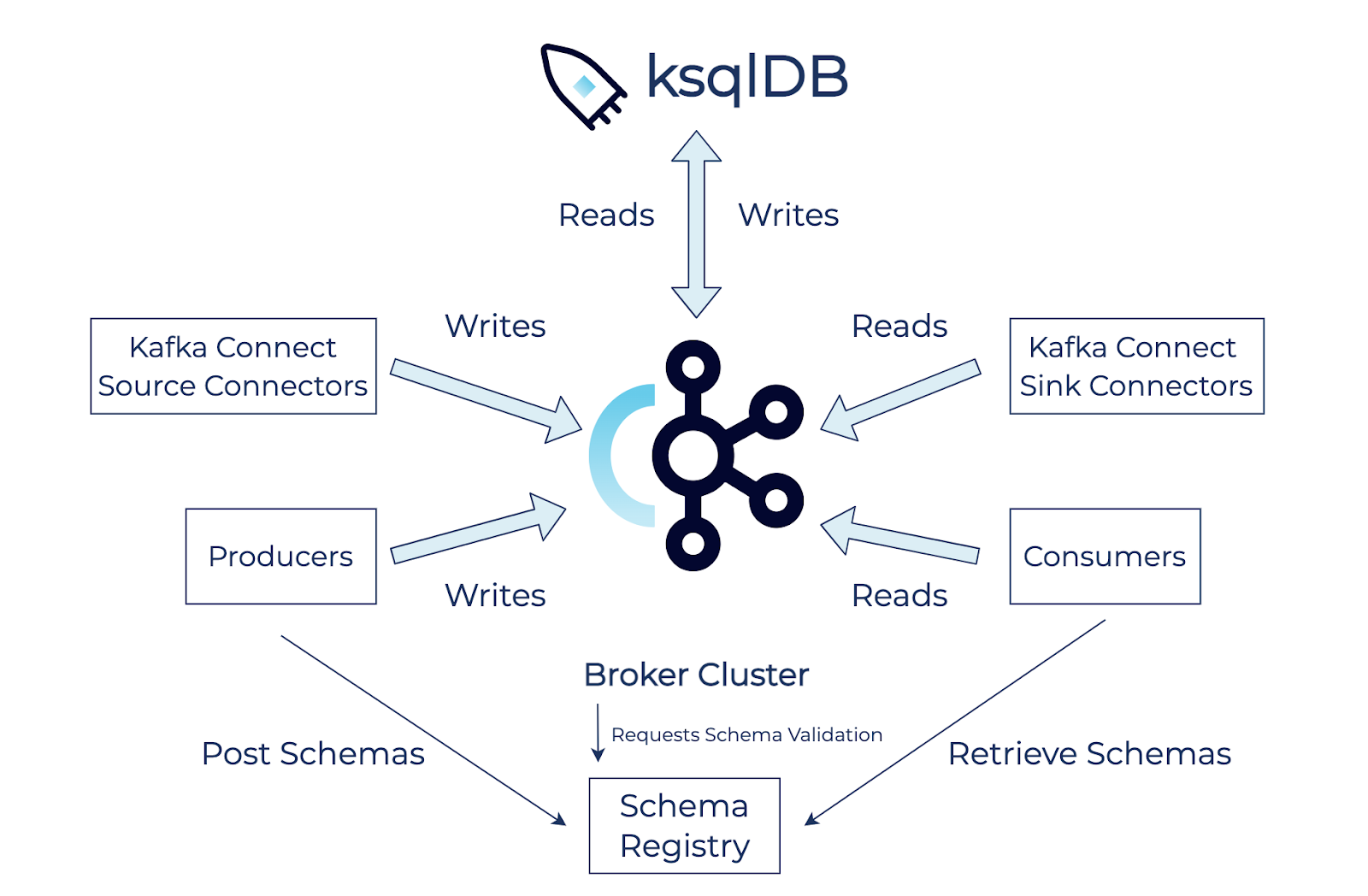
Now that we’ve covered the essential concepts involved in producing and consuming records in Kafka, let’s look into a few of the great components that Confluent has added to enable integrations, compatibility, and stream processing.
Kafka Connect is a robust and scalable integration framework for developing source and sink connectors. Source connectors produce records from external systems, and sink connectors consume from topics in order to store records in external systems. As of June 7, 2021, Confluent Hub provides 200+ connectors for a large variety of systems, and new connectors are still being added. Confluent Schema Registry ensures that producers and consumers are compatible across schema revisions. By storing each schema version and performing schema validation, Schema Registry can enforce multiple compatibility modes including backward, forward, and full. Backward compatibility is the default mode and ensures that consumers with the new schema can consume messages produced with the last schema. Forward compatibility ensures that consumers with a prior schema can consume messages produced with the new schema. Full compatibility ensures both backward and forward compatibility.
