Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Apache Kafka Goes 1.0
It has been seven years since we first set out to create the distributed streaming platform we know now as Apache Kafka®. Born initially as a highly scalable messaging system, Apache Kafka has evolved over the years into a full-fledged distributed streaming platform for publishing and subscribing, storing, and processing streaming data at scale and in real-time. Since we first open-sourced Apache Kafka, it has been broadly adopted at thousands of companies worldwide, including a third of the Fortune 500. While being adopted at those companies for mission-critical applications, Kafka has also matured at a steady pace, adding first replication and the ability to store keyed data indefinitely, then the Connect API for integrating Kafka easily with systems like MySQL and Elasticsearch, then the Streams API to enable native stream processing in Kafka for mission-critical real-time applications and event-driven microservices, and then this spring, exactly-once processing semantics. The feature set and the broad deployments all speak of a stable and Enterprise-ready product, which leads to an important step we are taking with this release: as of today, Apache Kafka is going 1.0!
And Kafka 1.0.0 is no mere bump of the version number. The Apache Kafka Project Management Committee and the broader Kafka community has packed a number of valuable enhancements into the release. Let me summarize a few of them:
- Since its introduction in version 0.10, the Streams API has become hugely popular among Kafka users, including the likes of Pinterest, Zalando, and The New York Times. In 1.0, the API continues to evolve at a healthy pace. To begin with, the builder API has been improved (KIP-120). A new API has been added to expose the state of active tasks at runtime (KIP-130). Debuggability gets easier with enhancements to the print() and writeAsText() methods (KIP-160). And if that’s not enough, check out KIP-138 and KIP-161 too. For more on streams, check out the Apache Kafka Streams documentation, including some helpful new tutorial videos.
- Operating Kafka at scale requires that the system remain observable, and to make that easier, we’ve made a number of improvements to metrics. These are too many to summarize without becoming tedious, but Connect metrics have been significantly improved (KIP-196), a litany of new health check metrics are now exposed (KIP-188), and we now have a global topic and partition count (KIP-168). (That last one sounds so simple, but you’ve wanted it in the past, haven’t you?) Check out KIP-164 and KIP-187 for even more.
- We now support Java 9, leading, significantly faster TLS and CRC32C implementations. Over-the-wire encryption will be faster now, which will keep Kafka fast and compute costs low when encryption is enabled.
- In keeping with the security theme, KIP-152 cleans up the error handling on Simple Authentication Security Layer (SASL) authentication attempts. Previously, some authentication error conditions were indistinguishable from broker failures and were not logged in a clear way. This is cleaner now.
- Kafka can now tolerate disk failures better. Historically, JBOD storage configurations have not been recommended, but the architecture has nevertheless been tempting: after all, why not rely on Kafka’s own replication mechanism to protect against storage failure rather than using RAID? With KIP-112, Kafka now handles disk failure more gracefully. A single disk failure in a JBOD broker will not bring the entire broker down; rather, the broker will continue serving any log files that remain on functioning disks.
- Since release 0.11.0, the idempotent producer (which is the producer used in the presence of a transaction, which of course is the producer we use for exactly-once processing) required max.in.flight.requests.per.connection to be equal to one. As anyone who has written or tested a wire protocol can attest, this put an upper bound on throughput. Thanks to KAFKA-5949, this can now be as large as five, relaxing the throughput constraint quite a bit.
As you can see, 1.0.0 is a significant release with real enhancements, but the number matters too. What does v1.0 mean for Apache Kafka? To answer that, let me take a step back and give you the backstory.
Apache Kafka v1.0: Completeness of our vision
People have asked us why it took so long for Apache Kafka to go 1.0. There isn’t a set of guidelines that measure when a project is ready to be 1.0, and every project has its own unique story. Usually the timeline has to do with stability or production readiness. For Apache Kafka, the wait for 1.0 was less about stability and more about completeness of the vision that we and the community set to build towards back when we originally created Kafka. After all, Kafka has been in production at thousands of companies for several years. In fact, the very reason for Kafka’s success and its broad adoption in the marketplace has been about its ease of use and stability in production; the “it just works” experience of using Kafka.
