Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Debugging of a Stream-Table Join: Failing to Cross the Streams
Joining two topics to aggregate the data is one of the fundamental operations in stream processing. But that's not to say that it's simple. Let me show you what can go wrong! This article chronicles my journey to join two Apache Kafka topics—stumbling into and out of various pitfalls. I‘m going to show you...
- How to debug co-partitioning with kcat (formerly kafkacat)
- How to avoid the number one pitfall of using kcat
- Stream–table join semantics in action
Would you prefer a talk instead? For a video version of this article, see the talk Failing to Cross the Streams – Lessons Learned the Hard Way from the Kafka Summit Europe 2021. Try it at home! If you want to try the example yourself, you will find everything on GitHub.
Use case: a GDPR story
At TNG Technology Consulting, we focus on high-end information technology. We support our customers with state-of-the-art tools like Apache Kafka.
This article is based on my experience with a client in e-commerce.
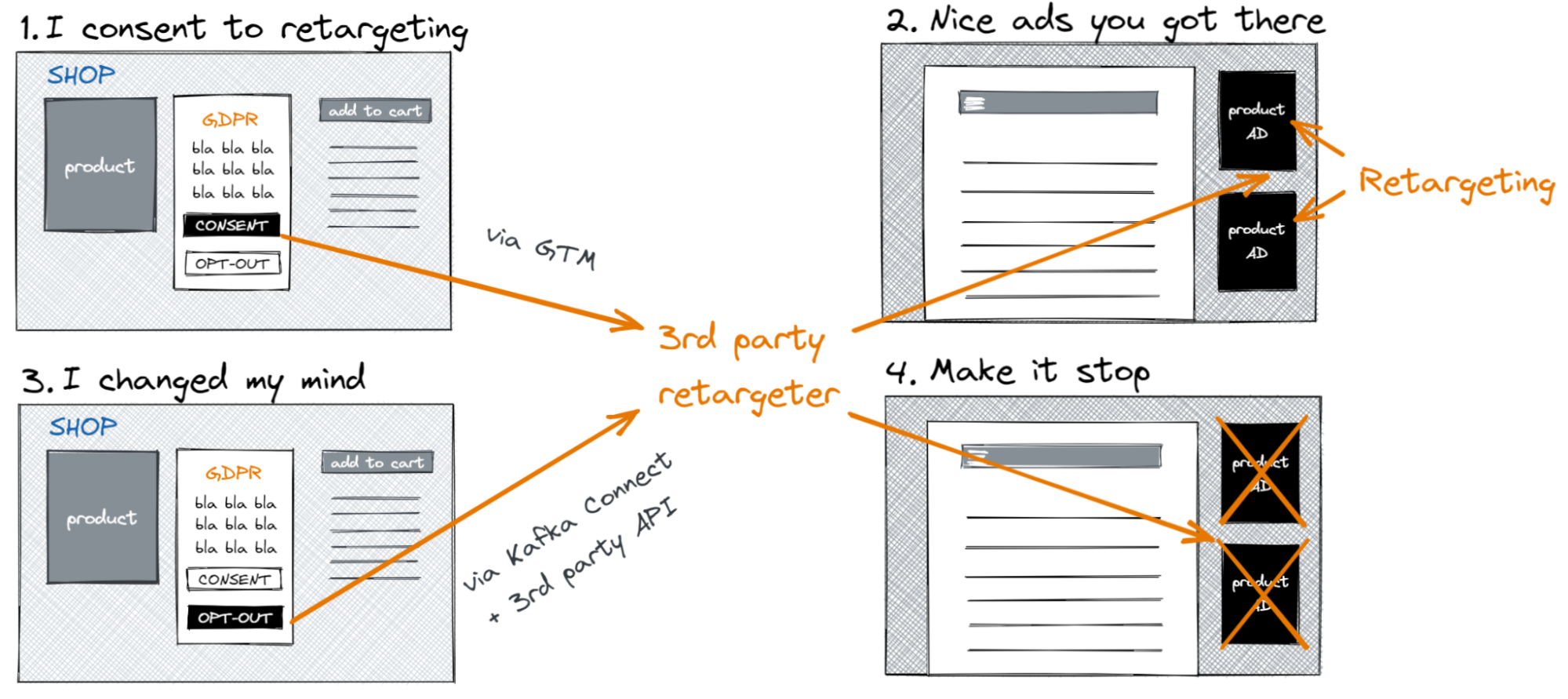
If you have used the internet in recent years, you are probably familiar with consent pop-ups.
