Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Designing Events and Event Streams: Introduction and Best Practices
Designing Events and Event Streams: Introduction and Best Practices
Properly designing your events and event streams is essential for any event-driven architecture. Precisely how you design and implement them will significantly affect not only what you can do today, but what you can do tomorrow. For such a critical part of any data infrastructure, most event streaming tutorials gloss over event design.
In the new course on Confluent Developer, events and event streams are put front and center. We’re going to look at the dimensions of event and event stream design and how to apply them to real-world problems. But dimensions and theory are nothing without best practices, so we are also going to take a look at these to help keep you clear of pitfalls and set you up for success. This course also includes hands-on exercises, during which you will work through use cases related to the different dimensions of event design and event streaming.
Introduction to designing events and event streams
What is an event? How do people come to start using events? How should you think about events?
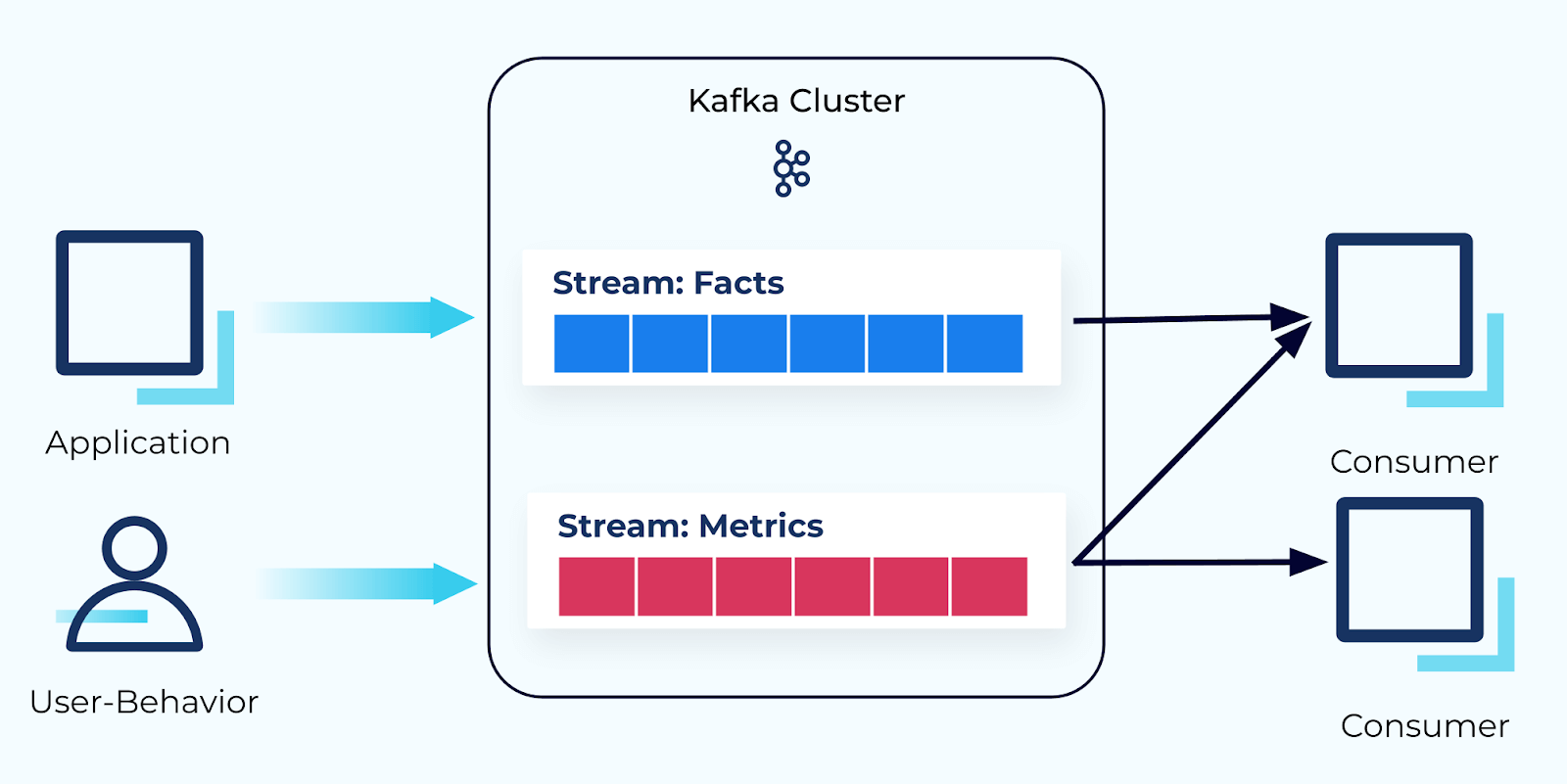
The course’s introductory module examines each of these questions in detail. It clearly defines what events are, how they get created, how they are used, the types of information they contain, and the service boundaries determine how these events are shared across the organization. It concludes by introducing the four dimensions of event design, each of which is covered in detail in the modules that follow.