What do I mean by completeness? Back in 2009 when we first set out to build Kafka, we thought there should be an infrastructure platform for streams of data. We didn’t start with the idea of making our own software, but started by observing the gaps in the technologies available at the time and realized how they were insufficient to serve the needs of a data-driven organization. There were message queues that handled low-volume data in real-time and ETL tools that handled scalable data flow in a batch fashion. So, you had to make a tough choice. Pick real-time or pick scale, but not both easily. With the growing diversity of data that companies wanted to process beyond just database and log data, coupled with the increase in the number of downstream systems that needed access to all that data beyond just the data warehouse, the big question we asked ourselves was “why not both scale and real-time”? And more broadly, why not build a true infrastructure platform that allows you to build all of your applications on top of it, and have those applications handle streaming data by default.
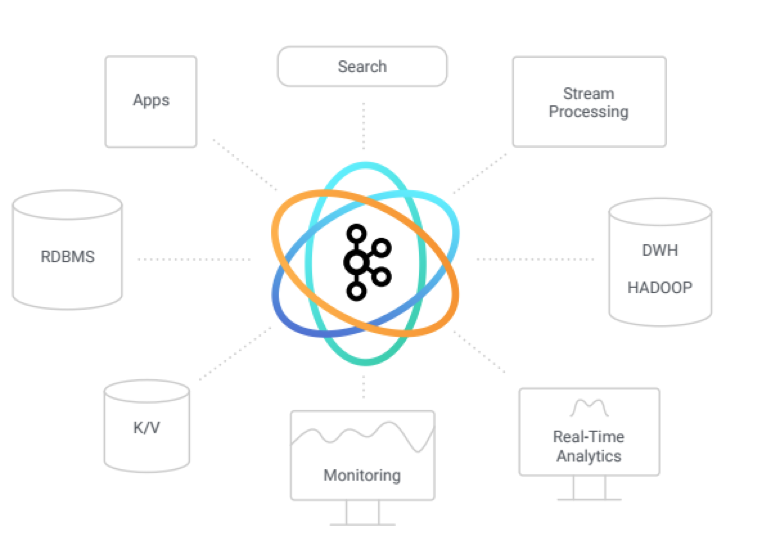
Kafka’s transformation from a Messaging System to a Streaming Platform
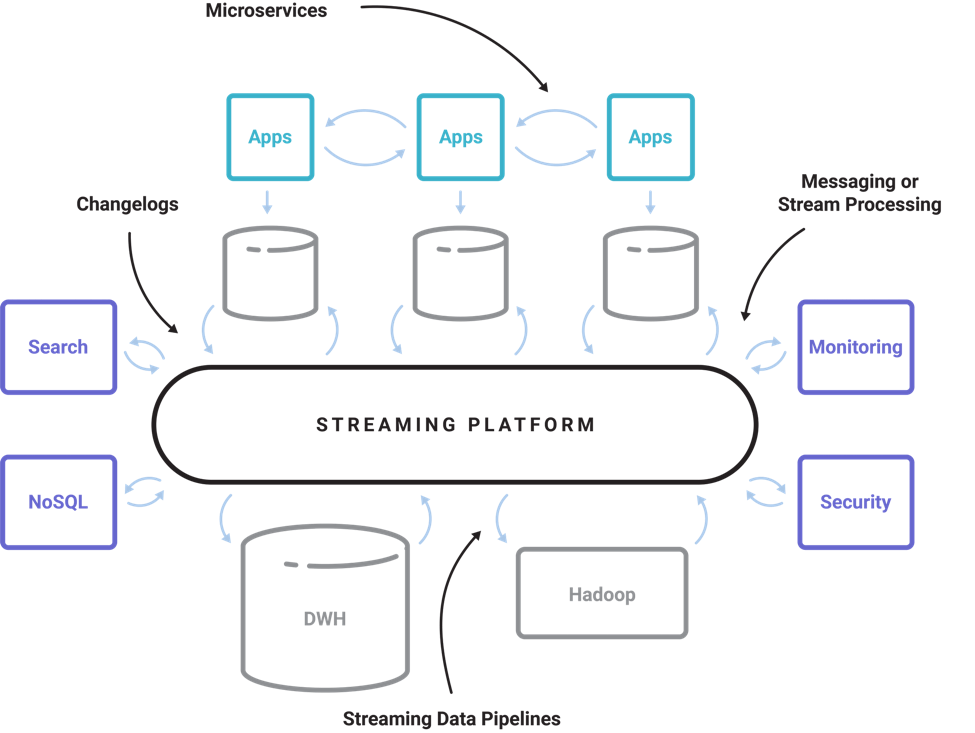
So we set out to build that infrastructure platform – a Streaming Platform; a real, modern distributed infrastructure platform for event streams. That didn’t happen in one big step, but as part of a multi-step transformation while getting people slowly onboard with this new way of thinking about all their data. When fully implemented, a streaming platform can grow into a central nervous system that connects all of your applications and services, databases, data centers, and SaaS footprint in real-time and at scale. That sounds grandiose, but today there are a lot of companies built that way now, using Apache Kafka, which is pretty cool. If you draw the architecture of a modern digital company today, it has a streaming platform at the center of it, the same way it has relational databases and the data warehouse.