When users arrive at the website of our e-commerce client, they will get a pop-up. Users are asked whether they consent to tracking for personalization or optimization purposes. If the user consents to tracking for personalization purposes, we load a tracking pixel of a third-party "retargeter".
When the user browses the shop, the tracking pixel informs the retargeter, which products the user looks at. Once the user leaves the shop, they may then see ads for these products on other websites. This retargeting entices the user to go back to the shop and hopefully purchase the products they like.
Where this gets interesting is if the user later decides to opt out of tracking. Naturally, we would no longer load the tracking pixel after the opt-out. However, the third-party retargeter would still have the data from previous visits and could still show ads to the user. We want to explicitly send the opt-out to the retargeter, so that they remove all user data and stop advertising to the user.
To perform the explicit opt-out reliably, we use Kafka Connect to call the opt-out API of the retargeter. Kafka Connect is reliable by default—messages are processed with retries until they succeed; they are never skipped. We store the detailed consent information for each customer in Kafka. A custom Kafka Connect connector uses that data to call the third-party API.
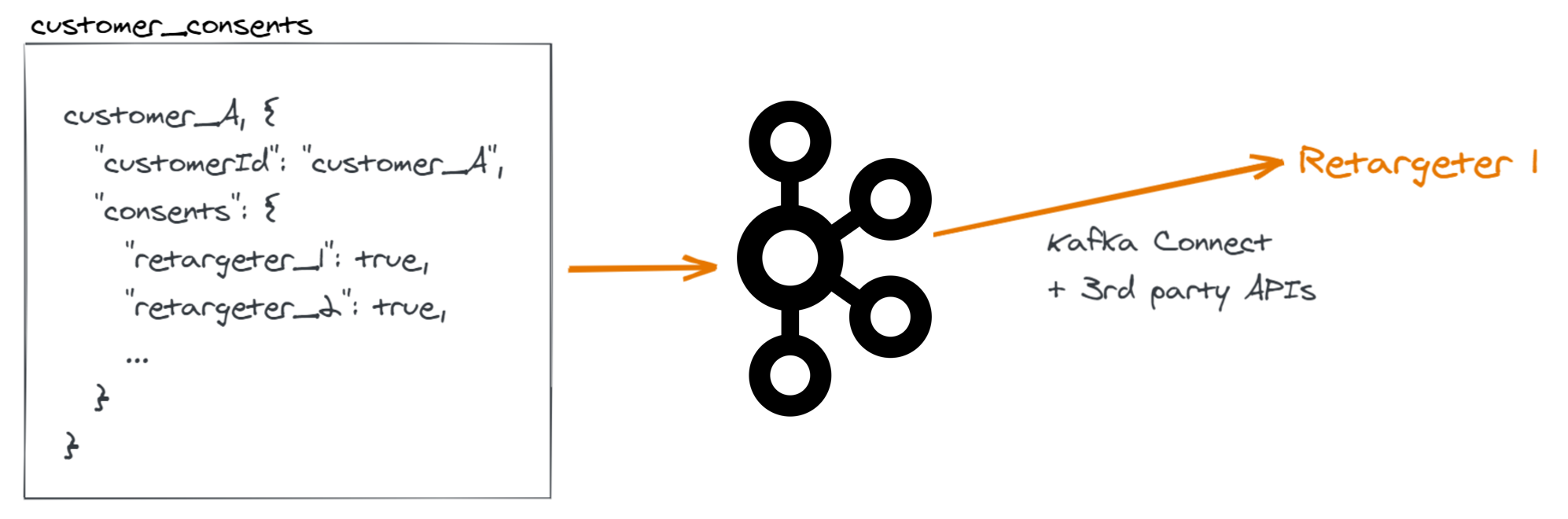
The challenge
One retargeter requires additional data for their opt-out API that is not part of the consent topic in Kafka: the email address of the user. We want to enrich the consent topic with data from our "accounts" topic, which contains the email address.
We want to join the two topics using ksqlDB to derive a new topic that contains the email address in addition to the consent data.

The data
We can use ksqlDB to get a first overview of the two topics in Kafka. Using the SHOW TOPICS command, we can see that two topics "customer_consents" and "customer_accounts" exist. The customer_consents are in Avro format; the customer_accounts are in JSON format. Both use four partitions.
Using the PRINT command, we can see the content of the topics. Both topics use the customer ID as the message key.