Dimension 1: Fact vs. delta event types
Learn the properties of fact, delta, and composite event types and the scenarios they are best suited for in the dimension 1 module. It provides you with examples of each, as well as usage recommendations and some tips for avoiding pitfalls.
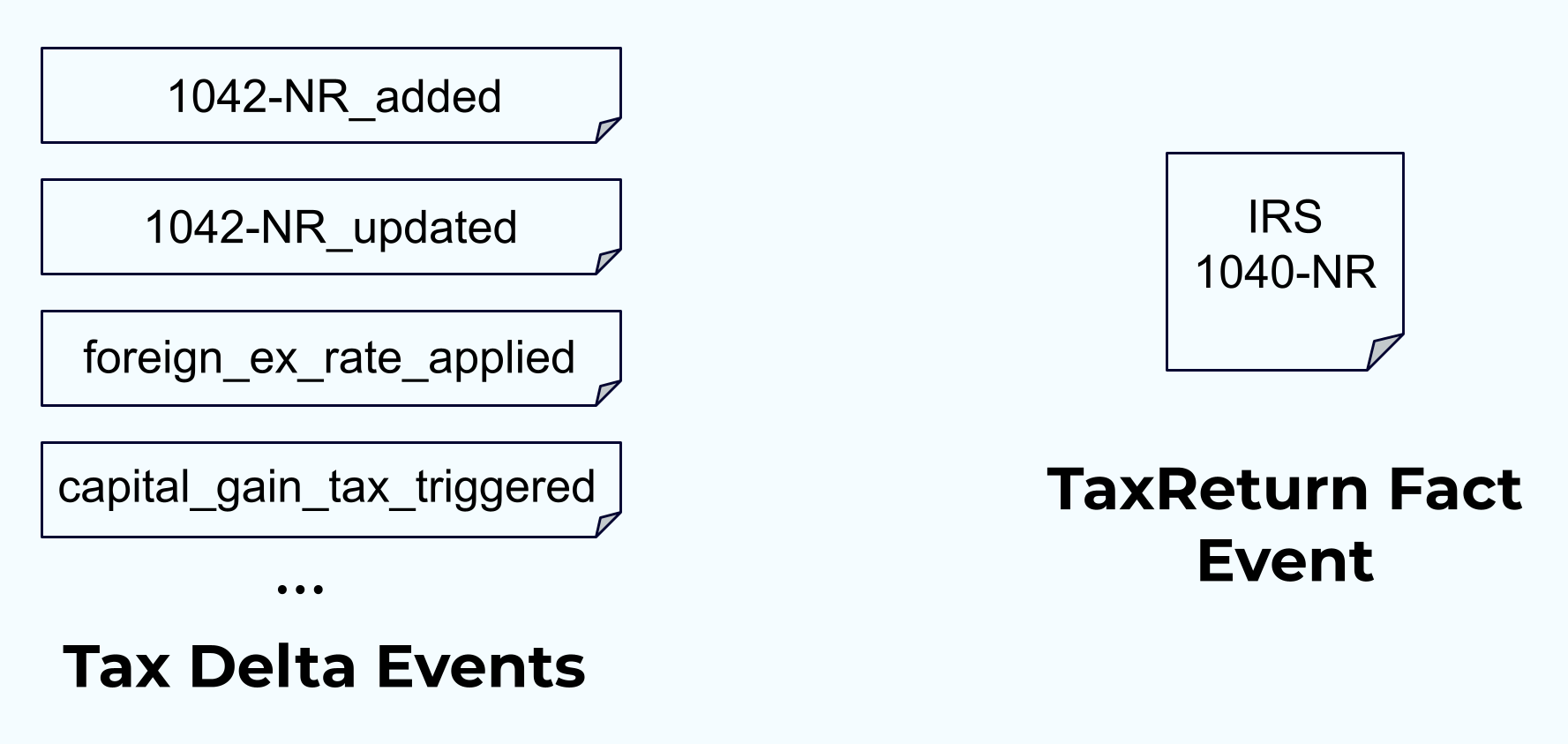
The module is followed by a hands-on exercise in which you will explore use cases for both fact and delta events. In the first part of the exercise, you will materialize a stream of item fact events into a table. Each new item fact will be inserted into the table as it is consumed, overwriting any previous facts that share the same primary key. Facts provide an excellent way to transfer state from one service to another. In the second part of the exercise, you will produce a delta event representing adding an item to a shopping cart, use ksqlDB to aggregate the event stream, and observe the resultant sums of items per shopping cart in a KTABLE.