But Kafka was born as a messaging system, right? Here is the history of how we went about building Kafka into what I think is a complete platform for streaming data. We actually started by thinking about stream “processing,” but then quickly realized that to make that real, you first need the ability to read, write and store streams of data so you can then process them. Talk about crawling, before walking! And we had data supporting this concern; there had been stream processing startups in the 00s but they had failed. Why? Well, because companies simply didn’t have most of the streams accessible for processing!
Step 1: Log-like abstraction for continuous streams
So the first step was to implement a log-like abstraction for continuous streams and the ability to run it at company-wide scale with pub-sub APIs. And though there was a lot of resistance from the JMS community, it turns out a log is actually a great abstraction for highly-scalable pub-sub messaging. The publish APIs or the writes are in the form of appends to this ordered log. And the subscription APIs are in the form of continuous reads from a starting offset defined by the end consumers. At this point, we resisted the urge to solve all of the replication and ordering problems in distributed systems, and just focussed on making the most scalable log-backed messaging system out there.
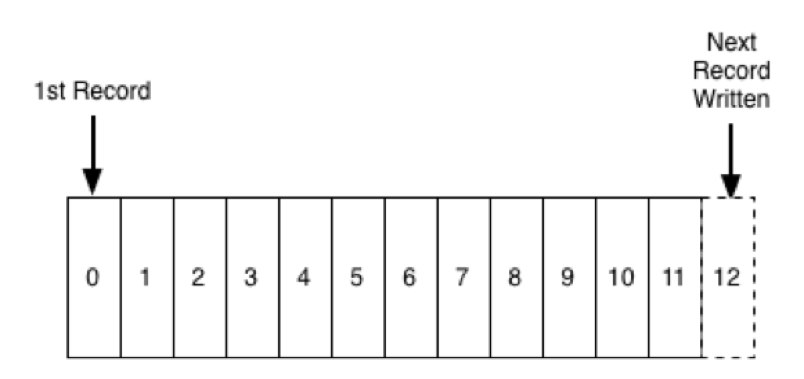
Step 2: Replicated and fault tolerant log; a store for streams of data
Next, we made Kafka fault-tolerant and built replication into it, so that it could be depended on as a data store, not just as a transient queue. The importance of data stream storage is often missed and back then it was not even a consideration. However, the ability to store streams of data is critical for stream processing to work in practice. The simple mechanics of reprocessing a stream when your app is deployed means that you must have a certain window of data lying around in the log for an app to access and reprocess data from. We even made up a somewhat tongue-in-cheek term “Kappa Architecture” to refer to this capability.
To enable the Kappa Architecture, we enabled compacted topics; a sleeper feature, which most people didn’t get at first. But it is a big deal; it let us have an immutable event stream representation of tables of mutable data that continually evolve. Similar to how a traditional database is built under the covers, the redo or transaction log is the source of truth and is compacted, while the tables are an evolving projection over this log of the latest values. This was the first step towards creating the core abstractions of stream processing – “streams” and “tables.” Streams represent a series of facts about what’s happening in the world and tables represent the current state of the world. These abstractions are at the heart of stream processing and enable a whole new set of streaming applications. You can join together pure event streams with tables, or you can subscribe to these evolving tables and process them to create “materialized views” that are continually updated.