SHOW TOPICS;
Kafka Topic | Partitions | Partition Replicas
---------------------------------------------------------------
customer_accounts | 4 | 1
customer_consents | 4 | 1
default_ksql_processing_log | 1 | 1
---------------------------------------------------------------
PRINT 'customer_accounts' FROM BEGINNING;
rowtime: 2021/06/13 15:20:46.399 Z, key: user_1, value: {"customerId": "user_1", "contactMailAddress": "email_1"}
rowtime: 2021/06/13 15:20:46.410 Z, key: user_2, value: {"customerId": "user_2", "contactMailAddress": "email_2"}
rowtime: 2021/06/13 15:20:46.411 Z, key: user_3, value: {"customerId": "user_3", "contactMailAddress": "email_3"}
rowtime: 2021/06/13 15:20:46.411 Z, key: user_4, value: {"customerId": "user_4", "contactMailAddress": "email_4"}
rowtime: 2021/06/13 15:20:46.411 Z, key: user_7, value: {"customerId": "user_7", "contactMailAddress": "email_7"}
PRINT 'customer_consents' FROM BEGINNING;
rowtime: 2021/06/13 15:21:01.459 Z, key: user_8, value: {"customerId": "user_8", "hashedCustomerId": "hashforuser8", "consents": {"retargeter1": false, "retargeter2": false}}
rowtime: 2021/06/13 15:21:01.457 Z, key: user_5, value: {"customerId": "user_5", "hashedCustomerId": "hashforuser5", "consents": {"retargeter1": true, "retargeter2": true}}
rowtime: 2021/06/13 15:21:01.458 Z, key: user_6, value: {"customerId": "user_6", "hashedCustomerId": "hashforuser6", "consents": {"retargeter1": false, "retargeter2": false}}
rowtime: 2021/06/13 15:21:02.504 Z, key: user_10, value: {"customerId": "user_10", "hashedCustomerId": "hashforuser10", "consents": {"retargeter1": false, "retargeter2": false}}
rowtime: 2021/06/13 15:21:01.456 Z, key: user_2, value: {"customerId": "user_2", "hashedCustomerId": "hashforuser2", "consents": {"retargeter1": false, "retargeter2": false}}
The join
The idea of the join is to take the incoming consent data, look up the email address of the user, and add the email address to the result. That is exactly what a Stream–Table join does!
With a Stream–Table join, we look at the customer_consents as a stream, where new consent messages arrive any time a user changes their consent settings. By contrast, we look at the customer_accounts as a table that always contains the most recent email address for each customer. For any new consent message, we want to look up the most recent email address of the customer and add it to the consent.
We should be able to just follow the tutorial on How to join a stream and a lookup table from Confluent Developer!
First, we set auto.offset.reset so that our join uses all data from the two topics—otherwise a newly created stream would not contain any of the messages that already exist in the topic. When experimenting with queries in ksqlDB, it is convenient to always include existing data in the topics.
SET 'auto.offset.reset' = 'earliest';
Now we create the table from the customer_accounts topic. The topic is in JSON format, so we specify all columns of the table explicitly.
CREATE TABLE customer_accounts (key_customerid VARCHAR PRIMARY KEY, contactMailAddress VARCHAR)
WITH (kafka_topic='customer_accounts', value_format='json');
SELECT * FROM customer_accounts EMIT CHANGES LIMIT 5;
+------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------+
|KEY_CUSTOMERID |CONTACTMAILADDRESS |
+------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------+
|user_8 |email_8 |
|user_1 |email_1 |
|user_5 |email_5 |
|user_6 |email_6 |
|user_2 |email_2 |
Limit Reached
Then, we create the stream from the customer_consents topic. The topic is in Avro format, so we only have to specify the key column. ksqlDB infers other table columns from the Avro schema using the Schema Registry.
CREATE STREAM customer_consents (key_customerid VARCHAR KEY)
WITH (kafka_topic='customer_consents', value_format='avro');
SELECT * FROM customer_consents EMIT CHANGES LIMIT 5;
+--------------------------------------------------------+--------------------------------------------------------+--------------------------------------------------------+--------------------------------------------------------+
|KEY_CUSTOMERID |CUSTOMERID |HASHEDCUSTOMERID |CONSENTS |
+--------------------------------------------------------+--------------------------------------------------------+--------------------------------------------------------+--------------------------------------------------------+
|user_5 |user_5 |hashforuser5 |{retargeter1=true, retargeter2=true} |
|user_2 |user_2 |hashforuser2 |{retargeter1=false, retargeter2=false} |
|user_6 |user_6 |hashforuser6 |{retargeter1=false, retargeter2=false} |
|user_3 |user_3 |hashforuser3 |{retargeter1=true, retargeter2=true} |
|user_10 |user_10 |hashforuser10 |{retargeter1=false, retargeter2=false} |
Limit Reached
With the stream and table in place, we are ready for the join—just like in the tutorial.