The next section goes into further detail around schema validation by walking through a demo of a backwards compatibility issue involving JSON schemas. However, before we move on, there’s one more Confluent component that must be introduced.
ksqlDB is a streaming database that provides a simple SQL interface for performing complex operations, such as aggregations, joins, and windowing. It relies on a Java library called Kafka Streams which in turn uses the lower-level consumer and producer APIs. ksqlDB allows for both stateless and stateful use cases by including support for both streams and tables. Streams are unbound collections of events that rely on one or more source topics. Tables, like streams, can also rely on one or multiple source topics but only retain the latest value for each key. ksqlDB also supports two types of queries, namely push queries and pull queries. Push queries continuously write results to an output topic and pull queries, like common database queries, can serve data from an internal data store called RocksDB.
In an upcoming section, we’ll take a closer look into push queries by walking through the different types of joins that ksqlDB supports.
Producing and consuming JSON and Protobuf
To set up our development machines we just need to run docker-compose up -d as Confluent provides Docker images and many sample docker-compose files to help us get started. The simplified docker-compose file I created was based on a more comprehensive version (docker-compose-all-in-one.yml) that contains a few more components, such as Confluent Control Center. Confluent Control Center is out of scope for this post, but I encourage you to check it out as it provides a great experience for administration and monitoring.
With all of the containers up and running, I wanted to bring your attention to all of the command line tools that are available. We’ll only be using kafka-topics to create the required topics, but you’ll likely find many of these additional tools useful as you explore on your own. To set up our Python virtual environments, I’ve prepared a Pipfile that references the confluent-kafka package. The confluent-kafka package depends on librdkafka, which is a high-performance Kafka client implemented in C++. After running pipenv install to install all of the packages, we just need to run the following kafka-topics command to run our first example.
docker exec -it broker kafka-topics —create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic user_json --config confluent.value.schema.validation=true
The bootstrap-server option specifies the address of at least one broker in the cluster. Since each broker is aware of all the others in the cluster, a subset of the available brokers will suffice to establish a connection. The replication-factor option controls the number of brokers that will maintain copies of the topic’s partitions. The partitions option specifies the number of partitions. I recommended that you set it to a larger number as it’s a key factor in controlling the amount of parallel consumption. However, as each partition incurs overhead, I also recommend choosing the number of partitions carefully. Lastly, the config option can be used to configure additional settings. In this example we’re enabling the schema validation feature, which we’ll see in action shortly.
Producing and consuming JSON
Now that we’ve covered the essential fundamentals, let’s dive into some sample code that produces structured records to our running Kafka cluster.
def produce_json():
schema_registry_conf = {'url': 'http://localhost:8081'}
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
json_serializer = JSONSerializer(schema, schema_registry_client, user_to_dict)
# https://docs.confluent.io/platform/current/installation/configuration/producer-configs.html
p = SerializingProducer({
'bootstrap.servers': 'localhost:9092',
'key.serializer': StringSerializer('utf_8'),
'value.serializer': json_serializer
})
user = User(name='Robert Zych',
favorite_color='blue',
favorite_number=42,
twitter_handle='zychr')
p.produce('user_json', key=str(uuid4()), value=user, on_delivery=delivery_report)
p.flush()
print('produced json encoded user')
In the sample above, the confluent-kafka package provides the SchemaRegistryClient, JSONSerializer, and SerializingProducer classes which allow us to produce JSON+schema messages to the broker. Before the message is actually sent to the broker, the key and value must be serialized as the Kafka broker only recognizes bytes. In this example, the JSONSerializer serializes the message and the StringSerializer serializes the key. Also, the schema is automatically registered with the Schema Registry. p.flush() forces the message to be sent as p.produce(…) only buffers the messages locally to maximize throughput. In general, p.flush() should be only called when the producer is no longer needed as the usage above is designed for demonstration purposes. Also, instantiating a SerializingProducer or any other type of client instance is an expensive operation and therefore instances should be reused. Lastly, using a schema and the Schema Registry aren’t technically required to publish and consume messages, however, using message schemas can help to maintain compatibility between producers and consumers.