Dimension 2: Normalization vs. denormalization
Relational databases often use some degree of normalization in the creation of their data models, whereas document databases often lean toward a more denormalized format. In the dimension 2 module, you will learn about the trade-offs between normalization and denormalization of the event data model.
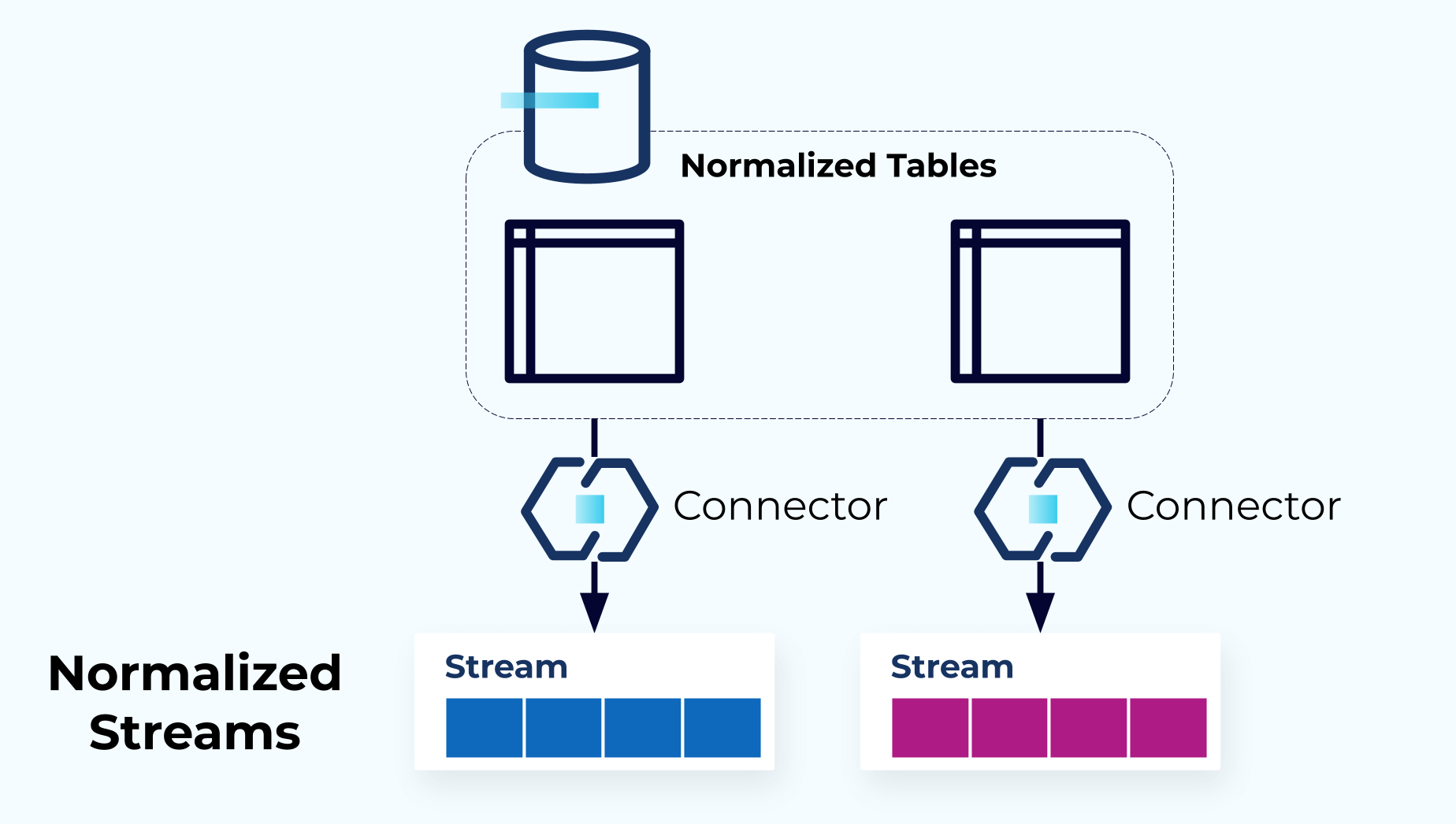
The module is followed by a hands-on exercise in which you will use ksqlDB to denormalize several event streams that mirror the upstream relational model of an event source by resolving the foreign-key joins. You will start by creating the three ksqlDB tables and populating them with events. You will then denormalize the tables, creating a new table that contains the resulting enriched events. You will then insert data into the original three tables and verify the inserted data makes its way to the enriched events table.