We join the two topics on the key columns that contain the customer IDs. We take most data from customer_consents and only the email address from customer_accounts.
SELECT customer_consents.key_customerid AS key_customerid,
customer_consents.customerId,
customer_consents.hashedCustomerId,
customer_accounts.contactMailAddress AS contactMailAddress,
customer_consents.consents['retargeter2'] AS consentToRetargeter2
FROM customer_consents
LEFT JOIN customer_accounts ON customer_consents.key_customerid = customer_accounts.key_customerid
EMIT CHANGES LIMIT 10;
+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+
|KEY_CUSTOMERID |CUSTOMERID |HASHEDCUSTOMERID |CONTACTMAILADDRESS |CONSENTTORETARGETER2 |
+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+
|user_5 |user_5 |hashforuser5 |email_5 |true |
|user_6 |user_6 |hashforuser6 |email_6 |false |
|user_10 |user_10 |hashforuser10 |null |false |
|user_2 |user_2 |hashforuser2 |email_2 |false |
|user_3 |user_3 |hashforuser3 |email_3 |true |
|user_4 |user_4 |hashforuser4 |email_4 |false |
|user_7 |user_7 |hashforuser7 |email_7 |true |
|user_9 |user_9 |hashforuser9 |null |true |
|user_8 |user_8 |hashforuser8 |email_8 |false |
|user_1 |user_1 |hashforuser1 |email_1 |true |
That looks almost good—but where do the null values in the email addresses come from?
It turns out that the customer_accounts topic is incomplete. It does not contain any data for user_9 and user_10.
PRINT 'customer_accounts' FROM BEGINNING;
rowtime: 2021/06/13 15:20:46.399 Z, key: user_1, value: {"customerId": "user_1", "contactMailAddress": "email_1"}
rowtime: 2021/06/13 15:20:46.410 Z, key: user_2, value: {"customerId": "user_2", "contactMailAddress": "email_2"}
rowtime: 2021/06/13 15:20:46.411 Z, key: user_3, value: {"customerId": "user_3", "contactMailAddress": "email_3"}
rowtime: 2021/06/13 15:20:46.411 Z, key: user_4, value: {"customerId": "user_4", "contactMailAddress": "email_4"}
rowtime: 2021/06/13 15:20:46.411 Z, key: user_7, value: {"customerId": "user_7", "contactMailAddress": "email_7"}
rowtime: 2021/06/13 15:20:46.411 Z, key: user_5, value: {"customerId": "user_5", "contactMailAddress": "email_5"}
rowtime: 2021/06/13 15:20:46.411 Z, key: user_6, value: {"customerId": "user_6", "contactMailAddress": "email_6"}
rowtime: 2021/06/13 15:20:48.189 Z, key: user_8, value: {"customerId": "user_8", "contactMailAddress": "email_8"}
Lesson: Pay attention to data quality
Just because another team or department documented the schema to make it easy for others to use, does not mean that the data is necessarily complete and correct.
In this case, the data was not backfilled when the customer_accounts topic was created and we did not have all email addresses in Kafka. Otherwise, this almost worked—cool!
Let‘s fix the data with kcat
kcat is a popular tool to consume and produce Kafka messages from the command line.
We use kcat to produce a complete and correct set of email addresses to Kafka from a database dump.
cat contactmails_dump
user_1;"user1@example.com"
user_2;"user2@example.com"
user_3;"user3@example.com"
user_4;"user4@example.com"
user_5;"user5@example.com"
user_6;"user6@example.com"
user_7;"user7@example.com"
user_8;"user8@example.com"
user_9;"user9@example.com"
user_10;"user10@example.com"
First, we create a new topic philip.contactmails. I use my name as a prefix to make it clear that it's a temporary, personal topic that other teams should not use.