Step 3: Connect and Streams APIs
The next step was to build APIs that made it easy to get data in and out of Kafka and process it. Our goal was to make it easy to build streaming data pipelines with Kafka, so you can then process those streams no matter where they originated from. The Connect API allows you to build streaming data pipelines by plugging various source connectors to get data from external systems into Kafka and sink connectors to get data out of Kafka into external systems. Today, there are several dozens of connectors available out there that you can use. If the Connect API is for building streaming data pipelines, the Streams API is for processing them. We built the Streams API as a powerful library that you can embed in your applications to process Kafka streams in place. The underlying motivation was to enable all your applications to do stream processing without the operational complexity of running and maintaining yet another cluster. As a result of that simplicity, a number of companies have put the Streams API into practice for stream processing applications.
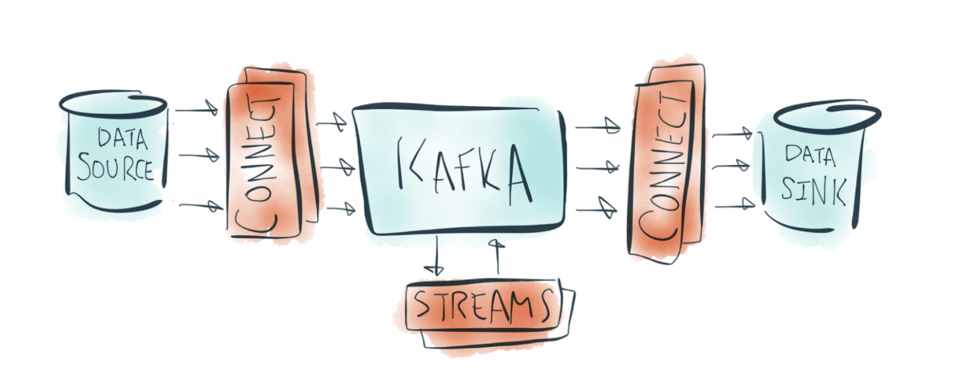
Step 4: A foundational protocol for exactly-once stream processing
More recently, we added transactions to Apache Kafka to enable exactly-once semantics for stream processing. This is a really fundamental thing that gives a kind of “closure property” for streaming transformations, making it really easy to build scalable, fault-tolerant, stateful stream processing applications that process event streams *and* have these get correct results.
The nice thing about all this is that while the current instantiation of Kafka’s Streams APIs are in the form of Java libraries, it isn’t limited to Java per se. Kafka’s support for stream processing is primarily a protocol-level capability that can be represented in any language. This is an important distinction. Stream processing isn’t one interface, so there is no restriction for it to be available as a Java library alone. There are many ways to express continual programs: SQL, function-as-a-service or collection-like DSLs in many programming languages. A foundational protocol is the right way to address this diversity in applications around an infrastructure platform.
Apache Kafka: An entire ecosystem around streams of data
Success of an infrastructure platform lies not just in the platform itself but in the broader ecosystem that it gives birth to. We want Apache Kafka to support a rich ecosystem of pub-sub libraries, connectors, stream processing interfaces, beyond what we could ever build in a single project. This is what we have today and what is growing and thriving as part of the broader Kafka community.
“So that is the vision we had in mind and what we set out to build towards – a Streaming Platform; the ability to read, write, move and process streams of data with transactional correctness at company-wide scale.”
It took us nearly a decade to turn this vision into reality and we are not done yet. From Kafka’s broad adoption in the world, it is clear to me that this Streaming Platform is going to be as big and central of a data platform as relational databases are.
With this release, the Apache Kafka Project Management Committee is acknowledging that Kafka has truly become a stable, mature, and enterprise-ready Streaming Platform poised to continue serving users faithfully and evolving as stream processing plays a first-class role in enabling a central nervous system for all companies worldwide. I am very excited for the progress we have made so far and I’m looking forward to the next seven years of what the Apache Kafka community, my fellow committers, and the ever-growing list of Kafka fans and users can do with this platform, and I am humbled to be a part of the process.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...