Dimension 3: Single vs. multiple event streams
The third dimension to consider when designing events and event streams is the relationship between your event definitions and the event streams themselves. One of the most common questions we receive is, “Is it okay to put multiple event types in one stream? Or should we publish each event type to its own stream?” This module explores the factors that contribute to answering these questions and offers a set of recommendations that should help you find the best answer for your own use cases.
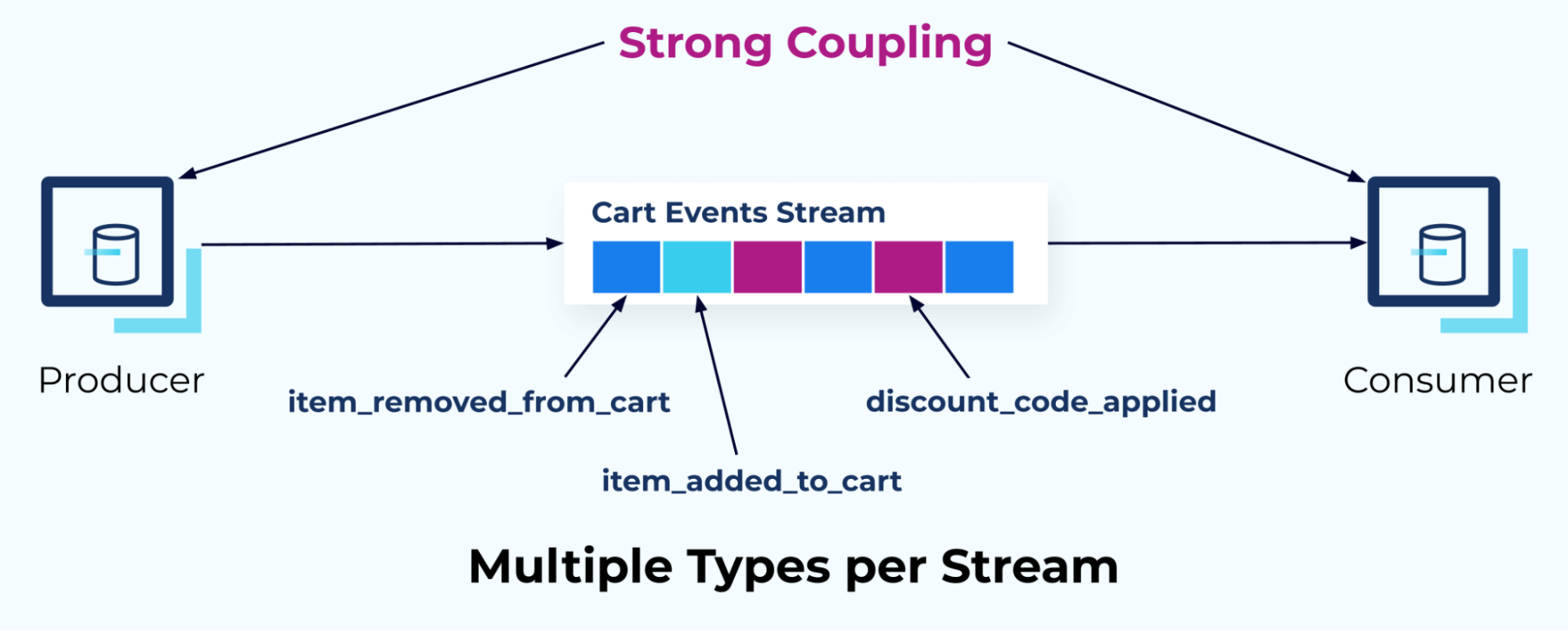
The module is followed by a hands-on exercise in which you will build up the current shopping cart for a series of add and remove item events. Since ksqlDB doesn’t support multiple independent schema definitions as inputs to a single operation, you will merge them together into one stream. You will then use ksqlDB to aggregate the events together into the current state of the shopping cart. During the exercise, you will see items added and removed from the cart in real time, as well as witness how the aggregate functions work.