Then we use kcat to produce messages from the database dump. The command specifies the local broker with -b and the topic philip.contactmails with -t. We use the producer mode with -P, -K to use the separator ";" between key and value, and -l to produce one message per line in the file. The argument -T tells kcat to print every produced message to the console also.
kafka-topics --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 4 \
--config "cleanup.policy=compact" \
--topic philip.contactmails
kcat -b localhost:9092 -t philip.contactmails -P -K ";" -T -l contactmails_dump
user_1;"user1@example.com"
user_2;"user2@example.com"
user_3;"user3@example.com"
user_4;"user4@example.com"
user_5;"user5@example.com"
user_6;"user6@example.com"
user_7;"user7@example.com"
user_8;"user8@example.com"
user_9;"user9@example.com"
user_10;"user10@example.com"
We create a new ksqlDB table from the new topic. We use the argument wrap_single_value=false. The single value for the email address in the Kafka messages is not wrapped in a JSON object—it's just a string.
CREATE TABLE contact_mails_dump (key_customerid VARCHAR PRIMARY KEY, contactMailAddress VARCHAR)
WITH (kafka_topic='philip.contactmails', value_format='JSON', wrap_single_value=false);
SELECT * FROM contact_mails_dump EMIT CHANGES LIMIT 10;
+------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------+
|KEY_CUSTOMERID |CONTACTMAILADDRESS |
+------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------+
|user_4 |user4@example.com |
|user_6 |user6@example.com |
|user_5 |user5@example.com |
|user_7 |user7@example.com |
|user_2 |user2@example.com |
|user_9 |user9@example.com |
|user_1 |user1@example.com |
|user_3 |user3@example.com |
|user_8 |user8@example.com |
|user_10 |user10@example.com |
Limit Reached
We can see that the email addresses are now complete and correct in Kafka.
Failure to join
Let's try the join again!
SELECT customer_consents.key_customerid AS key_customerid,
customer_consents.customerId,
customer_consents.hashedCustomerId,
contact_mails_dump.contactMailAddress AS contactMailAddress,
customer_consents.consents['retargeter2'] AS consentToRetargeter2
FROM customer_consents
LEFT JOIN contact_mails_dump ON customer_consents.key_customerid = contact_mails_dump.key_customerid
EMIT CHANGES LIMIT 10;
+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+
|KEY_CUSTOMERID |CUSTOMERID |HASHEDCUSTOMERID |CONTACTMAILADDRESS |CONSENTTORETARGETER2 |
+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+
|user_1 |user_1 |hashforuser1 |null |true |
|user_8 |user_8 |hashforuser8 |null |false |
|user_2 |user_2 |hashforuser2 |null |false |
|user_3 |user_3 |hashforuser3 |null |true |
|user_4 |user_4 |hashforuser4 |null |false |
|user_7 |user_7 |hashforuser7 |null |true |
|user_9 |user_9 |hashforuser9 |null |true |
|user_5 |user_5 |hashforuser5 |null |true |
|user_6 |user_6 |hashforuser6 |null |false |
|user_10 |user_10 |hashforuser10 |null |false |
Limit Reached
Hmm, that's worse than before—all nulls!
Now what? Let's debug the join.
Debugging co-partitioning with kcat
To join two topics with a stream–table join, the two topics need to be co-partitioned. This means the two topics need to use the same message keys, the same number of partitions, and every key needs to be in the same partition for both topics.
Comparing message keys
First, let's check that the two topics use the same keys.
We expect the keys to contain only the customer IDs as plain text without any other data like schema information. Avro values, for example, would contain bytes that are not visible when simply printing the messages, so we have to look closely.
We use kcat to analyze the message keys.
We call kcat for both topics—this time in consumer mode with -C. We only consume the first message with -c1 and use the flag -f to specify the format '%k'—we only want to output the keys. We pipe the result to hexdump to look at the bytes in the message key. That way, we can see invisible characters.
Using an ASCII converter as a sanity check, we can verify that the keys in both topics contain just the customer IDs.
kcat -b localhost:9092 -t philip.contactmails -C -c1 -f '%k' | hexdump -C
00000000 75 73 65 72 5f 31 |user_1|
00000006
kcat -b localhost:9092 -t customer_consents -C -c1 -f '%k' | hexdump -C
00000000 75 73 65 72 5f 38 |user_8|
00000006
echo 75 73 65 72 5f 31 | xxd -r -p
user_1
echo 75 73 65 72 5f 38 | xxd -r -p
user_8
The keys check out for both topics.