def consume_json(): json_deserializer = JSONDeserializer(schema, from_dict=dict_to_user) string_deserializer = StringDeserializer('utf_8') # https://docs.confluent.io/platform/current/installation/configuration/consumer-configs.html consumer = DeserializingConsumer({ 'bootstrap.servers': 'localhost:9092', 'key.deserializer': string_deserializer, 'value.deserializer': json_deserializer, 'group.id': 'json-consumer-group-1', 'auto.offset.reset': 'earliest' }) consumer.subscribe(['user_json']) try: while True: msg = consumer.poll(1.0) if msg is None: continue user = msg.value() if user is not None: print(f'User name: {user.name}, ' f'favorite number:{user.favorite_number}, ' f'favorite color:{user.favorite_color}, ' f'twitter handle:{user.twitter_handle}') except KeyboardInterrupt: break print('closing the consumer') consumer.close()
In this example, the DeserializingConsumer is configured with key and value deserializers, auto.offset.reset, and a group.id. With the auto.offset.reset set to earliest the consumer will begin reading from the oldest available offset if no committed offset exists. The group.id is simply a unique identifier shared by all of the consumers in the same group and can be used to scale out consumption. consumer.subscribe(…) allows the consumer to subscribe to a list of topics, and in the body of the while loop, consumer.poll(…) is used to retrieve messages from the topic. To see schema validation in action, let’s revisit the producer and add another field to schema’s required list. Now if we run producing_json.py again, we should see:
confluent_kafka.error.ValueSerializationError: KafkaError{code=_VALUE_SERIALIZATION,val=-161,str=“Schema being registered is incompatible with an earlier schema for subject “user_json-value” (HTTP status code 409, SR code 409)”}
As the new required field would prevent holders of the new schema from reading messages produced with the older schema, backward compatibility would have been violated, and therefore the message and schema were rejected. Schema Registry is configured with backward compatibility by default, but can also be configured to enforce forward compatibility, and full compatibility (i.e., both backward and forward).
Producing and consuming Protobuf
def produce_protobuf(): schema_registry_conf = {'url': 'http://localhost:8081'} schema_registry_client = SchemaRegistryClient(schema_registry_conf) protobuf_serializer = ProtobufSerializer(User, schema_registry_client) # https://docs.confluent.io/platform/current/installation/configuration/producer-configs.html p = SerializingProducer({ 'bootstrap.servers': 'localhost:9092', 'key.serializer': StringSerializer('utf_8'), 'value.serializer': protobuf_serializer }) user = User(name='Robert Zych', favorite_color='blue', favorite_number=42, twitter_handle='zychr') p.produce('mytopic_protobuf', key=str(uuid4()), value=user) p.flush() print('produced protobuf encoded user')
This example uses a ProtobufSerializer which is configured with the User class that was generated by the Protobuf compiler. The generated User class can also be used to deserialize messages by the ProtobufDeserializer.
Stream processing with ksqlDB
A stream is simply an abstraction for an infinite collection of records. In the stream processing paradigm, records are processed continuously via long-running processes. ksqlDB allows us to easily create these types of long-running processes using SQL queries that create live streams and tables. In this section we’ll look into the various types of SQL joins that combine data from streams and tables.
Table-table join
Tables in ksqlDB retain the latest value for a key and are stored on disk. Since ksqlDB is a distributed system, state changes are replicated via internal topics to achieve fault tolerance. These internal topics can be processed by standby instances in the ksqlDB cluster.
By using the CREATE TABLE AS SELECT syntax we’ve generated a new table that is updated whenever a new record with a matching key is inserted into either table.
Stream-table join
Stream-table joins can be used to produce a new stream that is based on an existing stream and is enriched with reference data from a table.
By using the CREATE STREAM AS SELECT syntax we’ve generated a new stream that produces a result whenever a new event arrives in left_stream. The event in left_stream is matched to the latest value from right_table by key.
Stream-stream join
Stream-stream joins are similar to joins above, but since streams are unbounded, a time window constraint must be specified.
In this example event seven wasn’t matched with the latest event in right_stream as the latest event in right_stream was no longer in the 1-minute window. Since event eight was added within 1-minute of event seven, the events were combined into the output stream.
Summary
To recap, Kafka brokers host and replicate topic partitions. Partitions are append-only and contain records that have their own unique offsets. Producers serialize and publish records to topic partitions and the partition placement of records depend on their keys. Consumers, when configured with a group.id, form consumer groups that collectively process messages from their subscribed topics.
Confluent maintains the Confluent-Kafka Python package that supports producing and consuming messages in multiple formats and methods. ksqlDB provides a familiar SQL interface for developing streaming applications and supports various types of streaming joins between streams and tables. As we’ve only scratched the surface of ksqlDB feature set, there are many more features to explore, such as aggregation functions and windowing strategies. Thank you for following this post, I hope you’ve enjoyed it! To continue your journey, check out the Getting Started with Apache Kafka and Python step-by-step guide on Confluent Developer.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...