Dimension 4: Terminating vs. non-terminating entities
The final major dimension of event design pertains to the relationships between events, and how they’re used and interpreted by the consumer.
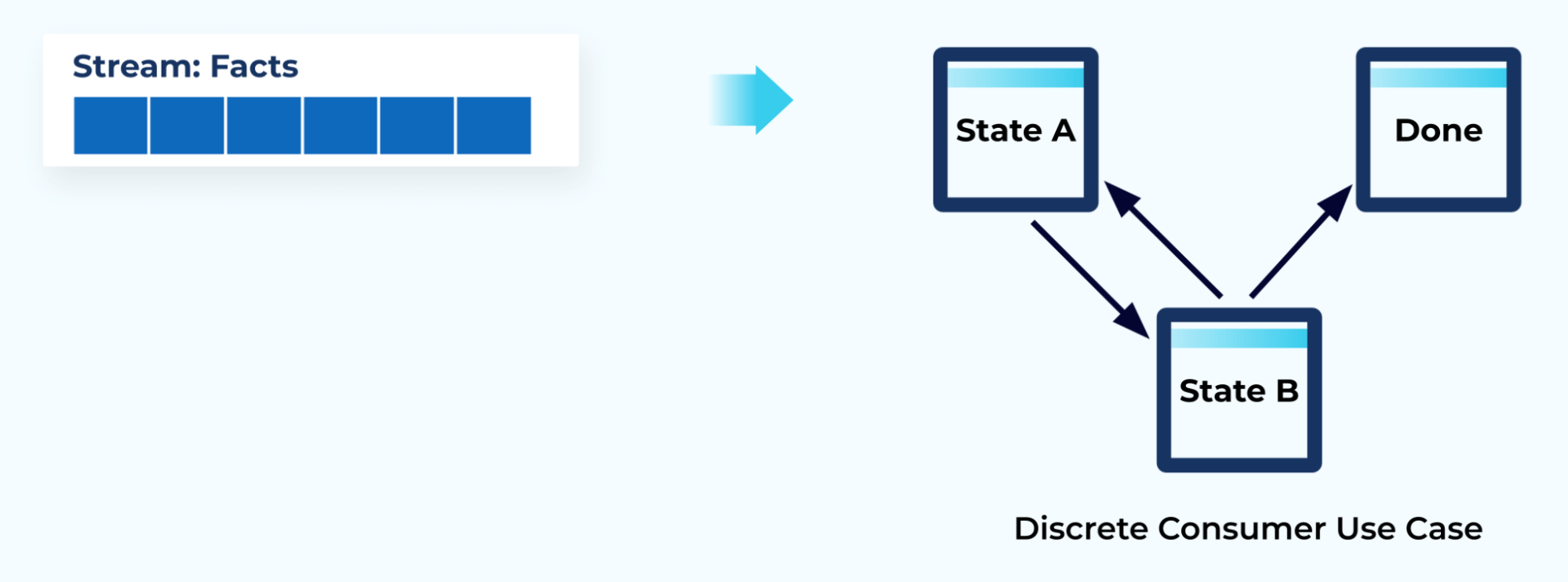
A discrete event flow drives state changes within the consumer application’s state machine and results in either the completion or the abandonment of the consumer’s workflow.

In contrast, a continuous event flow is most commonly represented as a series of independent events, such as measurements taken at a point in time. This module examines both of these types of event flows.
Best practices for event design and event streams
This module covers best practices related to events and event streams.