For an example with invisible differences between values, see Robin Moffatt’s blog post Why JSON isn’t the same as JSON Schema in Kafka Connect converters and ksqlDB.
Comparing partitions
Let's check whether all message keys—the customer IDs—end up in the same partitions in both topics.
Once again we use kcat. This time, to find out in which partitions the keys end up.
We use kcat in consumer mode with the format '%k,%p\n'. For every message, we print the message key and the partition on one line. We store the output in CSV files.
We use the sort command to sort the files by the customer ID.
kcat -b localhost:9092 -t philip.contactmails -C -f '%k,%p\n' > partitioning_contactmails.csv
kcat -b localhost:9092 -t customer_consents -C -f '%k,%p\n' > partitioning_consents.csv
sort -t , -k 1,1 partitioning_contactmails.csv > partitioning_contactmails_sorted.csv
sort -t , -k 1,1 partitioning_consents.csv > partitioning_consents_sorted.csv
cat partitioning_contactmails_sorted.csv
user_1,0
user_10,0
user_2,2
user_3,0
user_4,3
user_5,1
user_6,3
user_7,1
user_8,0
user_9,2
cat partitioning_consents_sorted.csv
user_1,3
user_10,1
user_2,2
user_3,2
user_4,2
user_5,1
user_6,1
user_7,2
user_8,0
user_9,2
We can see that the partitions don't match. The key user_1 is in partition 0 for the contactmails topic and in partition 3 for the consents topic. The co-partitioning is broken!
It turns out kcat does not use the same default partitioner as other Kafka clients. It is based on librdkafka, which uses a "consistent_random" partitioner by default.
Fixing the co-partitioning
We can use the default partitioner of the Java clients with kcat, too. We have to explicitly specify the partitioner "murmur2_random".
Let's produce the contactmail messages again to a clean topic with the right partitioner.
kafka-topics --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 4 \
--config "cleanup.policy=compact" \
--topic philip.contactmailsWithCorrectPartitions
kcat -X topic.partitioner=murmur2_random -b localhost:9092 -t philip.contactmailsWithCorrectPartitions -P -K ";" -z lz4 -T -l contactmails_dump
Now we can verify that the keys are now in the same partitions for both topics.
We use kcat to get the key–partition pairs for the new topic and then sort by customer ID.
We use the join command to join the partitioning files for both topics on the customer ID.
Each line contains the customer ID key followed by the partition in the contactmails topic and the partition in the consents topic.
kcat -b localhost:9092 -t philip.contactmailsWithCorrectPartitions -C -e -f '%k,%p\n' > partitioning_contactmails_correctpartitions.csv
sort -t , -k 1,1 partitioning_contactmails_correctpartitions.csv > partitioning_contactmails_correctpartitions_sorted.csv
join -t , -1 1 -2 1 partitioning_contactmails_correctpartitions_sorted.csv partitioning_consents_sorted.csv > partitioning_joined.csv
cat partitioning_joined.csv
user_1,3,3
user_10,1,1
user_2,2,2
user_3,2,2
user_4,2,2
user_5,1,1
user_6,1,1
user_7,2,2
user_8,0,0
user_9,2,2
We can easily verify that the partitions match for every key. The topics are co-partitioned!
Lesson: kcat is powerful and versatile, but keep the partitioner in mind
We witnessed how powerful and helpful kcat can be. We used it both to analyze message keys and the partitioning.
Just keep in mind that you probably want to use the murmur2_random partitioner when producing with kcat.
Failure to join, part 2: Still nothing
Let's try the join once more.
CREATE TABLE contact_mails_dump_correct (key_customerid VARCHAR PRIMARY KEY, contactMailAddress VARCHAR)
WITH (kafka_topic='philip.contactmailsWithCorrectPartitions', value_format='JSON', wrap_single_value=false);
SELECT customer_consents.key_customerid AS key_customerid,
customer_consents.customerId,
customer_consents.hashedCustomerId,
contact_mails_dump_correct.contactMailAddress AS contactMailAddress,
customer_consents.consents['retargeter2'] AS consentToRetargeter2
FROM customer_consents
LEFT JOIN contact_mails_dump_correct ON customer_consents.key_customerid = contact_mails_dump_correct.key_customerid
EMIT CHANGES LIMIT 10;
+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+
|KEY_CUSTOMERID |CUSTOMERID |HASHEDCUSTOMERID |CONTACTMAILADDRESS |CONSENTTORETARGETER2 |
+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+
|user_1 |user_1 |hashforuser1 |null |true |
|user_8 |user_8 |hashforuser8 |null |false |
|user_5 |user_5 |hashforuser5 |null |true |
|user_6 |user_6 |hashforuser6 |null |false |
|user_10 |user_10 |hashforuser10 |null |false |
|user_2 |user_2 |hashforuser2 |null |false |
|user_3 |user_3 |hashforuser3 |null |true |
|user_4 |user_4 |hashforuser4 |null |false |
|user_7 |user_7 |hashforuser7 |null |true |
|user_9 |user_9 |hashforuser9 |null |true |
Limit Reached
That is still broken. We fixed the co-partitioning, but there is still something amiss.
Stream–table join semantics
To understand why the join still fails, we have to look at the join semantics in detail. Let’s look at the join on a timeline.

First, we see a message on the customer_accounts topic, that contains the email address for customer A. That is our table topic, so now we have one entry in the table—for customer ID A, we have the address alice@email.com.
Next comes a consent message for customer A on the customer_consents topic. For each new message on the stream, ksqlDB will look up the email address in the table and add it to the consent. In this case, ksqlDB will write a new message with the consent and email address for customer A to customer_consents_with_mail.
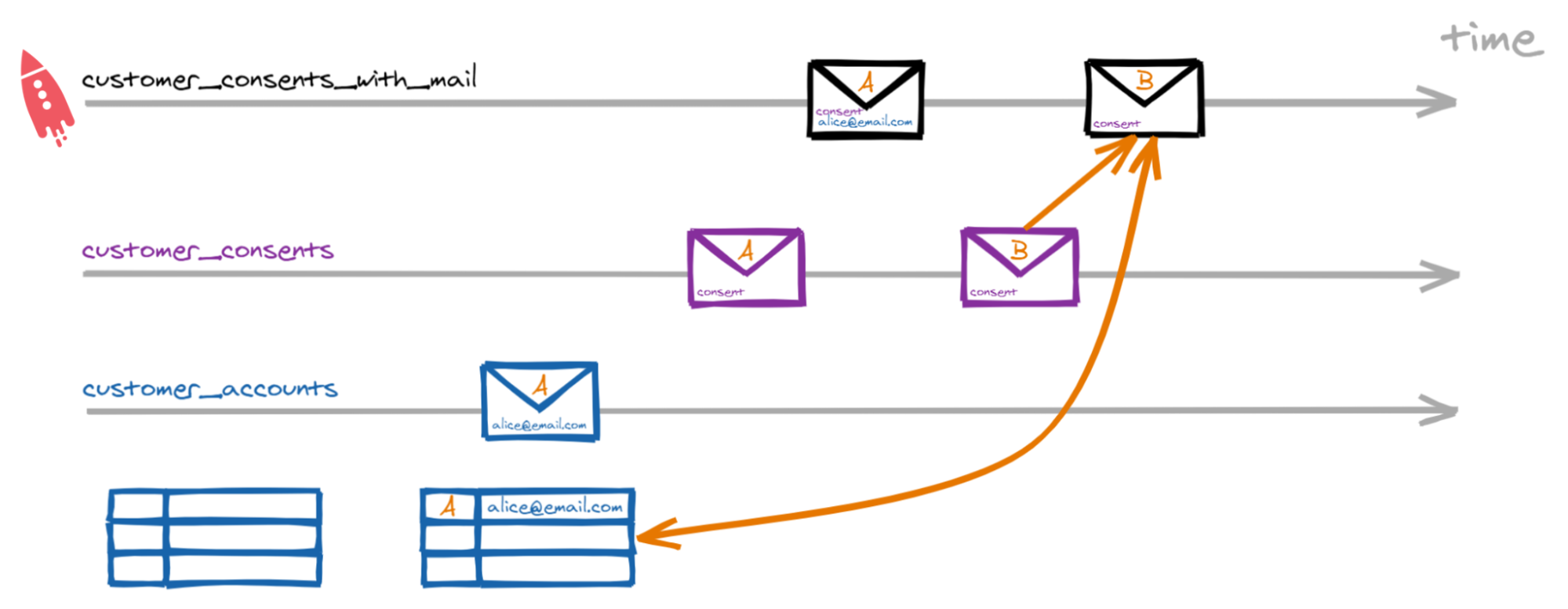
Now we get a consent message for customer B. Like before, ksqlDB will look up the email address in the table and add it to the consent. But the email address for customer B is not in the table yet. With a left join, ksqlDB will write a new message with the consent for customer B but without an email address.