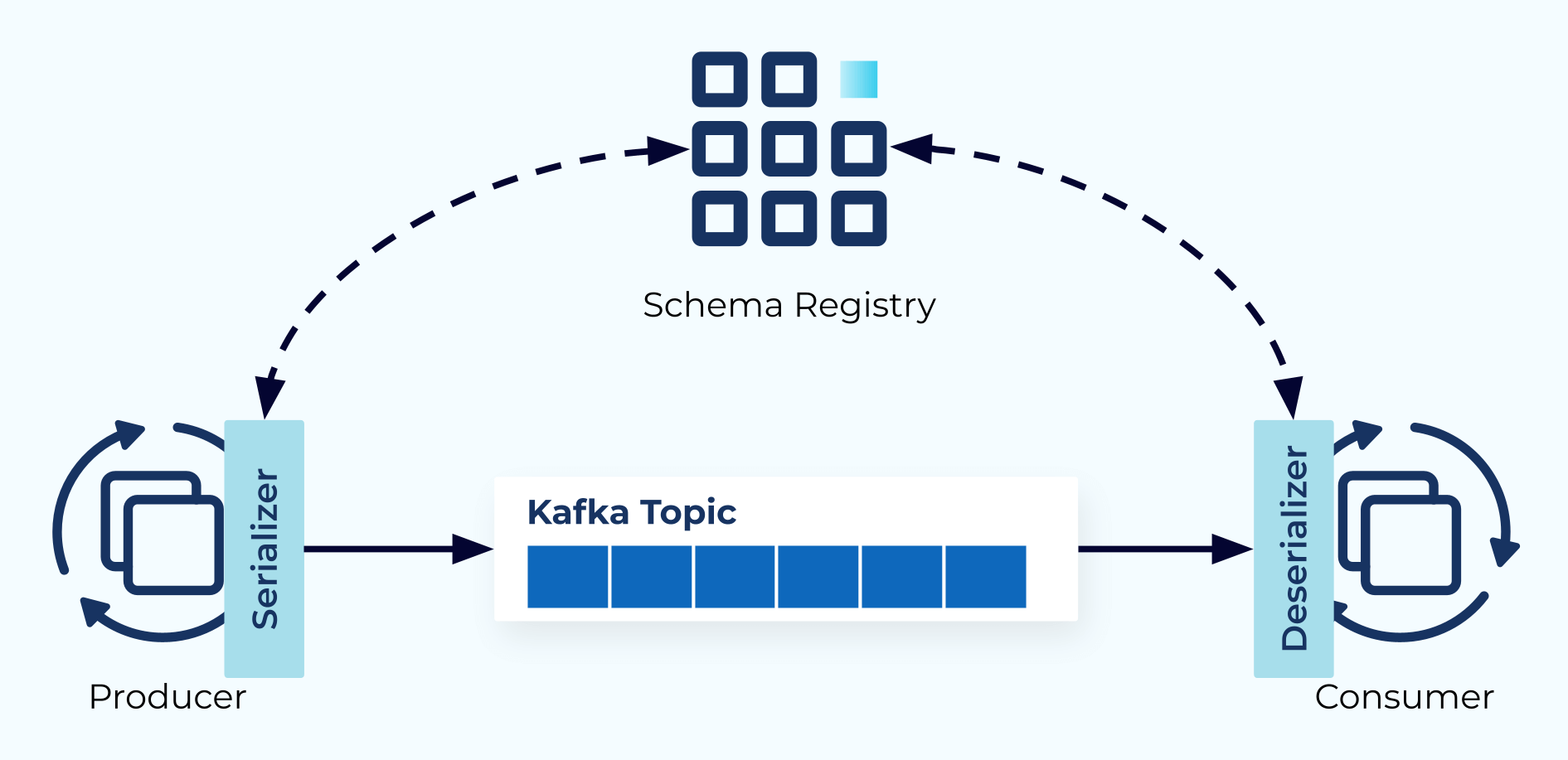
First, it explores event schemas followed by event metadata and headers, and the role that each plays in an event-driven architecture.

Next, it examines options for naming events and event streams and provides examples of where each works best.

Finally, this module explores unique event IDs, as well as some strategies you can use to ensure each event is uniquely identifiable.
If you’re ready to learn more about designing events and event streams, jump into the free course on Confluent Developer!
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...