Later, we get a new customer_accounts message for customer B and the table it updated. However, in a Stream–Table join, changes to the table will not trigger a new message.
That is what happened here!
When we produced the customer_accounts messages with kcat, all customer_accounts messages were produced after the consent messages. So when the consent messages streamed by, the table was still empty.
Lesson: Stream–table joins are temporal joins
We overlooked the join semantics by filling the table after the stream.
Ideally, we would have written the email addresses to the customer_accounts topic before all the consent messages. Then this would have worked.
During normal operations, we may be able to guarantee that the customer accounts message is written first. We would only send consent messages after the account is created. Then the stream–table join would be a great fit. In this case, we wrote the customer_accounts messages manually, however, so it did not work.
The fix
In the timeline above, we saw a customer_accounts message for user B at the end. At that time, the account data was there and the consent data was there, but there was no new joined message. In that case, it would have been helpful, if the customer_accounts message had also triggered a new message with data from both topics. That is what a Table–Table join can do.

In a Table–Table join, both topics are treated as tables, where the tables always contain the latest state. When a message arrives on either of the two topics, it is joined to the current state in the other table. In our case, this produces the desired message that has both the consent and the email address for customer B.
Let’s try it out.
We first create a new table from the consents topic. Then we perform a new join between both tables. In this case, we use a full outer join to also see the results, where either the consent or the email address is missing.
CREATE TABLE consents_table (key_customerid VARCHAR PRIMARY KEY)
WITH (kafka_topic='customer_consents', value_format='avro');
SELECT consents_table.key_customerid AS key_customerid,
consents_table.customerId,
consents_table.hashedCustomerId,
contact_mails_dump_correct.contactMailAddress,
consents_table.consents['retargeter2'] AS consentToRetargeter2
FROM consents_table
FULL OUTER JOIN contact_mails_dump_correct ON consents_table.key_customerid = contact_mails_dump_correct.key_customerid
EMIT CHANGES;
+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+
|KEY_CUSTOMERID |CUSTOMERID |HASHEDCUSTOMERID |CONTACTMAILADDRESS |CONSENTTORETARGETER2 |
+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+--------------------------------------------+
|user_2 |user_2 |hashforuser2 |null |false |
|user_3 |user_3 |hashforuser3 |null |true |
|user_4 |user_4 |hashforuser4 |null |false |
|user_7 |user_7 |hashforuser7 |null |true |
|user_9 |user_9 |hashforuser9 |null |true |
|user_8 |user_8 |hashforuser8 |null |false |
|user_2 |user_2 |hashforuser2 |user2@example.com |false |
|user_3 |user_3 |hashforuser3 |user3@example.com |true |
|user_4 |user_4 |hashforuser4 |user4@example.com |false |
|user_8 |user_8 |hashforuser8 |user8@example.com |false |
|user_7 |user_7 |hashforuser7 |user7@example.com |true |
|user_9 |user_9 |hashforuser9 |user9@example.com |true |
|user_1 |user_1 |hashforuser1 |null |true |
|user_1 |user_1 |hashforuser1 |user1@example.com |true |
|user_5 |user_5 |hashforuser5 |null |true |
|user_6 |user_6 |hashforuser6 |null |false |
|user_10 |user_10 |hashforuser10 |null |false |
|user_5 |user_5 |hashforuser5 |user5@example.com |true |
|user_6 |user_6 |hashforuser6 |user6@example.com |false |
|user_10 |user_10 |hashforuser10 |user10@example.com |false |
Due to the full outer join, we see some messages where the contact email address is null. In the end, however, the last message for each customer contains both the consent and the email address!
We have done it.
We added the email addresses to all consent messages. Now the Kafka Connect connector has all data to perform the explicit opt outs at the third-party retargeter.
Conclusion
Joining two topics to aggregate the data is one of the fundamental operations of stream processing. But that's not to say that it's simple. We have seen a number of things that can go wrong.
We have also seen just how versatile and powerful kcat can be. We used it to debug co-partitioning and make sure that two topics use the same keys in the same partitions.
We have learned that kcat uses a different partitioner by default than the Java clients and how to override it.
As a bonus, we also learned about the time semantics of stream–table joins!
If you want to keep learning more stream processing skills, try the free stream processing recipes on Confluent Developer! You can try popular use cases, brush up on basics, or get into advanced concepts.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.